
接上篇《构建一个完整的数据仓库(九)doris支持哪些数据结构?》。本篇我们介绍下doris的数据模型。本文我们在讲解doris的数据模型的时候,我们会给大家抽象的用mysql做比喻,方便大家理解。
1、doris的数据模型有哪些?
在doris中,数据模型一共有3种,分别是: 1、Duplicate 明细模型 2、Aggregate 聚合模型 3、Unique 主键唯一模型
下面我们分别介绍下这3种模型。
1.1、Duplicate明细模型
duplicate明细模型其实就相当于mysql的普通表,在这个表中我们可以保存所有的明细数据,即使有重复都可以。举例说明,假设我们有一张user表,表里面的字段分别是:userid,username,usercost,costdate。根据这几个字段我们很容易理解成这是一张用户消费明细表,如果这种表的模型指定为Duplicate的时候,我们插入这样的数据。
insert into user values(1,'张三',5.2,'2022-04-20 07:00:00') insert into user values(1,'张三',10.7,'2022-04-20 08:00:00') insert into user values(2,'李四',7.6,'2022-04-20 08:00:00')
插入上诉3条数据后,我们通过select * from user表能看到数据库里面有3条数据,就是上诉的3条数据。大家可能想这不就是mysql吗?在这里只能说明细模型的效果看起来和mysql是一样的。下面我们来试验下。
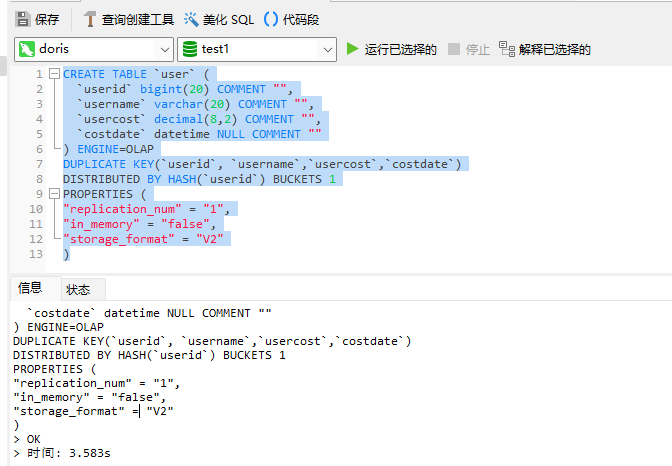
1)创建user表
CREATE TABLE `user` ( `userid` bigint(20) COMMENT "", `username` varchar(20) COMMENT "", `usercost` decimal(8,2) COMMENT "", `costdate` datetime NULL COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(`userid`, `username`,`usercost`,`costdate`) DISTRIBUTED BY HASH(`userid`) BUCKETS 1 PROPERTIES ( "replication_num" = "1", "in_memory" = "false", "storage_format" = "V2" )
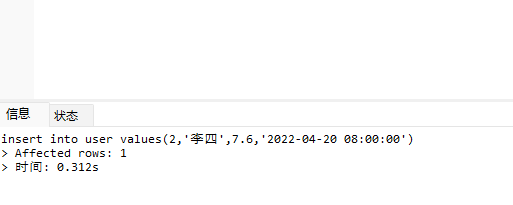
2)插入上诉3条数据
insert into user values(1,'张三',5.2,'2022-04-20 07:00:00') insert into user values(1,'张三',10.7,'2022-04-20 08:00:00') insert into user values(2,'李四',7.6,'2022-04-20 08:00:00')
3)查询结果
select * from user;
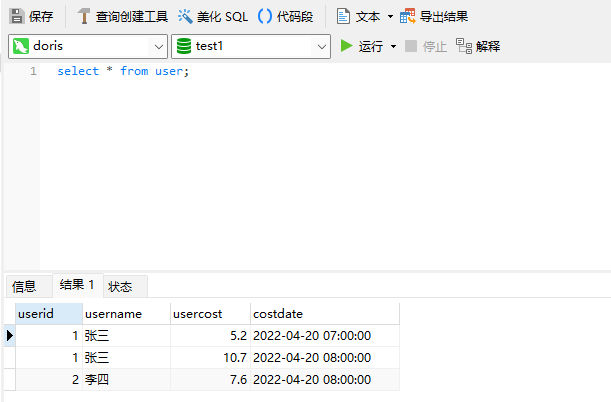
一共三条数据,他不会做任何裁剪,插进去多少条数据,就会保存多少条数据。所以顾名思义就是明细数据模型。明细模型是 DORIS 默认使用的数据模型。该数据模型不会对导入的数据进行任何处理。表中的数据即用户导入的原始数据。
1.2、Aggregate 聚合模型
聚合模型就类似于我们统计topN,换个例子,日常中比如我们的商场后台,每个商户每天都可能会上传N个商品,那么在我们的后台数据大盘里面,我们需要统计每天,每个商户上传的商品总量,每个月每个商户上传的商品总量。这时候我们怎么做呢?在传统的做法里面我们就是把所有的记录都保存到一张表里,在统计页面接口请求的时候,我们使用select sum函数去进行统计即可,在Aggregate聚合模型里面,他可以做自动统计,我们在查询的时候就不再需要sum函数进行统计了,在插入的时候,还是和普通插入一样操作。这时候比如我们的大盘信息展示是不是就很快了?
