
前面我们演示了spark写入iceberg数据的问题,这里的话我们进入实战的阶段。在实际的过程中,我们经常会涉及到实时流的方式把数据写入到iceberg的需求,整体流程如下:
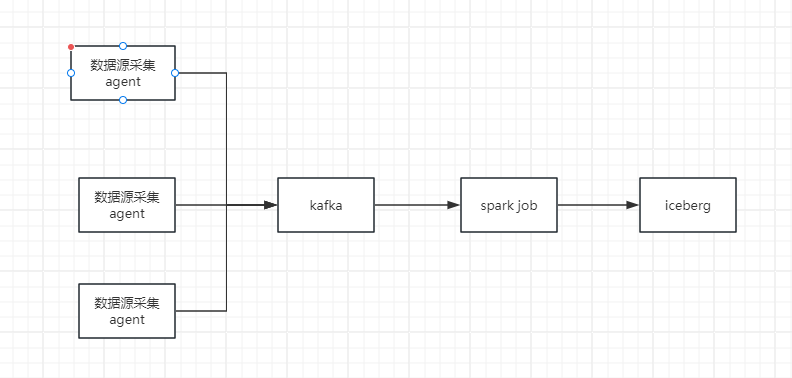
这里我们使用spark的方式来演示下这里的整个流程。
一、准备kafka
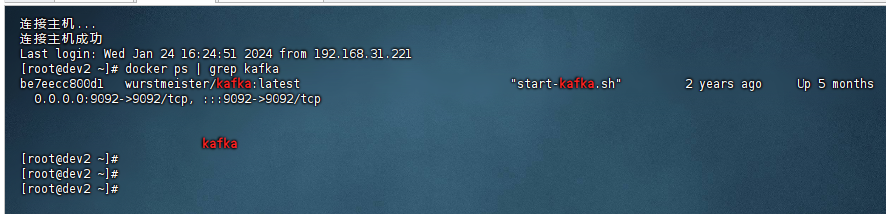
这里首先我们需要部署一套kafka环境,关于kafka环境的部署,可参考:《使用docker快速在服务器上搭建一套kafka环境》。这里我已经准备好了一套kafka环境:
二、编写kafka生产者
这里由于编写spark程序的时候,比较喜欢使用scala语言,所以这里我们使用scala的方式来编写一个生产者,示例代码如下:
1)首先我们创建一个生成数据的模块,示例代码如下:
def generatorUserInfo() = {
val user = new StringBuffer("")
user.append(1).append("\t").append("张三").append("\t").append(15)
user.toString()
}这个方法主要是生成生产者采集的模拟数据。
2)接着我们编写发送模拟数据的核心代码:
//调用生成数据,产生信息
val content: String = generatorUserInfo()
//模拟循环发送1000次
for( i <- 1 to 1000){
producer.send(new ProducerRecord[String, String]("ttest1", content))
