
在前面我们介绍过操作Delta Lake数据湖的时候,就像nosql一样,所有的操作都是追加操作而不是直接修改。因此基于上诉的原理,那么在Delta Lake内部肯定是维护了每一次修改的版本号,我们查询的时候默认是查询最新的版本号内容的。但是既然是大数据,那么我们有没有可能查询下以前某个时间段处理的数据呢,也就是我们读取的时候可以指定一个版本号,那么此时spark加载delta lake的时候就会返回指定版本的数据。这个在Delta Lake里面有一个很美的名字,叫做时间旅行,使用的示例如下:
val df = session.read.format("delta").option("versionAsOf", 1).load("file:///D:\\lake")
df.show()其实比较简单,就是在option里面添加一个versionAsOf的参数,后面跟的是版本号,我们想要哪个版本就会获取到哪个版本,例如获取最初的版本,那么版本号传递为0,获取第二个版本,那么版本号传递为1即可。看小效果:
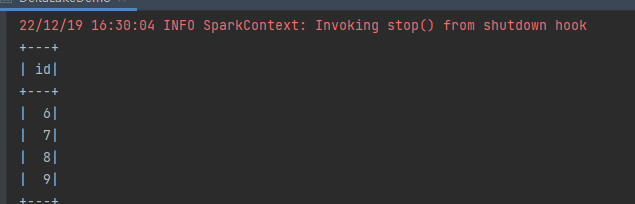
但是,在实际工作的场景里面我们几乎不会记得哪个版本号对应哪些内容对吧?所以那么如果我们想要获取之前的数据,我们还得挨个版本测试,这肯定是行不通的,因此Delta Lake为我们提供了另外一个参数,即timestampAsOf。使用示例如下:
val df = session.read.format("delta").option("timestampAsOf", "2022-12-19 15:30:00").load("file:///D:\\lake")
df.show()这样子的话,我们只需要记得想要获取哪一天对应的数据版本即可,在生产环境是不是很实用?再实验下看下效果:
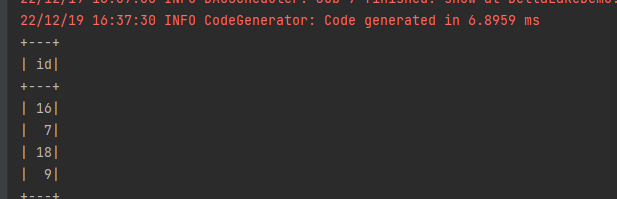
完全没有问题。
备注:
1、使用时间的方法,这个时间不能大于最近一个版本的时间,例如最近一个版本的时间是2022年12月19日15点30分00秒,我们这里如果时间设置为2022年12月19日15点40分00秒,这时候运行程序就会报错,但是我们设置为2022年12月19日15点29分00秒这个时间是可以的。也就是这个时间只能比最近的版本时间早,不能比最近版本时间晚。








还没有评论,来说两句吧...