
在数据湖的解决方案里面,Delta Lake和Apache Hudi是目前非常火爆的两种数据湖的解决方案,前面我们介绍了Delta Lake,这篇文章我们介绍下Apache Hudi。
Apache Hudi 摄取并管理通过 DFS (hdfs 或云存储)存储的大型分析数据集。Hudi 为大数据带来了流处理,在提供新数据的同时,比传统的批处理效率高出一个数量级。
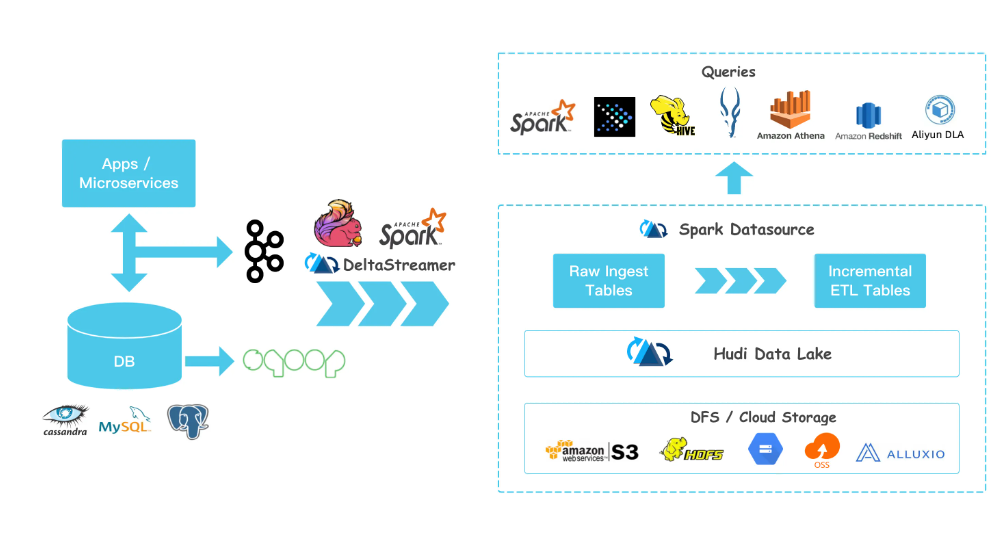
如果熟悉了前面的Delta Lake的话,那么学习起来Apache Hudi就非常快了。Apache Hudi有如下特点:
1、支持快速、可插入索引的 upsert。 2、支持回滚的原子发布数据。 3、写入器和查询之间的快照隔离。 4、保存点用于数据恢复。 5、使用统计管理文件大小和布局。 6、异步压缩行和列数据。 7、跟踪沿袭(lineage)的时间线元数据。 8、利用聚类优化数据湖布局。
在使用上,Apache Hudi与hdfs强依赖,我们可以看作是Apache Hudi是架构在hdfs上的一层数据中间件,底层数据还是存储在hdfs上的。
在框架上,Apache Hudi可以与Spark和Flink进行结合。相关的依赖版本如下:
Apache Hudi与Spark的版本对照表
| 序号 | Hudi版本 | spark版本 |
| 1 | 0.12.x | 3.3.x |
| 2 | 0.11.x | 3.2.x |
| 3 | 0.10.x | 3.1.x |
| 4 | 0.7.0-0.9.0 | 3.0.x |
| 5 | 1.6.0 and prior | 不支持 |
Apache Hudi与Flink暂时没有对照表,几乎可以看做是天然支持。








还没有评论,来说两句吧...