
在clickhouse里面他没有目前流行的doris这样自动的去创建路由的功能。所以在查询的时候就很麻烦,由于同一张表不同的数据存储在不同的节点上,就只能在当前节点查询当前存储的数据。
既然没有自动去创建路由,那么就手动的去创建路由吧,所以在clickhouse里面新增了一张Distributed引擎的概念。他相当于把集群内不同节点上的同一张表的数据创建了一个逻辑路由表,然后我们想要查询数据的话直接向这张逻辑路由表进行查询即可。
像上文我们创建了名称为users1的路由表,我们分别在两个节点上插入了数据,示例如下:
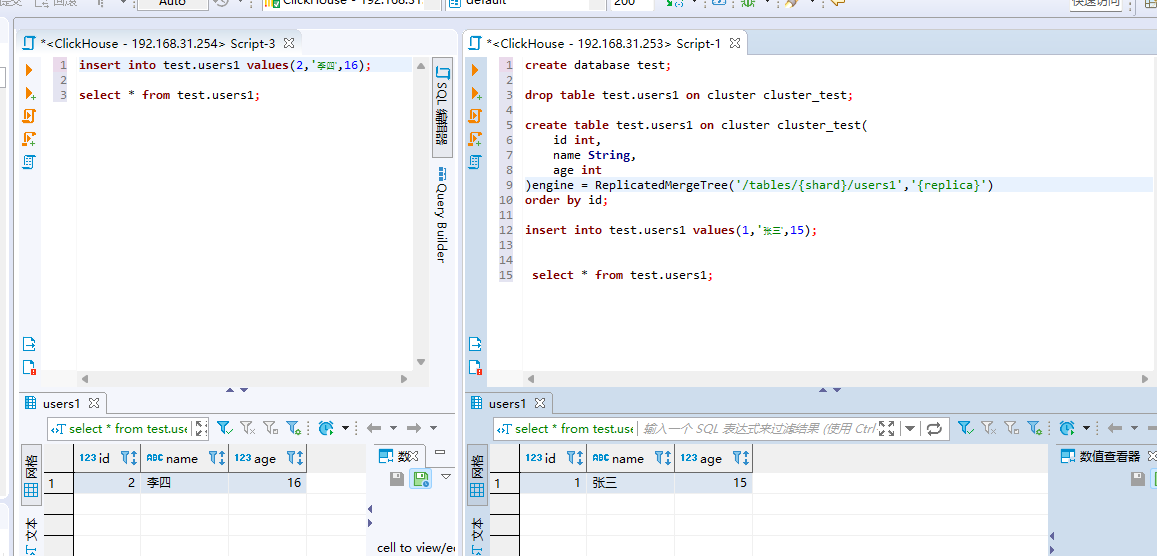
此时我们想要从users1表中查询所有的数据,那么就创建一张路由表即可,示例如下:
Create table test.users1_route on cluster cluster_test ( id UInt32, name String, age UInt32 )engine = Distributed(cluster_test,test,users1,id);
创建成功之后,我们就可以在任意节点查询这张users1_route的路由表了,示例图如下:
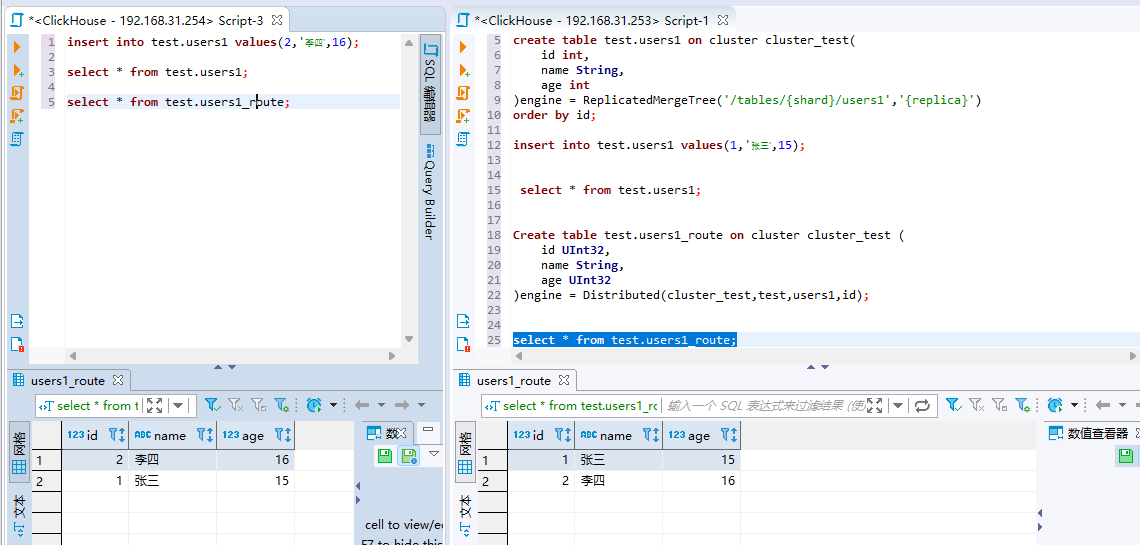
可以看到我们查询出来了所有的数据。
