
上文《ClickHouse进阶系列(一)clickhouse副本介绍》我们介绍了在clickhouse里面创建普通的副本,这里我们来介绍下clickhouse的分片,我们利用分片可以更方便的创建副本(不需要在多个集群节点上挨个创建表)。
这里的clickhouse分片的意思是把一张表的数据通过hash分成几份,可以理解为传统数据库里面的横向分表。假设users的数据集有300条,在原来的表里面是把这300条数据存储在一张表的一份存储文件里面的,现在是把这300条数据存储在一张表的3份存储文件里面的(假设分片设置为3)。这样子在查询的时候极大的减少了数据的扫描范围。
在clickhouse里面,分片与我们在集群里面的配置文件:/etc/clickhouse-server/config.d/metrika.xml这个配置文件相关的,这里我们自定义配置的集群,如下图:
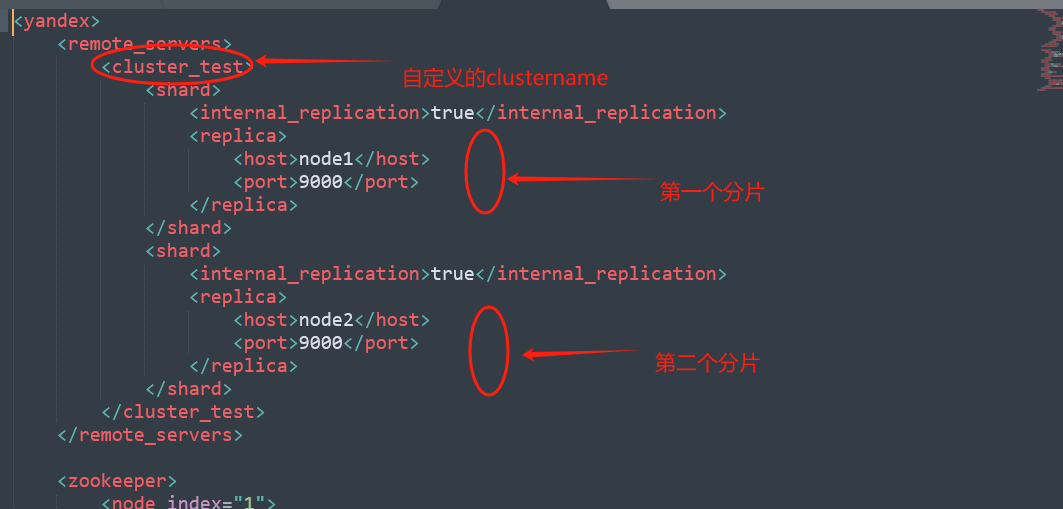
像上图我们配置了一个集群:cluster_test,然后这个集群由2个分片组成:两个<shard>组成,每个分片里面只有1个副本:每个shard里面只有一个replica。
此时的话,我们在当前cluster_test集群里面创建表的话,name他就会有2个分片,1个副本(主存储数据片,没有额外的数据片),下面我们演示一下创建一张users1表:
#创建一张users1表
create table test.users1 on cluster cluster_test(
id int,
name String,
age int
)engine = ReplicatedMergeTree('/tables/{shard}/users1','{replica}')
