
前面我们完成了数据仓库的分层设计,接下来就要开始建模了。建模之前,我们要考虑的就是如何选择建模的模型。
在数仓中常用的模型主要分为3大类,分别是:
1、维度模型 2、ER模型 3、Data Vault模型 4、Anchor模型
下面我们挨个来介绍下
1、维度模型
维度模型里面主要有:
星型模型 雪花模型 星座模型
1)星型模型
这里的星型模型的示例图如下:

星型模型主要是中心为事实表,四周环绕的是维度表,如上图所示。他的优点是:
1、查询效率高:由于事实表是扁平化的,查询时可以快速扫描数据,提高查询效率。 2、数据冗余少:维度表中的数据只需存储一次,减少了数据冗余。 3、易于理解和实现:星型模型的结构简单,易于理解和实现。
他的缺点也很明显,例如:
维度有限:星型模型的维度数固定且有限,无法灵活地扩展。 数据重复:由于数据重复存储,更新时可能引发数据不一致问题。 不适合复杂分析:星型模型对于复杂的聚合分析和多维分析支持不佳。
2)雪花模型
雪花模型的示例图如下:

雪花模型是一种多层次的数据模型,具有更高的灵活性和扩展性。在雪花模型当中,他的中心是1个或者多个事实表,周围环绕着多个维度表,并且维度表之间可以通过关联关系来形成更复杂的数据结构。雪花模型的优点有:
1、灵活性高:雪花模型可以支持更多维度和更复杂的数据分析,易于扩展和变化。 2、数据一致性高:由于数据分层存储,更新时不易引发数据不一致问题。 3、支持复杂分析:雪花模型对于复杂的聚合分析和多维分析有良好的支持。
当然雪花模型也有他的缺点,例如:
1、查询效率低:由于数据结构复杂,查询时需要遍历更多数据,导致查询效率较低。 2、数据冗余多:雪花模型的数据冗余较多,占用了更多的存储空间。 3、实现难度较大:雪花模型的构建和维护需要更多的技术和资源投入。
3)星座模型
星座模型的示例图如下:

这里的星座模型就像一个网状结构,通过将多个事实表或者维度表相互连接在一起,形成一个更为复杂的模型。他的优点主要是:
1、能够支持复杂的数据分析需求和业务场景 2、各个星型模型相对独立,可以独立维护和扩展,从而提高了模型的灵活性和可维护性。 3、星座模型还可以通过多维分析来揭示数据之间的复杂关系。
当然他的缺点也很多,例如:
1、由于模型结构更加复杂,可能导致查询性能下降。 2、星座模型的构建和维护成本较高,需要确保各个星型模型之间的关联关系正确无误。因此,星座模型适用于数据分析需求较为复杂且业务场景较为多样化的场景。
2、ER模型
在ER模型里面,他的实现主要有3NF,所以这里我们主要介绍3NF
3NF
这个3NF主要是第三范式模型,第三范式是什么我们来回顾一下:
每张表中的数据不会冗余,一旦有冗余字段,就需要拆一张表出来,用外键与主表关联。
举个例子,咱们这里有如下的一张学生表
| user_id | username | age | class_id | class_name |
| 1 | 张三 | 15 | 1 | 1班 |
| 2 | 李四 | 16 | 1 | 1班 |
此时我们可以看到学生表里面的班级冗余了,所以按照第三范式来说,我们需要把班级给拆分出来,拆出来的就是:
学生表
| user_id | username | age | class_id |
| 1 | 张三 | 15 | 1 |
| 2 | 李四 | 16 | 1 |
班级表
| class_id | class_name |
| 1 | 1班 |
| 1 | 1班 |
关于3NF模型的优点有:
1、数据量减小,修改记录值方便。
缺点有:
1、查询复杂度增大,需要表关联,耗费响应时间。
3、Data Vault模型
这里的DataValult模型主要的实现有:
1、Hubs 2、Links 3、Satelites
这3个一般是合成一体的,所以我们主要介绍一下:
中心表(Hub)
对于构建Data Vault模型的,第一件事就是构建中心表,中心表示DV模型中的核心。如果设计得当,将可以兼容整合各种数据源。为了达到这点,就应该假设系统源是不可知的,所以中心表应该依赖于实际的业务逻辑标识,而不是使用代理键。
中心表的表结构:
字段 | 说明 |
|---|---|
hub_key | 代理主键,通过对业务主键进行MD5计算所得 |
business_key | 业务主键,唯一标识业务主键,来之源系统 |
load_dts | 数据第一次转载的时间,只记录第一次转载时间 |
rec_src | 数据源系统 |
链接表(Link)
链接表的目的是为了灵活性和易扩展,通过链接表可以在不改变原有的构架和转载条件下进行扩展。在Data Vault模型中所有的关系和事件都是通过链接表来表示。在DV模型中,中心表没有外键,对于中心表间的连接是通过链接表。所以链接表至少要有两个父中心表。
链接表表结构:
字段 | 说明 |
|---|---|
