
上文《数据湖系列(二十)Iceberg+hive整合外部表使用案例》我们介绍了直接使用hive对于Iceberg的操作,本文的话我们来演示下使用Spark对Iceberg的操作。
对于spark操作Iceberg来说,主要的增删改查的实现方式还是借助sparksql的方式来进行,但是需要注意的一点,在插入的时候有两种方式,分别是:
1、直接向hdfs上插入数据。 2、直接向hive中插入数据。
本文的话我们演示直接向hdfs中插入数据。由于spark操作iceberg比较简单,所以我们直接上核心代码。
val spark: SparkSession = SparkSession.builder().master("local").appName("InsertIceberg")
//指定hadoop catalog,catalog名称为test1
.config("spark.sql.catalog.test1", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.test1.type", "hadoop")
.config("spark.sql.catalog.test1.warehouse", "hdfs://node1:9000/spark_iceberg")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.getOrCreate()
//创建一张表users的表,注意这里相关表的地方要写全路径,格式为:${多数据源目录}.${库名}.{表名}
spark.sql(
"""
|create table test1.default.users (id int,name string,age int) using iceberg
""".stripMargin)
//接着我们向上面创建的users表添加两条示例数据,注意这里相关表的地方要写全路径,格式为:${多数据源目录}.${库名}.{表名}
spark.sql(
"""
|insert into test1.default.users values (1,"张三",18),(2,"李四",19)
""".stripMargin)
//最后我们查询刚才向users表里面创建的示例数据。
spark.sql(
"""
|select * from test1.default.users;
""".stripMargin).show()以上的代码是不是很简单。但是需要注意几个地方:
1、在spark conf里面一定要指定相关的catalog的配置,这里涉及到的配置格式是:
spark.sql.catalog.${catalog_name}
spark.sql.catalog.${catalog_name}.type