order by id;
创建完成之后,我们就可以看到两个节点上都有名称为users1的表了。
备注:
1、创建分片表的时候,我们添加上on cluster xxx来创建,此时他会自动寻找集群的节点执行create table的操作。
2、在创建的时候我们指定zk路径的时候这里有一个{shard}主要是占位符,也就是代表在/etc/clickhouse-server/config.d/metrika.xml中配置的节点,他会自动去寻找: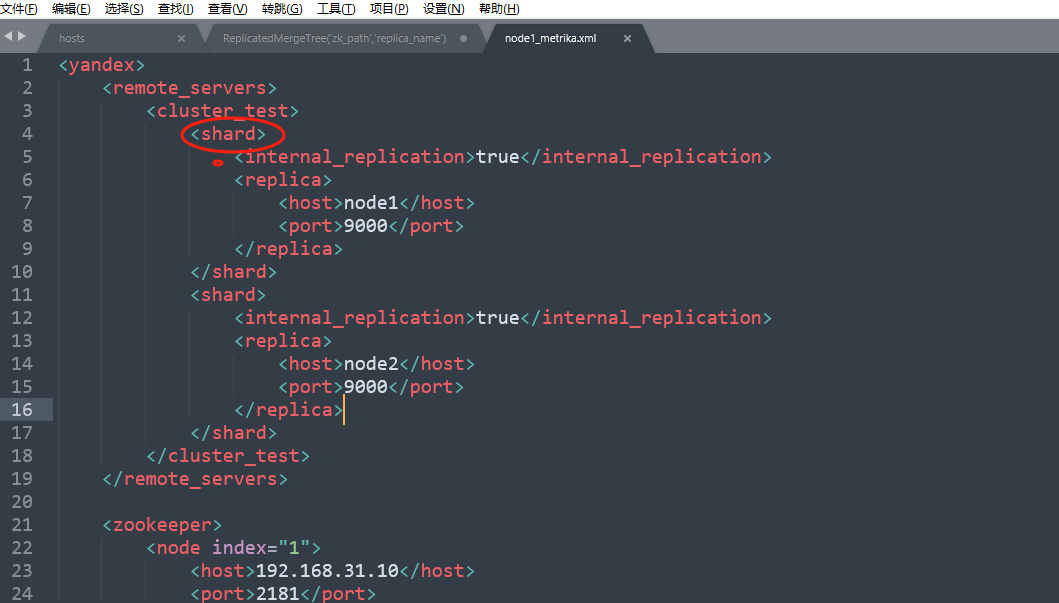
3、在zk路径的话,我们还指定了{replica}这个也是在/etc/clickhouse-server/config.d/metrika.xml中配置的节点,他会自动寻找:
4、日常使用过程中,我们一般都直接使用占位符来定义。 5、在zk里面我们可以看到他已经把占位符替换掉了:

以上我们完成了users1表的分片创建,接下来我们向表中插入数据,这里需要注意的地方就是,clickhouse如果在node1节点上向users1表插入数据,name在node1的节点上查询的users1表的数据只会是node1上保存的数据,不会有node2上保存的数据,也就是在哪个节点插入数据,name在哪个节点查询数据就是当前节点保存的数据,此数据只是user1整个表的一部分。下面举个例子
#在节点1插入用户为张三的数据: insert into test.users1 values(1,'张三',15); #在节点1查询users1表的数据 select * from test.users1;
