
在spark中,对于rdd进行sortByKey,那这个rdd一定是一个key-value pair 类型的rdd。同时这个函数就对key进行排序。在进行排序的时候我们可以选择使用升序排序还是降序排序。使用示例如下:
1、RDD.sortByKey(true) 代表按升序排序 2、RDD.sortByKey(false) 代表按降序排序
同时由于涉及到排序,那么整个rdd的数据都会在集群的节点之间进行迁移,因此这里一定会经过shuffle过程。会带来很大的网络开销。
这个函数的底层使用到了RangePartitioner,它可以使得相应的范围key数据分到同一个partition中,然后内部用到了mapPartitions对每个partition中的数据进行排序,而每个partition中的数据排序用到了标准的sort机制,避免了大量数据的shuffle。相当于内部做了一次小的优化。
下面使用sortByKey函数编写一个案例演示一下:
package org.example
import com.alibaba.fastjson.JSON
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().config(new SparkConf()).master("local[*]").appName("SparkWordCount").getOrCreate();
val sc = session.sparkContext
var list = List((1,"张三"),(9,"李四"),(6,"王五"),(7,"赵六"),(5,"田七"))
val data = sc.parallelize(list).sortByKey(false);
data.collect().foreach(println)
}
}最后的执行结果是:
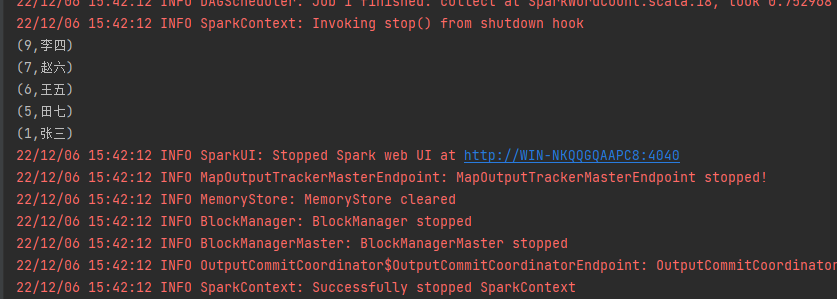
备注:
1、虽然sortbykey做了内部的小型优化,但是在实际使用的时候还是要观察下监控数据,留意数据倾斜的问题。








还没有评论,来说两句吧...