
在spark中,对于rdd进行reduceByKey,那这个rdd一定是一个key-value pair 类型的rdd。这个reduceByKey的主要作用就是把相同key的数据对象合并到一起。常见的应用场景是wordcount的计数场景。对于reduceByKey的使用如下:
1、reduceByKey(function):将使用现有的分区器生成散列分区输出。 2、reduceByKey(function, [numPartition]):将使用现有的分区器生成散列分区输出。 3、reduceByKey(partitioner, function):使用指定的 Partitioner 对象生成输出。
下面我们演示下使用reduceByKey函数示例:
package org.example
import com.alibaba.fastjson.JSON
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().config(new SparkConf()).master("local[*]").appName("SparkWordCount").getOrCreate();
val sc = session.sparkContext
var list = List(("张三",1),("李四",2),("王五",3),("赵六",4),("田七",5),("赵六",6),("王五",7),("李四",8),("张三",9))
val data = sc.parallelize(list).reduceByKey(_+_).collect().foreach(println)
}
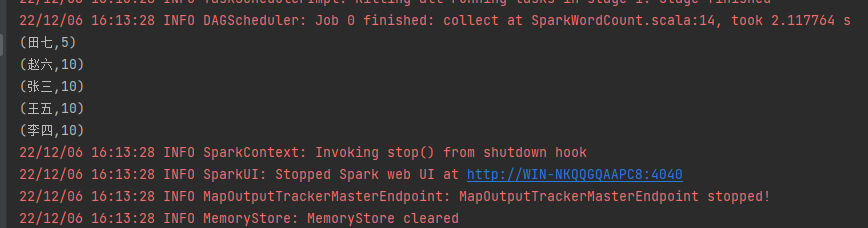
}执行下看下结果:








还没有评论,来说两句吧...