link_key | 代理主键,使用相关的父Hub表的业务主键拼接后计算MD5值 |
hub_keys | hubs的代理键 |
hub_business_keys | hubs的业务主键 |
load_dts | 第一次装载数据的时间 |
rec_src | 源系统信息 |
卫星表(附属表Satellite)
卫星表示所有的原始数据系统,在这个表中也捕获数据的变化,所以这种表有点像维度模型中的渐变维度表。一个附属表总有一个且唯一一个外键引用到中心表或链接表。
卫星表表结构:
字段 | 说明 |
|---|---|
sta_key | 代理主键,相关的hub或link表的主键和数据载入时间的MD5值 |
hub_or_link_key | 父hub或Link的代理主键 |
attribute_columns | 属性数据列 |
hash_diff | 各列拼接后的MD5值计算 |
sat_load_dts | 数据装载时间 |
sat_rec_src | 数据来源信息 |
总结下上面三个表,主要的核心是:
表 | 关键字 | 作用 |
|---|---|---|
Hubs中心表 | business_key业务主键 | 使其以业务为导向, 并允许跨系统集成 |
Links链接表 | Associations/Transactions关联和转换 | 提供了在无需重新设计的情况下吸收结构和业务规则更改的灵活性 |
Satellites附属表 | Descriptors描述性信息 | 提供在任何想要的时间间隔内记录历史记录的适应性, 以及对源系统的无可争辩的可审核性和可追溯性 |
通过Data Vault模型可以获得敏捷性、灵活性、适应性、可审核性、可扩展性。
举个案例来说明Data Vault模型的使用:
假设下面是一个销售订单的相关表,业务模型图如下:
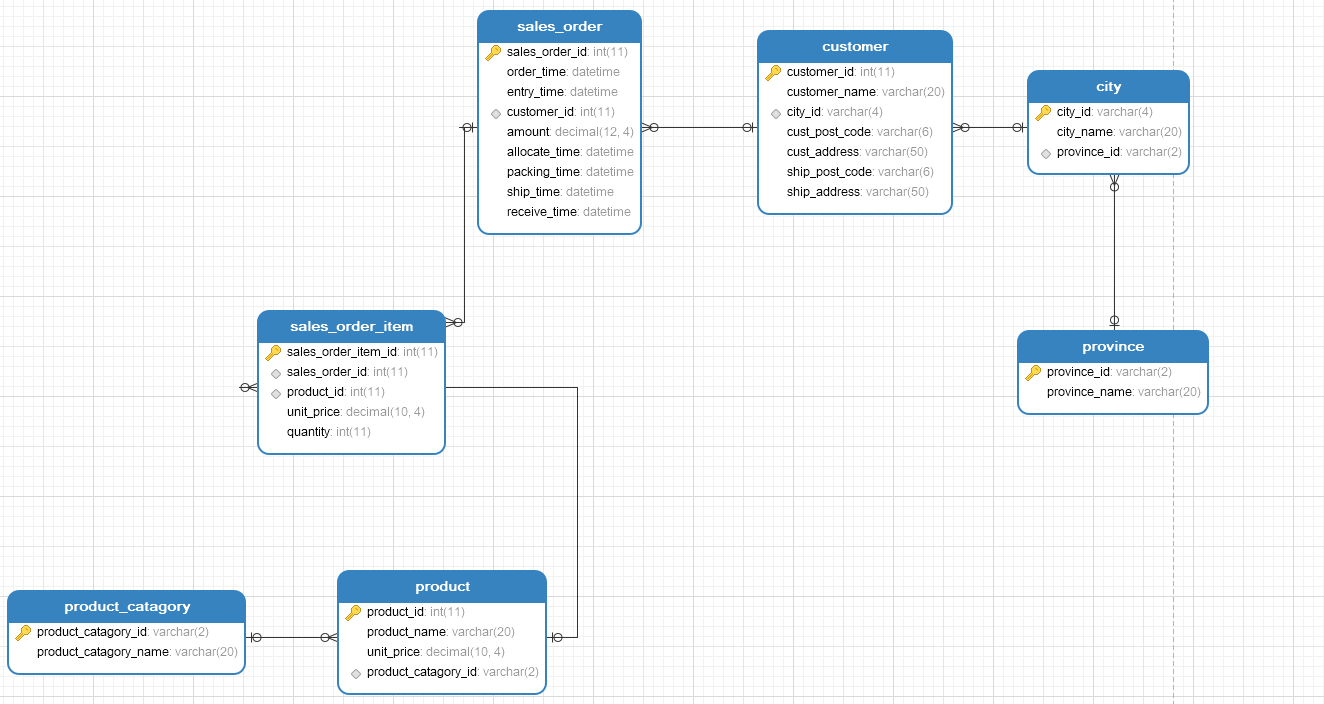
上图建表的sql语句如下:
CREATE TABLE province ( province_id varchar(2) NOT NULL COMMENT '省份编码', province_name varchar(20) DEFAULT NULL COMMENT '省份名称', PRIMARY KEY (province_id) ) ; CREATE TABLE product_catagory ( product_catagory_id varchar(2) NOT NULL COMMENT '产品分类编码', product_catagory_name varchar(20) DEFAULT NULL COMMENT '产品分类名称', PRIMARY KEY (product_catagory_id) ) ; CREATE TABLE city ( city_id varchar(4) NOT NULL COMMENT '城市编码', city_name varchar(20) DEFAULT NULL COMMENT '城市编码', province_id varchar(2) DEFAULT NULL COMMENT '省份编码', PRIMARY KEY (city_id), FOREIGN KEY (province_id) REFERENCES province (province_id) ) ; CREATE TABLE customer ( customer_id int(11) NOT NULL AUTO_INCREMENT COMMENT '客户ID', customer_name varchar(20) DEFAULT NULL COMMENT '客户名称', city_id varchar(4) DEFAULT NULL COMMENT '城市ID', cust_post_code varchar(6) DEFAULT NULL COMMENT '客户邮编', cust_address varchar(50) DEFAULT NULL COMMENT '客户地址', ship_post_code varchar(6) DEFAULT NULL COMMENT '送货邮编', ship_address varchar(50) DEFAULT NULL COMMENT '送货地址', PRIMARY KEY (customer_id), FOREIGN KEY (city_id) REFERENCES city (city_id) ) ; CREATE TABLE product ( product_id int(11) NOT NULL AUTO_INCREMENT COMMENT '产品ID', product_name varchar(20) DEFAULT NULL