关于Distributed引擎
这里的Distributed引擎创建表的时候一定要注意语法,示例如下:
create table xxx on cluster [cluster_name] Distributed(cluster_name, database_name, table_name[, sharding_key])
这里的重点是:
1、使用on cluster [cluster_name],代表把表创建到整个集群里面,让任意一台节点都可以查询这个表。 2、Distributed里面的参数分别为:需要路由的子表所在集群,需要路由的子表所在数据库,需要路由的子表的表名,需要路由的子表的分片字段(一般为主键) 3、Distributed不仅满足从子表中查询数据,还满足向子表中插入数据,当插入数据的话,会根据分片把数据插入到对应的节点上去,示例如下:
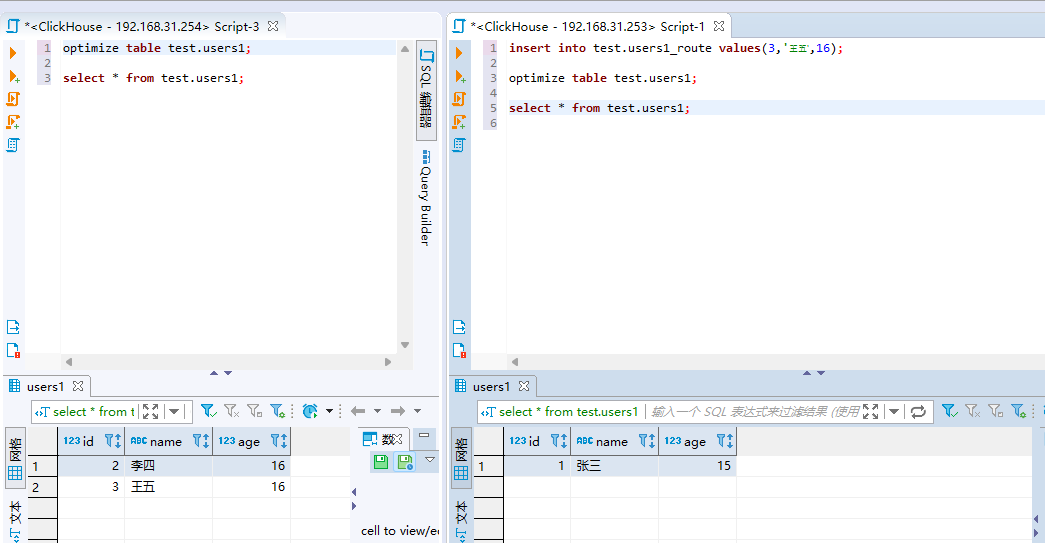
4、这里需要注意下,如果是向路由表插入数据的话,数据还没合并,所以看不到具体数据存储在哪个节点,所以我们可以等待15分钟左右的自动合并,也可以在每一个节点上执行optimize table合并表,就可以看到数据了。
以上就是关于Distributed引擎的相关介绍。








还没有评论,来说两句吧...