举例说明,假设我们有一张user表,表里面的字段分别是:userid,username,usercost,costdate。根据这几个字段我们很容易理解成这是一张用户消费明细表,如果这种表的模型指定为Aggregate的时候,我们插入这样的数据。
insert into user values(1,'张三',5.2,'2022-04-20 07:00:00') insert into user values(1,'张三',10.7,'2022-04-20 08:00:00') insert into user values(2,'李四',7.6,'2022-04-20 08:00:00')
插入上诉3条数据后,我们通过select * from user表能看到数据库里面有2条数据,这里的usercost和costdate就会聚合和替换了。下面我们试验下。
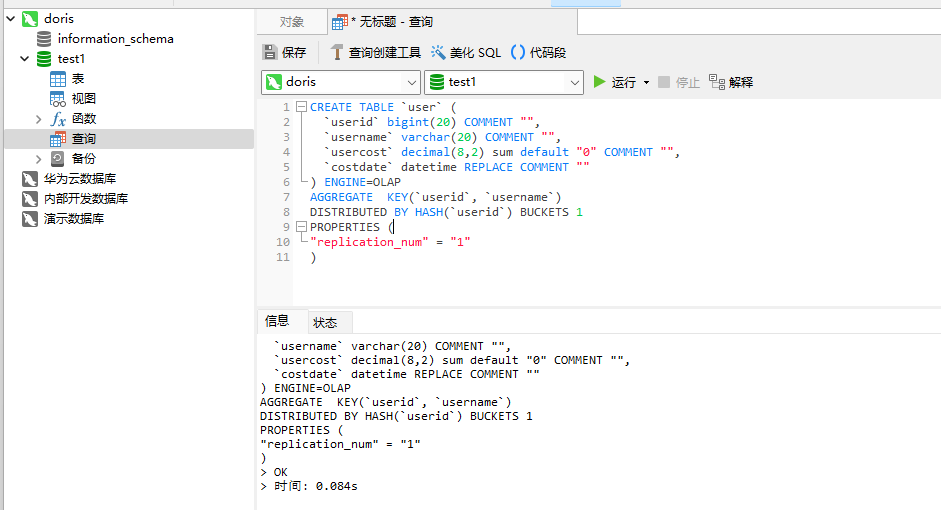
1)创建user表
CREATE TABLE `user` ( `userid` bigint(20) COMMENT "", `username` varchar(20) COMMENT "", `usercost` decimal(8,2) sum default "0" COMMENT "", `costdate` datetime REPLACE COMMENT "" ) ENGINE=OLAP AGGREGATE KEY(`userid`, `username`) DISTRIBUTED BY HASH(`userid`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" )
创建表的时候有个小插曲,就是如果大家根据之前文章安装的doris的话,需要修改下be的配置,并重启。不然会提示:errCode = 2, detailMessage = Failed to find enough host with storage medium and tag(HDD/{"location" : "default"}) in all backends. need: 1 这个错误。修改步骤如下:
1、在${be_home}目录下创建mediumstorage目录,即: mkdir mediumstorage
2、修改be.conf,添加:storage_root_path = /home/pubserver/doris/be/storage,medium:hdd;/home/pubserver/doris/be/mediumstorage,medium:ssd 这里的路径修改为自己的实际路径。2)插入数据
insert into user values(1,'张三',5.2,'2022-04-20 07:00:00') insert into user values(1,'张三',10.7,'2022-04-20 08:00:00') insert into user values(2,'李四',7.6,'2022-04-20 08:00:00')
3)查询数据
select * from user;
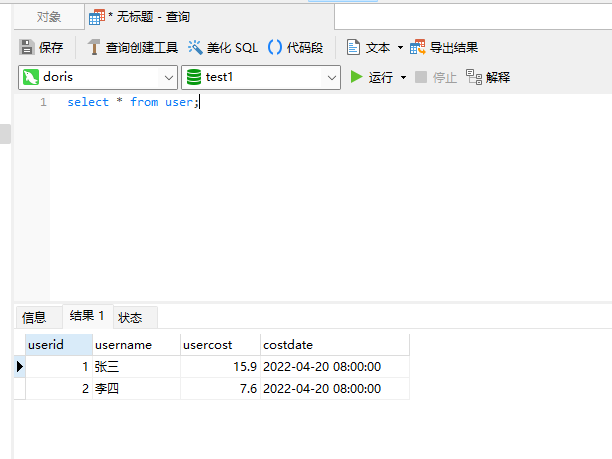
看到了吧,查询到了2条数据,usercost做了自动聚合,userid为1的costdate做了覆盖,这里的覆盖是最后插入的那一条userid=1,username=张三的数据的costdate数据。这就是Aggregate 聚合模型。
1.3、Unique 唯一主键模型
Unique 唯一主键模型就是指通过主键的唯一性,保证某些唯一性的数据只保留一份。可以理解成mysql,比如我们在创建表的时候主键是唯一的,那么插入相同主键的数据是不是插入不了?这个Unique 唯一主键模型就是这样的效果。
举例说明,假设我们有一张user表,表里面的字段分别是:userid,username,usercost,costdate。根据这几个字段我们很容易理解成这是一张用户消费明细表,如果这种表的模型指定为Aggregate的时候,我们插入这样的数据。