COMMENT '产品名称', unit_price decimal(10,4) DEFAULT NULL COMMENT '产品单价', product_catagory_id varchar(2) DEFAULT NULL COMMENT '产品分类编码', PRIMARY KEY (product_id), FOREIGN KEY (product_catagory_id) REFERENCES product_catagory (product_catagory_id) ) ; CREATE TABLE sales_order ( sales_order_id int(11) NOT NULL AUTO_INCREMENT COMMENT '订单ID', order_time datetime DEFAULT NULL COMMENT '下单时间', entry_time datetime DEFAULT NULL COMMENT '录入时间', customer_id int(11) DEFAULT NULL COMMENT '客户ID', amount decimal(12,4) DEFAULT NULL COMMENT '订单金额', allocate_time datetime DEFAULT NULL COMMENT '分配库房时间', packing_time datetime DEFAULT NULL COMMENT '出库时间', ship_time datetime DEFAULT NULL COMMENT '配送时间', receive_time datetime DEFAULT NULL COMMENT '收货时间', PRIMARY KEY (sales_order_id), FOREIGN KEY (customer_id) REFERENCES customer (customer_id) ) ; CREATE TABLE sales_order_item ( sales_order_item_id int(11) NOT NULL AUTO_INCREMENT COMMENT '订单明细ID', sales_order_id int(11) DEFAULT NULL COMMENT '订单ID', product_id int(11) DEFAULT NULL COMMENT '产品ID', unit_price decimal(10,4) DEFAULT NULL COMMENT '产品单价', quantity int(11) DEFAULT NULL COMMENT '数量', PRIMARY KEY (sales_order_item_id), FOREIGN KEY (sales_order_id) REFERENCES sales_order (sales_order_id), FOREIGN KEY (product_id) REFERENCES product (product_id) ) ;
此时我们需要转换成Data Vault模型的话,步骤如下:
1)转换中心表
确定中心实体
客户、产品类型、产品、订单、订单明细这5个实体是订单销售业务的中心实体。省、市等地理信息表是参考数据,不能算是中心实体,实际上是附属表。
实体引用
把第一步确定的中心实体中有入边的实体转换为中心表,因为这些实体被别的实体引用。把客户、产品类型、产品、订单转换成中心表
实体转换
把第一步确定的中心实体中没有入边且只有一条出边的实体转换为中心表,因为必须至少有两个Hub才能产生一个有意义的Link。
所以最后转换的中心表如下:
实体 | 业务主键 |
|---|---|
hub_product_catagory | product_catagory_id |
hub_customer | customer_id |
hub_product | product_id |
hub_sales_order | sales_order_id |
2)转换链接表
1、把源库中没有入边且有两条或两条以上出边的实体直接转换成链接表,即把订单明细转换成链接表 2、把源库中除第一步以外的外键关系转换成链接表。即订单和客户之间建立链接表,产品和产品类型之间建立链接表。
下面是所有的链接表
链接表 | 被链接的中心表 |
|---|---|
link_order_product | hub_sales_order,hub_product |
link_order_customer | hub_sales_order,hub_customer |
link_product_catagory | hub_product,hub_product_catagory |
3)转换附属表
附属表为中心表和链接表补充属性。所有源库中用到的表的非键属性都要放到Data Vault模型中。
