
前面我们演示了使用spark操作iceberg的数据,接着我们就来演示下flink操作iceberg数据。flink操作iceberg数据的形式主要有两种,分别是:
1、datastream 2、flink sql
现如今主要有Dinky的加持,所以在日常工作中使用flink sql的形式操作iceberg会更加顺畅一点。这里我们就主要使用flink sql的形式来操作iceberg。整体操作iceberg的顺序和操作mysql是一样的,主要流程如下:
1、创建多数据源目录catalog 2、使用多数据源目录catalog 3、创建database 4、使用database 5、创建table 6、向table插入数据 7、向table查询数据 8、显示查询结果
所以这里演示的话,我们的核心代码如下:
package com.flink.iceberg.demo;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkSqlInsertIceberg {
public static void main(String[] args) {
//初始化flink相关的环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);
env.enableCheckpointing(1000);
//后面的查询主要是演示实时查询,如果要实时查询就要做如下的设置。
Configuration configuration = tblEnv.getConfig().getConfiguration();
// 支持SQL语法中的 OPTIONS 选项
configuration.setBoolean("table.dynamic-table-options.enabled", true);
//1.创建多数据源目录Catalog
tblEnv.executeSql("CREATE CATALOG flink_cal_1 WITH (" +
"'type'='iceberg'," +
"'catalog-type'='hadoop'," +
"'warehouse'='hdfs://node1:9000/flink_iceberg')");
//2.使用创建的Catalog
tblEnv.useCatalog("flink_cal_1");
//3.创建数据库
// tblEnv.executeSql("create database test1");
//4.使用数据库
// tblEnv.useDatabase("test1");
//5.创建users表结构
// tblEnv.executeSql("create table if not exists flink_cal_1.test1.users(id int,name string,age int,loc string) partitioned by (loc)");
//6.写入数据到users表
tblEnv.executeSql("insert into flink_cal_1.test1.users values (1,'张三',18,'beijing'),(2,'李四',19,'shanghai'),(3,'王五',20,'guangzhou')");
//7.写入之后读取一下,后面添加options主要是为了做实时查询
TableResult tableResult = tblEnv.executeSql("select * from flink_cal_1.test1.users /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/");
//8、把读取的结果显示出来
tableResult.print();
}
}最后我们运行一下这个flink job,示例图如下:
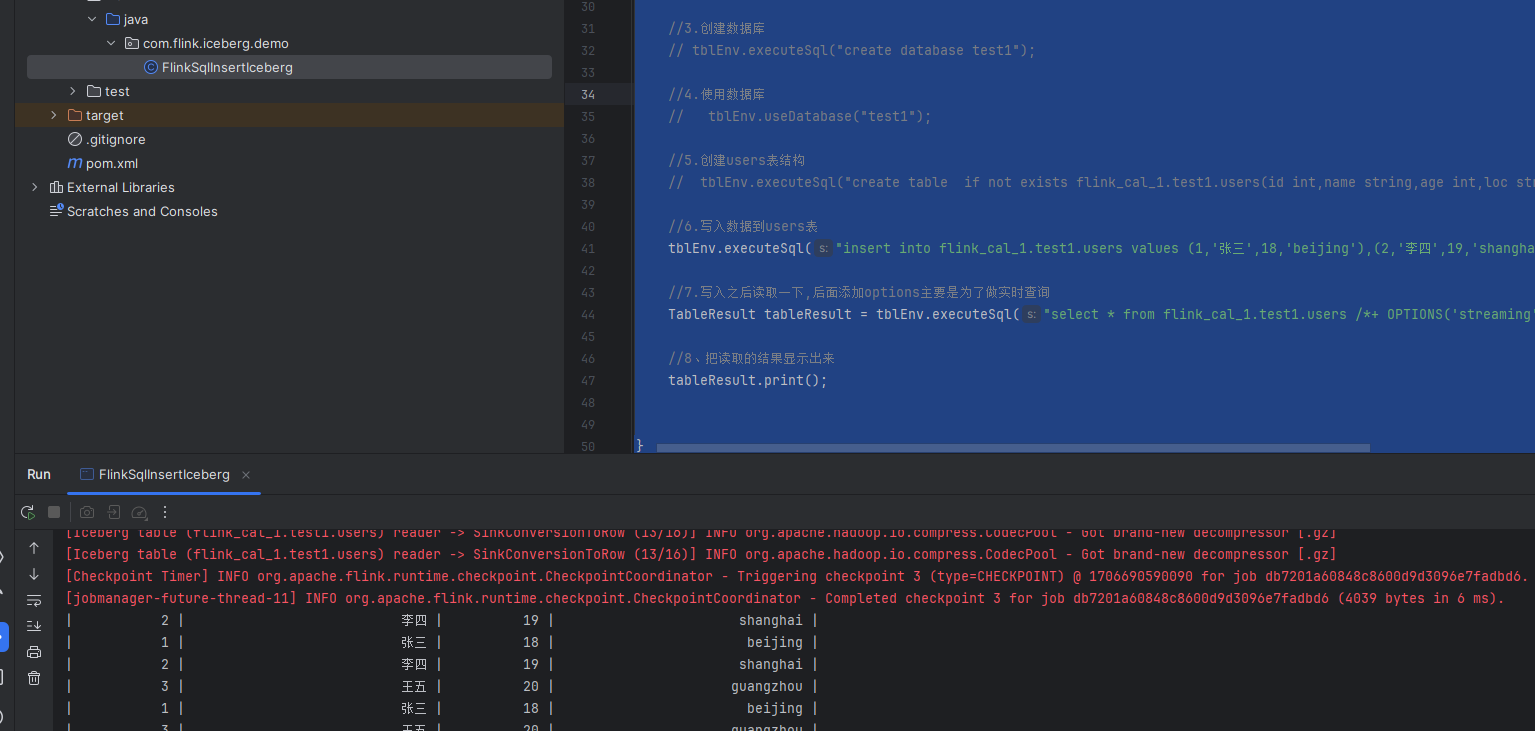
可以看到这里我们插入了数据,并且实时显示出来了。
备注:
1、在flink中只有checkpoint之后,数据才会被commit到sink里面,如果checkpoint失败了,那么就不会commit数据到sink,就无法查询对应的数据。 2、在flink中如果想要近实时的查询数据,就要设置一下conf,并且启用注解的形式来进行查询。注意这里查询结果还是近实时,不是准实时。
最后按照惯例,附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...