
上文《数据湖系列(二十三)Spark Structured Streaming近实时写入iceberg(分隔符版本)》我们介绍了从kafka里面接收分隔符版本的示例数据,然后把数据写入到iceberg里面。但是由于分隔符版本会有一些缺点,例如:
1、数据本身就带有分隔符的符号,会导致数据解析失败 2、分隔符版本的数据不方便会查具体的数据结构
所以对于我们在实际的工作中来说,一般发送的数据还是已json的方式进行的,因此这里的话,我们再来演示下接收json格式的数据,然后写入到iceberg里面去。
1)首先我们还是在之前的项目里面编写具体的代码,创建一个名称为:SparkStreamingInsertIcebergByJson的😮💨。
2)在main函数里面编写核心代码:
val resDF = df.selectExpr("CAST(value AS STRING) as value") // 这里需要将value列转换为字符串类型
.select(from_json(col("value"), schema).as("data")) // 使用col函数提取value列的值,然后进行解析
.select(col("data.*")) // 选取所有"data"列的数据
// 流式写入Iceberg表
resDF.writeStream
.format("iceberg")
.outputMode("append")
.trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS))
.option("path", "test3.default.users")
.option("checkpointLocation", checkpointPath)
.start()
.awaitTermination()这里前端的代码和之前都是一样的,主要是初始化spark,初始化kafka,read from kafka,建立数据结构。主要的核心是怎么解析这里的json,并且提取json数据的列作为对应的dataframe,然后再把这里的dataframe写入到iceberg里面去。
最后我们来运行一下:
接着我们运行下这里的KafkaProducer代码,模拟向kafka发送数据

此时,spark structed streaming程序接收到kafka的数据,就会开始执行相关的解析及写入操作,此时我们去hdfs上看看写入iceberg的数据:

可以看到数据已经写入进来了。我们再使用前面些的find程序读取下写入的结果,示例图如下:
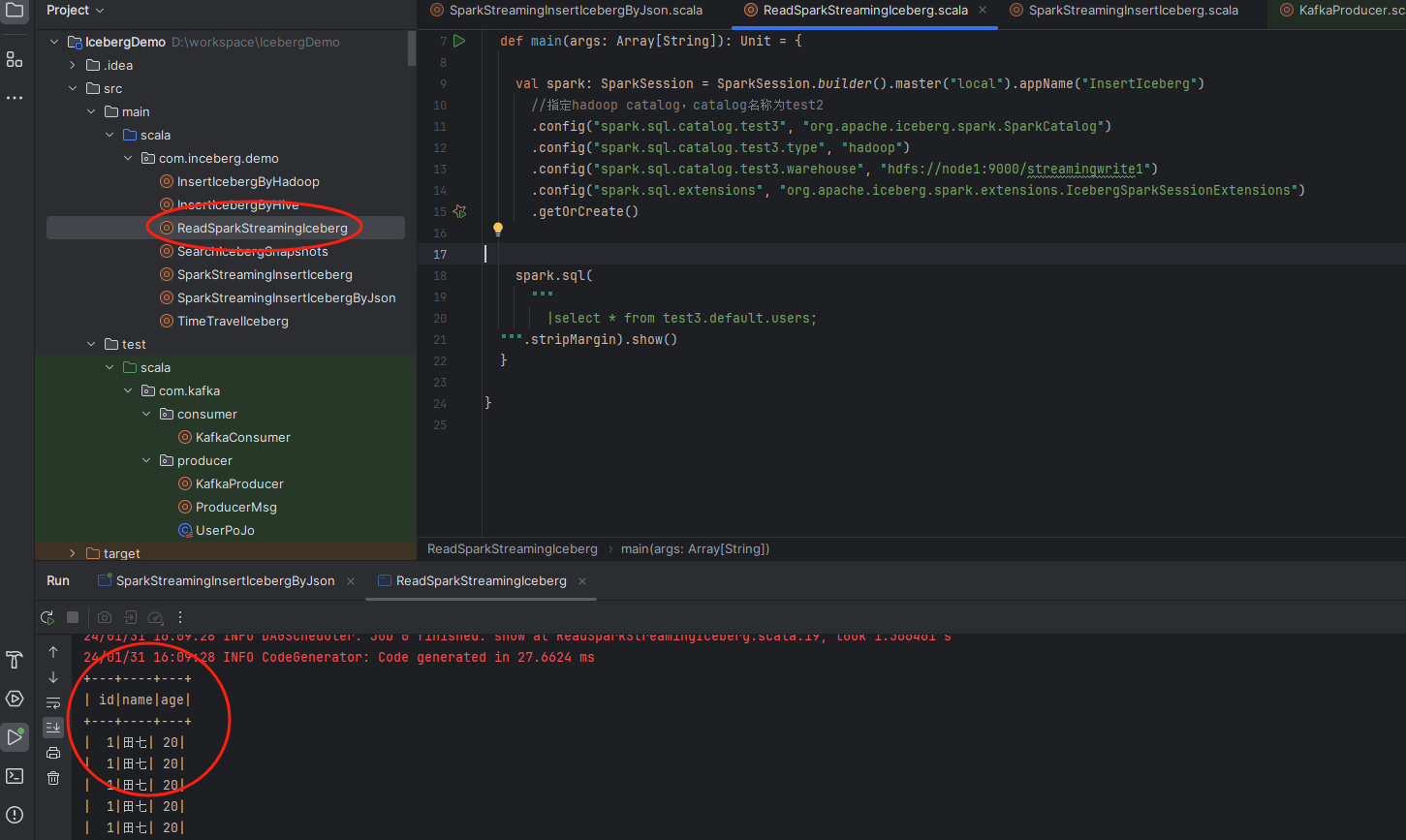
可以看到数据是读出来了,说明前面写入的数据是没有任何问题的。
备注:
1、这里网上大多数的文章主要都是演示使用分隔符版本把数据写入到iceberg,所以这里特别的写一篇关于json版本的,其实也没多难。 2、这里演示代码比较简单,一般我们还要做一些判断,避免出现错误的json数据导致spark job运行失败,这里的话就大家自行补充了。
最后按照惯例,附上本案例的源码,登录后即可下载:








还没有评论,来说两句吧...