下面列举所有的附属表信息
附属表 | 描述 |
|---|---|
sat_customer | hub_customer |
sat_product_catagory | hub_product_catagory |
sat_product | hub_product |
sat_sales_order | hub_sales_order |
sat_order_product | link_order_product |
最后我们根据上面的转换,创建对应的表信息,sql语句如下:
create table hub_product_catagory ( hub_product_catagory_id int auto_increment primary key, product_catagory_id varchar(2), load_dts timestamp, record_source varchar(100) ); create table hub_customer ( hub_customer_id int auto_increment primary key, customer_id int, load_dts timestamp, record_source varchar(100) ); create table hub_product ( hub_product_id int auto_increment primary key, product_id int, load_dts timestamp, record_source varchar(100) ); create table hub_sales_order ( hub_sales_order_id int auto_increment primary key, sales_order_id int, load_dts timestamp, record_source varchar(100) ); create table link_order_product ( link_order_product_id int auto_increment primary key, hub_sales_order_id int, hub_product_id int, load_dts timestamp, record_source varchar(100), foreign key (hub_sales_order_id) references hub_sales_order (hub_sales_order_id), foreign key (hub_product_id) references hub_product (hub_product_id) ); create table link_order_customer ( link_order_customer_id int auto_increment primary key, hub_sales_order_id int, hub_customer_id int, load_dts timestamp, record_source varchar(100), foreign key (hub_sales_order_id) references hub_sales_order (hub_sales_order_id), foreign key (hub_customer_id) references hub_customer (hub_customer_id) ); create table link_product_catagory ( link_product_catagory_id int auto_increment primary key, hub_product_id int, hub_product_catagory_id int, load_dts timestamp, record_source varchar(100), foreign key (hub_product_id) references hub_product (hub_product_id), foreign key (hub_product_catagory_id) references hub_product_catagory (hub_product_catagory_id) ); create table sat_customer ( sat_customer_id int auto_increment primary key, hub_customer_id int, load_dts timestamp, load_end_dts timestamp, record_source