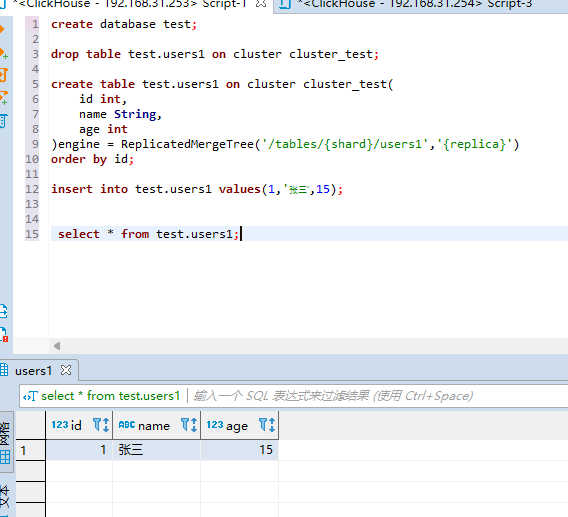
可以看到查询的是在当前节点插入的张三的数据。
#在节点2插入用户为李四的数据: insert into test.users1 values(2,'李四',16); #在节点1查询users1表的数据 select * from test.users1;
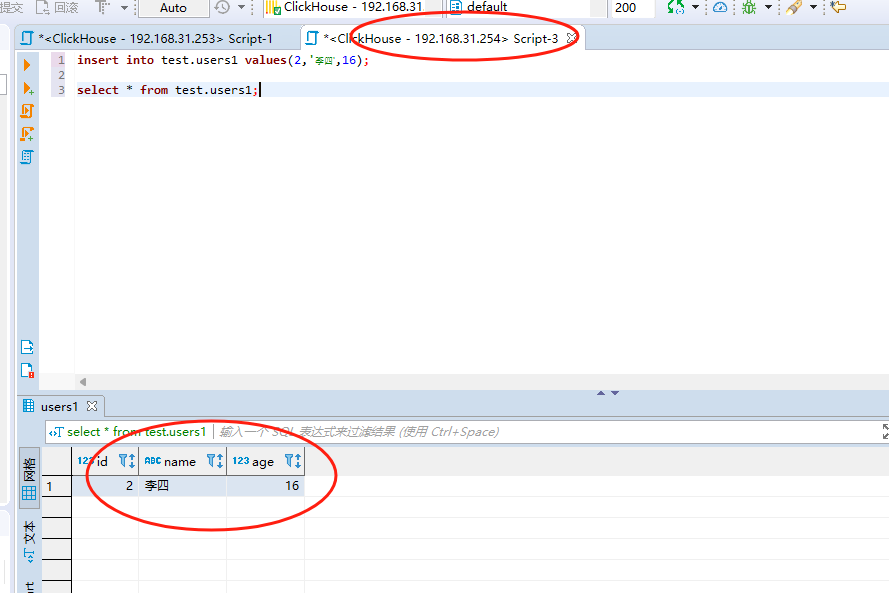
这里的话,我们在node2节点看到的数据只有李四的数据,没有张三的数据。
以上就是关于clickhouse在集群里面创建分片的案例。
备注
1、这里我们创建的分片只有1个副本,如果想要多副本怎么样,例如两个,name我们就需要准备4个节点的clickhouse集群,并且在/etc/clickhouse-server/config.d/metrika.xml文件中每一个shard配置两个replica,例如:
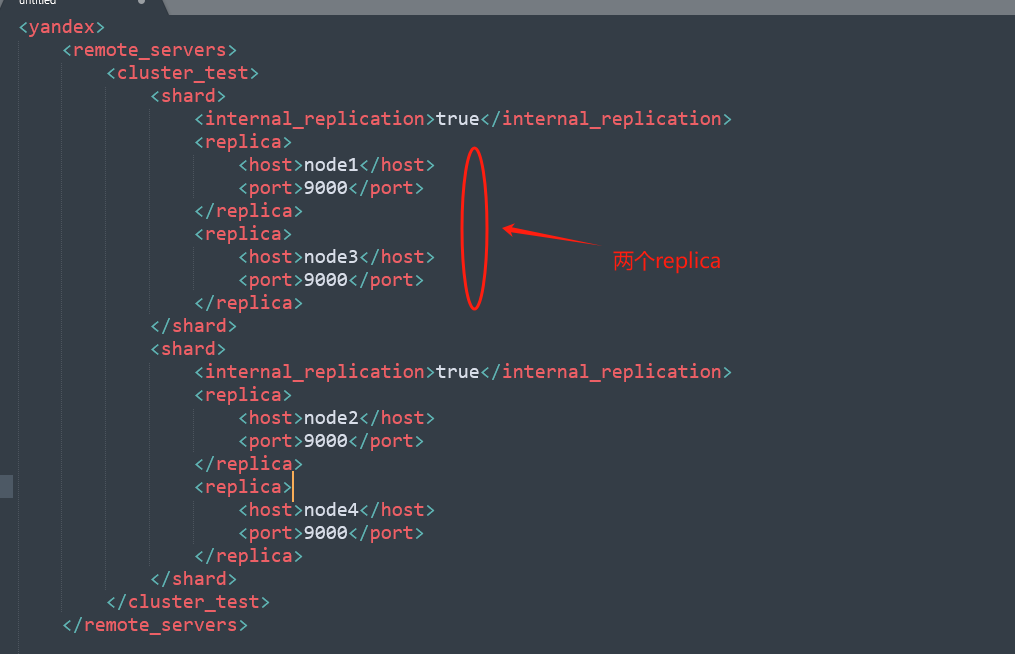
2、在/etc/clickhouse-server/config.d/metrika.xml文件中每一个节点只能有一个标识,不能把某个节点标记为多个标识,例如:
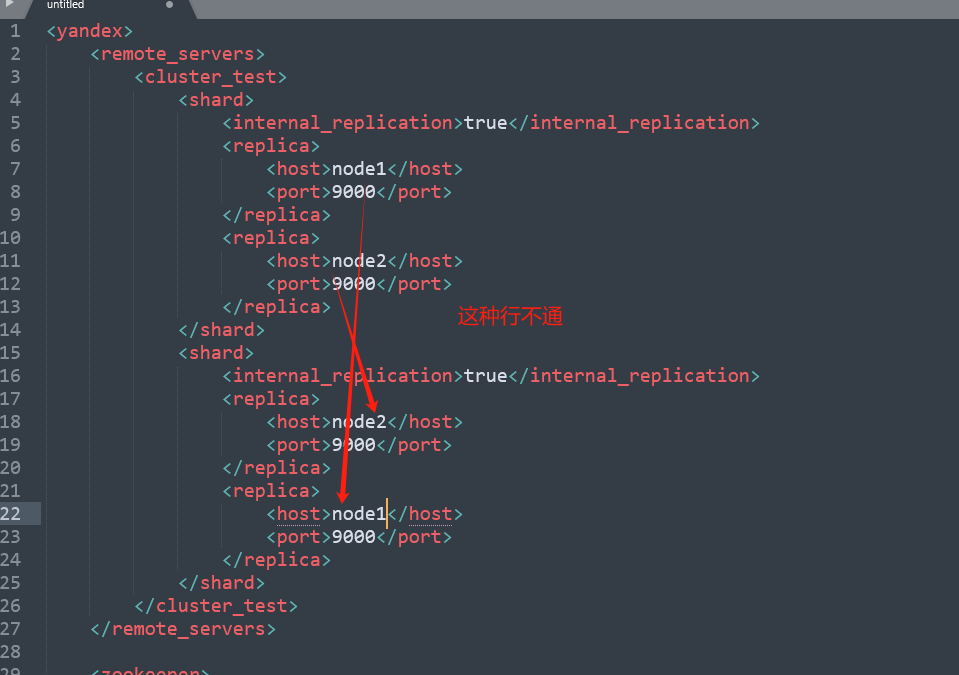
3、上面我们看到在不同的节点只能查询当前节点部分的数据,那么如何查询所有数据呢?这里就要使用前面提到的distributed了,详见:《ClickHouse基础系列(九)ClickHouse表引擎之Special系列》中的distributed部分,下一篇文章我们也会更深入的介绍下dristibuted引擎。








还没有评论,来说两句吧...