insert into user values(1,'张三',5.2,'2022-04-20 07:00:00') insert into user values(1,'张三',10.7,'2022-04-20 08:00:00') insert into user values(2,'李四',7.6,'2022-04-20 08:00:00')
如果我们的主键是userid的话,那么最后我们只能查出来2条数据,userid为1的张三这条数据只能保留一条。下面我们试验下。
1)创建user表
CREATE TABLE `user` ( `userid` bigint(20) COMMENT "", `username` varchar(20) COMMENT "", `usercost` decimal(8,2) COMMENT "", `costdate` datetime NULL COMMENT "" ) ENGINE=OLAP UNIQUE KEY(`userid`) DISTRIBUTED BY HASH(`userid`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" )
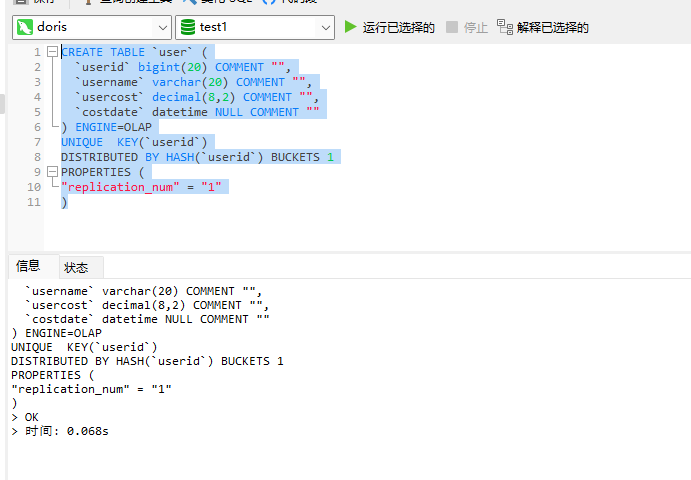
2)插入数据
insert into user values(1,'张三',5.2,'2022-04-20 07:00:00') insert into user values(1,'张三',10.7,'2022-04-20 08:00:00') insert into user values(2,'李四',7.6,'2022-04-20 08:00:00')
3)查询数据
select * from user;
最后结果只有2条,而且张三这里的第二条插入的数据自动覆盖了第一条的插入数据,这是和mysql不一样的,mysql主键相同的话会直接报错,不让插入,doris正相反,主键相同的话会自动进行覆盖。所以Unique 唯一主键模型即在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Unique 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
二、聚合模型的局限性
在官方的文档里面,也提到了聚合模型的局限性,聚合模型(包括 Unique 模型),通过一种预计算的方式来减少查询时需要实时计算的数据量,加速查询。但是这种模型会有使用上的局限性。在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。
说的直白一点:这种聚合表的时候,我们能查到的数据是查询那一刻时间已经聚合好的数据,可能在查询的时候,某些数据正在发生聚合,所以这时候查到的数据看起来就是不准确的,可能这一秒查到的数据是1,下一秒查到的数据就是2了,所以在使用这个的时候,业务上不对应该很敏感,不应该保证绝对的正确性。如果要保证数据绝对的正确性的时候,还的使用sum函数这些。
三、数据模型的选择的一些建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是 REPLACE,没有 SUM 这种聚合方式)。
Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
最后额外补充几点:
1、在上诉插入的时候,我们看到执行时间非常长,这个是由于使用navicat连接doris会经常断开,如果长时间不执行sql,那么下一次执行sql的时候,navicat会再去连接doris,在生产上使用jdbv是非常快的,这块毋庸置疑。 2、这里我们使用的是insert的方式把数据插入到表中,这里只是演示,真实环境中我们不会直接使用insert的方式插入数据,这种效率非常的慢。后面我们会专门介绍doris的数据导入。








还没有评论,来说两句吧...