varchar(100), customer_name varchar(20), city_name varchar(20), province_name varchar(20), cust_post_code varchar(6), cust_address varchar(50), ship_post_code varchar(6), ship_address varchar(50), foreign key (hub_customer_id) references hub_customer (hub_customer_id) ); create table sat_product_catagory ( sat_product_catagory_id int auto_increment primary key, hub_product_catagory_id int, load_dts timestamp, load_end_dts timestamp, record_source varchar(100), product_catagory_name varchar(20), foreign key (hub_product_catagory_id) references hub_product_catagory (hub_product_catagory_id) ); create table sat_product ( sat_product_id int auto_increment primary key, hub_product_id int, load_dts timestamp, load_end_dts timestamp, record_source varchar(100), product_name varchar(20), unit_price decimal(10 , 4 ), foreign key (hub_product_id) references hub_product (hub_product_id) ); create table sat_sales_order ( sat_sales_order_id int auto_increment primary key, hub_sales_order_id int, load_dts timestamp, load_end_dts timestamp, record_source varchar(100), order_time datetime, entry_time datetime, amount decimal(12 , 4 ), allocate_time datetime, packing_time datetime, ship_time datetime, receive_time datetime, foreign key (hub_sales_order_id) references hub_sales_order (hub_sales_order_id) ); create table sat_order_product ( sat_order_product_id int auto_increment primary key, link_order_product_id int, load_dts timestamp, load_end_dts timestamp, record_source varchar(100), unit_price decimal(10 , 4 ), quantity int, foreign key (link_order_product_id) references link_order_product (link_order_product_id) );
最后的结果示例图如下:

以上Data Vault模型的优点有:
1、它能够有效地存储大量数据,同时能够保持数据的完整性和可访问性。 2、它能够有效地处理数据的变化,它能够灵活地应对数据的变化,并能够快速地适应新的业务需求。
当然Data Vault模型的缺点也是存在的,例如:
1、它的实施需要较高的技术水平,需要专业的数据仓库设计师来设计和实施。 2、由于Data Vault模型是一种复杂的数据模型,因此需要对数据进行严格的规范化,以确保数据的完整性和可访问性。
4、Anchor模型
这里的Anchor模型是在Data Vault模型上进行改进的,他主要是更细化一点,也就是进而演化成K-V结构的模型。对于此类模型一般使用会比较少,我也没用过,所以暂时不做过多介绍。
以上就是我们在数据仓库建模设计之前需要考虑的模型选择。一个良好的模型决定了这个数仓在实际业务中的优劣。所以大家有时间多琢磨一下。








还没有评论,来说两句吧...