spark.sql.catalog.${catalog_name}.warehouse
这几个相关的配置值一般都是固定的,按照示例代码直接照抄即可。
2、上诉3个配置是必须要写的。最后我们运行测试下,示例结果图如下:
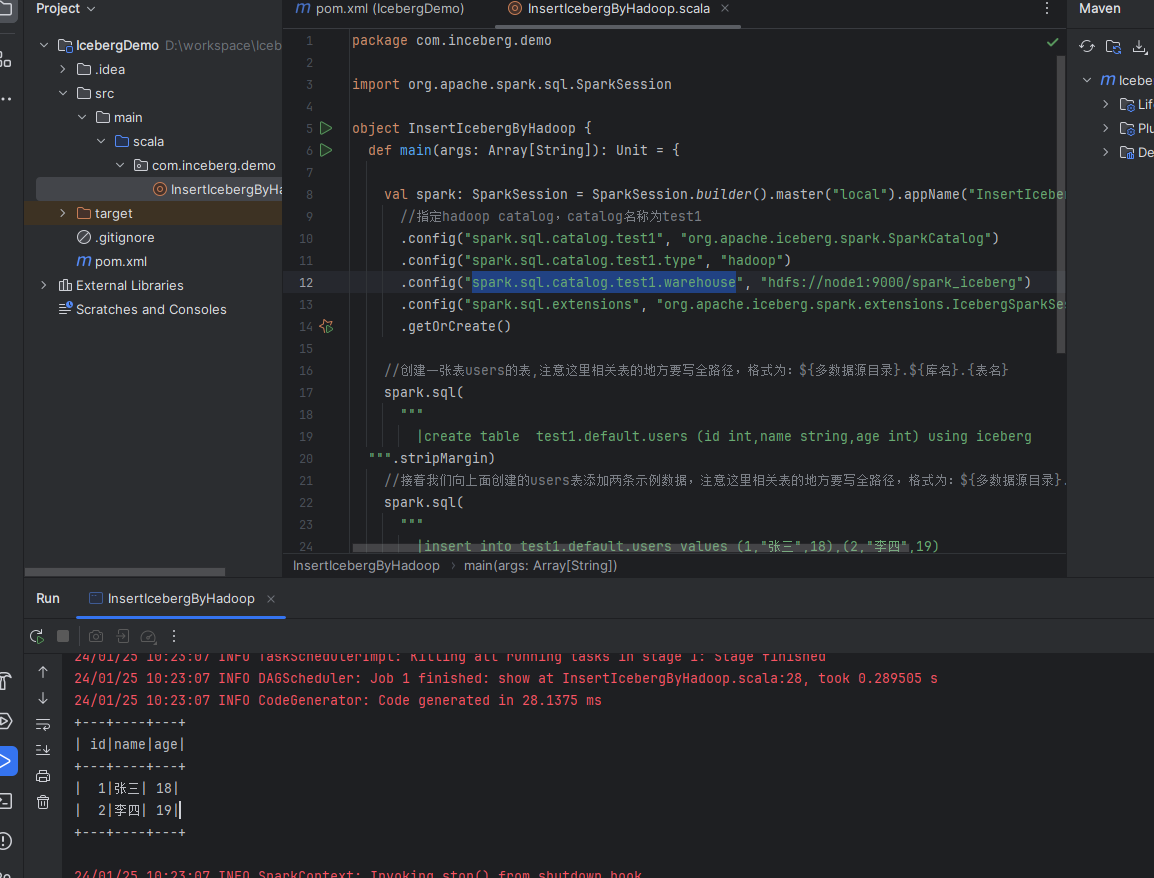
可以看到我们使用spark sql完整的执行了表的创建,插入,查询操作。
备注1:
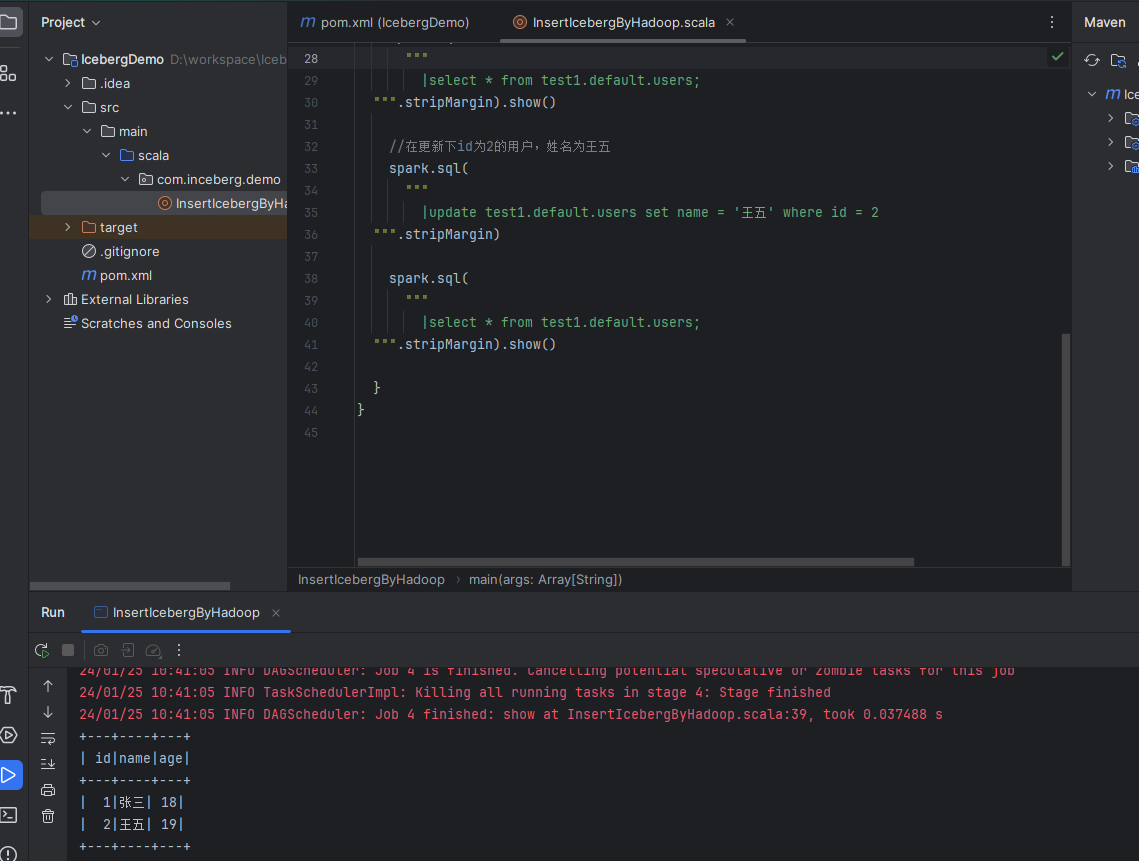
1、这里没有演示更新操作,这个熟悉spark sql的同学都应该知道,直接使用update相关的sql语句即可。相关的案例可以直接查看本案例源码。示例效果图如下:
备注2:
1、这里如果创建表的时候涉及到分区,那么创建语句示例如下:create table if not exists test1.default.users(id int,name string,age int,loc string) using iceberg partitioned by (loc) 2、创建分区的时候,还可以使用函数进行转换,例如:create table if not exists test1.default.users(id int,name string,age int,loc string,cts timestamp) using iceberg partitioned by (years(cts)) 3、如果使用上诉2的函数形式创建分区,那么在插入数据的时候需要进行转换一下,示例:insert into test1.default.users values (1,'张三',18,cast(1706152578 as timestamp)),这个转换主要是我们使用timstamp,传递进来的是时间戳,所以需要cast转换一下。 4、iceberg还支持使用create table xxx as select的方式创建表,示例如下: create table test1.default.users2 using iceberg as select id,name,age from test1.default.users1; 5、iceberg还支持使用replace table xxx as select的方式替换表,有时候我们创建的表数据有问题,那么我们可以重建数据,这时就直接使用replace table即可,示例如下:replace table test1.default.users2 using iceberg as select id,name,age from test1.default.users1;
以上就是spark直接向hdfs写入iceberg数据的案例,最后附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...