}完成后我们把代码执行一下,就可以看到数据发送到mq了:
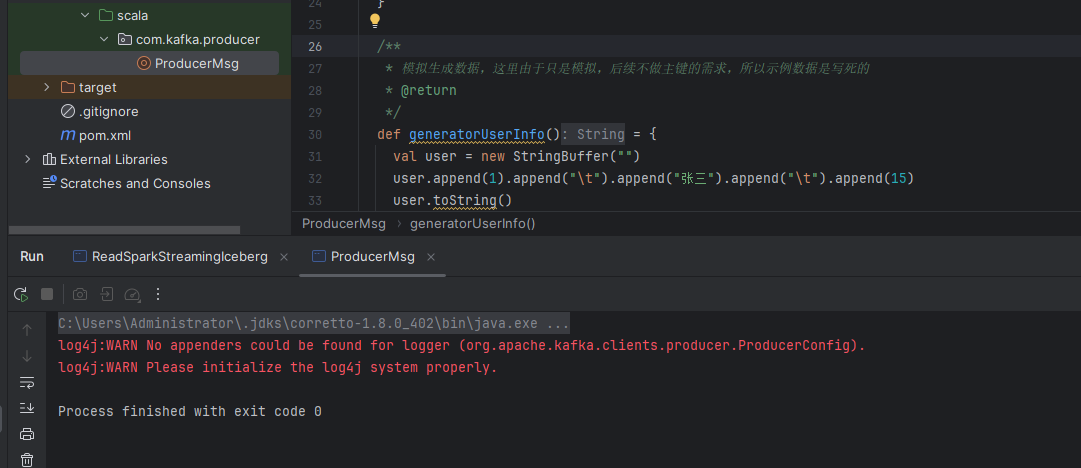
备注:
1、这里的数据我们首先使用的text的方式,每一个字段使用\t分隔符进行分割。 2、这里我们的核心字段主要是:id,name,age
三、编写spark消费者
前面生产者我们已经产生了数据,接着就要编写spark消费kafka的数据的方式,整个的流程是:
1、初始化创建表 2、读取kafka的数据 3、根据规则提取每一条的id,name,age字段 4、把数据流式的写入到iceberg中
所以这里核心的代码是:
spark.sql(
"""
|create table if not exists test2.default.users (
| id string,
| name string,
| age string
|) using iceberg
""".stripMargin)
val transDF: DataFrame = lineDF.withColumn("id",split(col("data"), "\t")(0))
.withColumn("name", split(col("data"), "\t")(1))
.withColumn("age", split(col("data"), "\t")(2))
.select("id", "name", "age")
val query = transDF.writeStream
.format("iceberg")
.outputMode("append")
