
在spark中,对于rdd的操作还提供了groupByKey,如果使用到了groupByKey,那么此时的rdd也一定是一个key-value pair类型的RDD。这里的groupByKey其实主要就是根据key值对数据进行分组,把相同key的数据对象组合在一起。针对groupByKey的用法如下:
1、groupByKey() 2、groupByKey(numPartition) 3、groupByKey(partitioner)
下面我们使用groupByKey来进行演示一下:
package org.example
import com.alibaba.fastjson.JSON
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().config(new SparkConf()).master("local[*]").appName("SparkWordCount").getOrCreate();
val sc = session.sparkContext
var list = List(("张三",1),("李四",2),("王五",3),("赵六",4),("田七",5),("赵六",6),("王五",7),("李四",8),("张三",9))
val data = sc.parallelize(list).groupByKey().collect().foreach(println)
}
}运行一下看下结果:
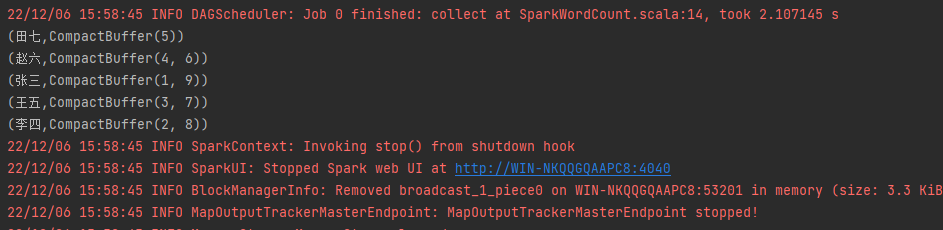
最后我们总结下groupByKey的特点:
1、groupByKey 是一个 transformation 转换操作,因此它的计算是惰性的; 2、它是一种宽依赖的操作,因为它从多个分区 shuffle 数据并创建另一个 RDD; 3、此操作开销很大,因为它不使用分区本地的组合器(combiner)来减少数据传输; 4、当需要对分组数据进行进一步聚合时,不建议使用; 5、groupByKey 总是会导致对 RDD 执行哈希分区








还没有评论,来说两句吧...