//每分钟触发一次Trigger.ProcessingTime(1, TimeUnit.MINUTES)
//每10s 触发一次 Trigger.ProcessingTime(1, TimeUnit.MINUTES)
.trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS))
.option("path", "test2.default.users")
.option("fanout-enabled", "true")
.option("checkpointLocation", checkpointPath)
.start()编写完核心代码之后,我们直接运行一下:
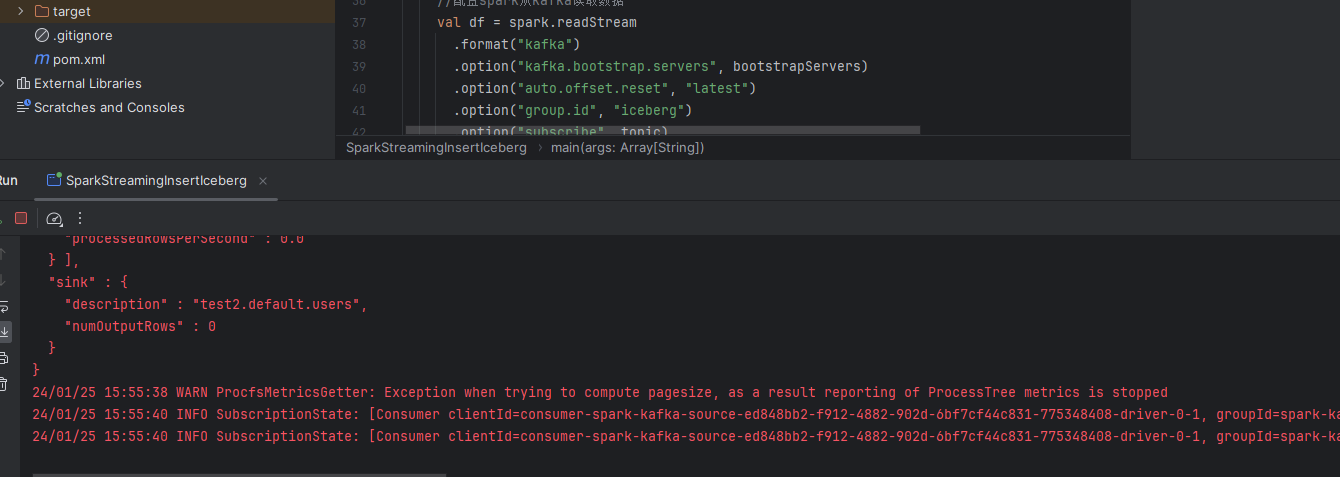
会看到这个job是常驻的。此时我们去hdfs上就能看到对应的数据:
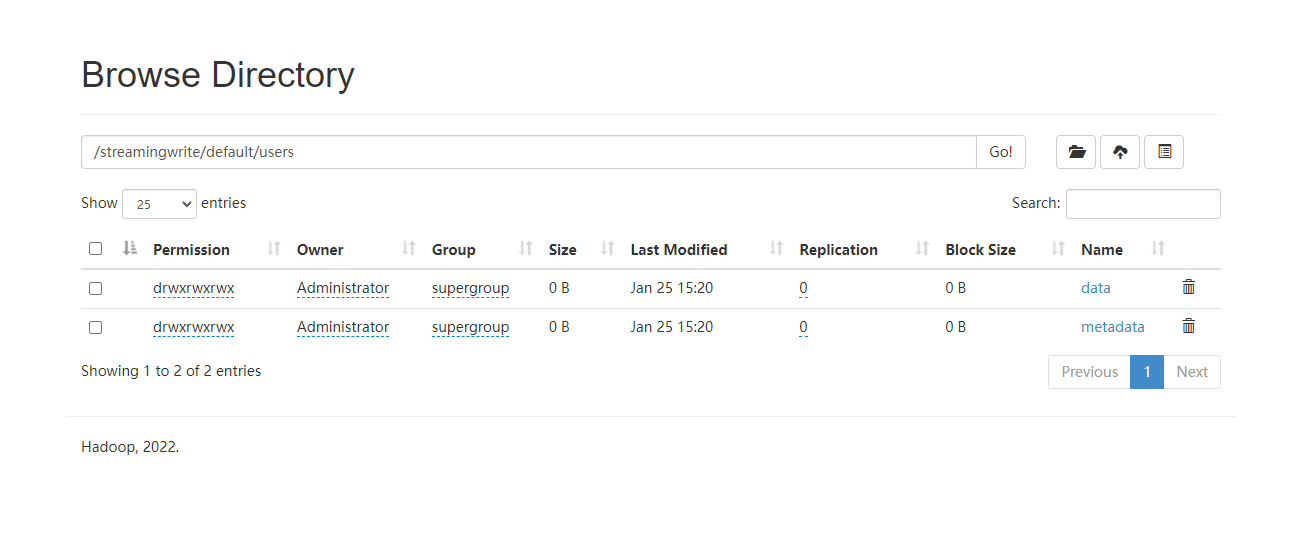
接着我们编写一个读取程序,读取iceberg里面的数据:
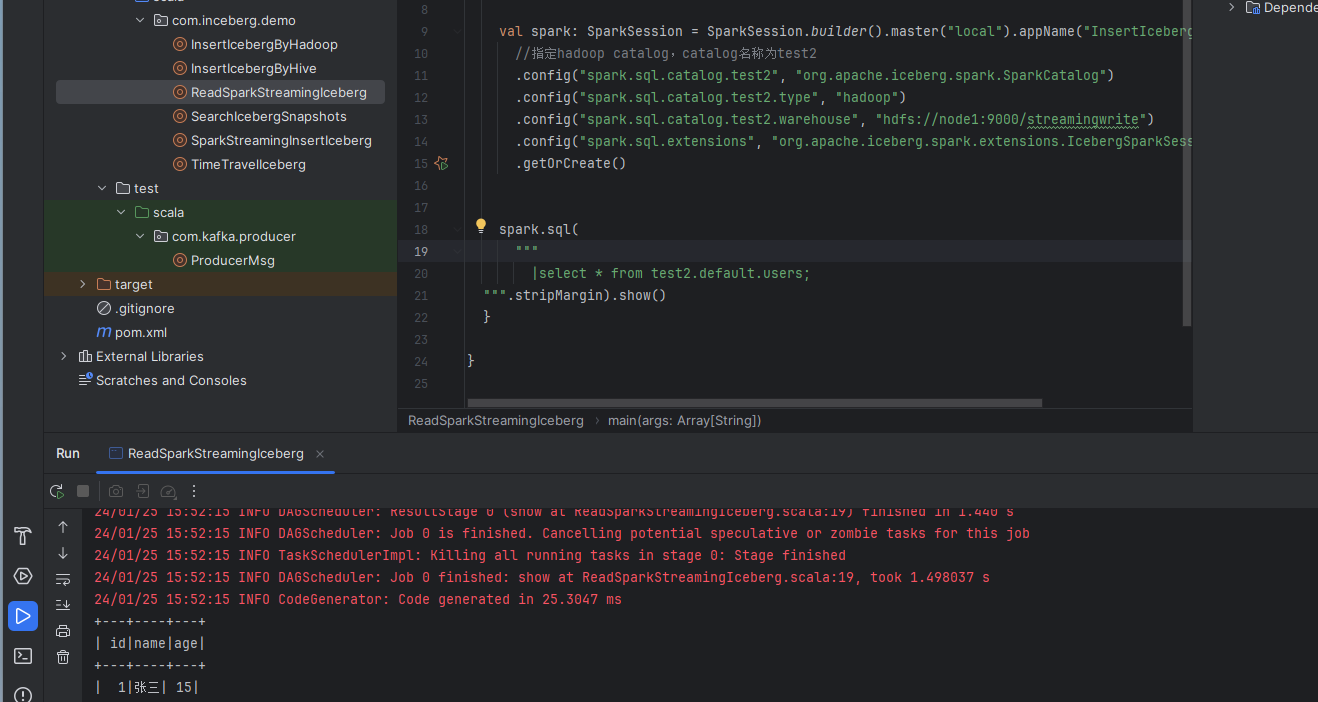
可以看到数据是被源源不断的写入到iceberg里面的。
以上就是Spark Structured Streaming近实时写入iceberg的案例,主要是分隔符版本,这个分隔符版本是指kafka里面的数据是line形式,然后使用分隔符进行分隔。我们下一篇文章给大家演示下json格式的版本。
最后附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...