
在spark中,除了提供批处理(前面的文章主要是基于批处理来介绍的),还提供有流处理的方法,也就是我们可以从消息队列等场景里面源源不断的获取数据回来进行处理,此时spark的应用程序就成为了一个常驻进程,只要有数据流的写入,spark的transformation和action就会源源不断的动起来。从现在开始,我们介绍spark的流处理,首先介绍spark2.x版本之前的spark streaming流处理。
spark streaming流处理是spark提供的第一代的流处理方案,此时他是根据时间间隔,把写入进来的流变成了一个个微批的数据集(Dstream),然后通过rdd的方式再挨个进行批处理,所以在整体形式上,可以看做是把流处理演化成了批处理,整体的业务运算等算是近实时的形式。下面来一张图演示下这个过程:
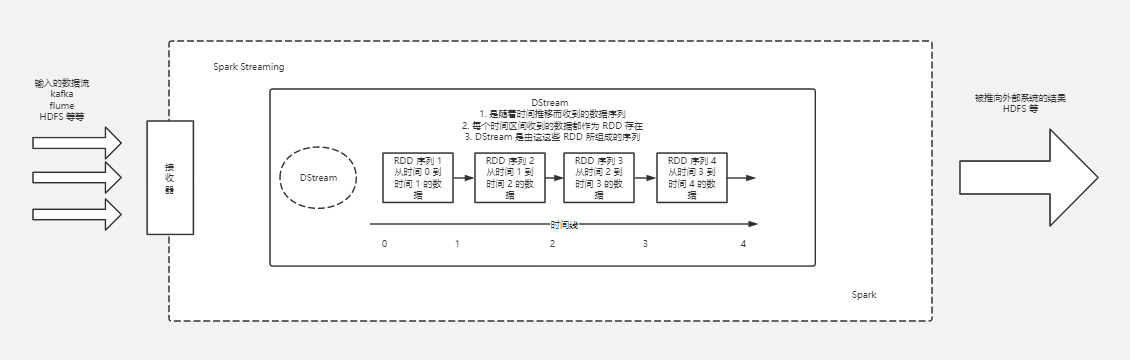
下面我们列举下spark streaming的案例演示一下,这里主要的演示场景是从kafka里面读取数据,并且使用spark streaming来计算wordcount,整体流程图如下:
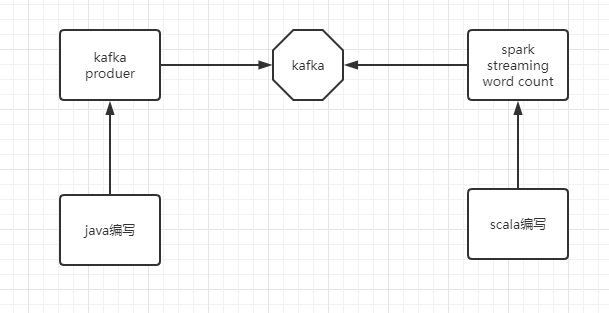
好了下面直接开始演示
一、创建一个maven项目,并且在poml中引入依赖
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>二、使用java语言编写一个kafka producer,每次发送一句英文短语
package org.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
public class KafkaProduer {
private static final Logger log = LoggerFactory.getLogger(KafkaProduer.class);
private static final String TOPIC = "sp_test";
private static final String BROKER_LIST = "192.168.31.10:9092";
/**
* 消息发送确认 0,只要消息提交到消息缓冲,就视为消息发送成功 1,只要消息发送到分区Leader且写入磁盘,就视为消息发送成功
* all,消息发送到分区Leader且写入磁盘,同时其他副本分区也同步到磁盘,才视为消息发送成功
*/
private static final String ACKS_CONFIG = "1";
/**
* 缓存消息数达到此数值后批量提交
*/
private static final String BATCH_SIZE_CONFIG = "1";
private static KafkaProducer<String, String> producer;
static {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_LIST);
properties.setProperty(ProducerConfig.ACKS_CONFIG, ACKS_CONFIG);
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, BATCH_SIZE_CONFIG);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<String, String>(properties);
}
public void send() {
try {
// 等待启动日志打印完后再发送消息
String message = "this is a test";
ProducerRecord<String, String> record = new ProducerRecord<String, String>(TOPIC, message);
producer.send(record, (recordMetadata, e) -> {
if (e != null) {
log.info("发送消息异常!");
System.out.println("发送失败:"+e.getMessage());
}
if (recordMetadata != null) {
// topic 下可以有多个分区,每个分区的消费者维护一个 offset
System.out.println("发送成功,分区是:"+recordMetadata.partition()+", 位置是: "+recordMetadata.offset());
log.info("消息发送成功:{} - {}", recordMetadata.partition(), recordMetadata.offset());
}
});
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != producer) {
producer.close();
}
}
}
public static void main(String[] args) {
KafkaProduer producer = new KafkaProduer();
producer.send();
}
}三、测试运行一下这里的kafka producer代码
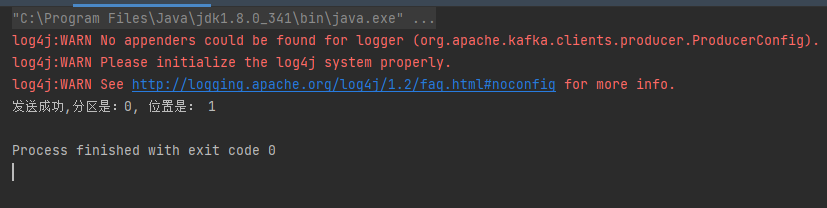
能发送成功,说明这里的kafka producer代码是没有任何问题的。
四、使用scala语言编写spark streaming应用程序案例,实现wordcount计数
package org.example
import org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object Demo {
def main(args: Array[String]): Unit = {
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
//声明一个spark conf,这里我们只设置app名称和master,其他的保持默认即可
val sparkConf = new SparkConf().setAppName("demo").setMaster("local[1]")
//使用spark straming的入口是使用spark context,而不是使用spark session,spark streaming是spark2.x版本之前的产物,spark session也是在spark2.x之后才出现的
val sc = new SparkContext(sparkConf)
//初始化sparkstreamingcontext,微批的时间间隔是5秒
val ssc = new StreamingContext(sc,Seconds(5))
//这里设置checkpoint检查点,方便后期恢复
ssc.checkpoint("file:///C:/Users/Administrator/Desktop/fsdownload/checkpoint") //设置检查点,如果存放在HDFS上面,则写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动Hadoop
//初始化kafka相关的参数
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.31.10:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (true: java.lang.Boolean)
)
//声明topic
val topics = Array("sp_test")
//创建一个spark streaming实例
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
//对每一个接受到的微批按照rdd的方式进行处理,这里我们的演示还是使用wordcount
stream.foreachRDD(rdd => {
//从kafka里面取值
val maped: RDD[(String, String)] = rdd.map(record => (record.key,record.value))
//获取kafka consumer接收到的每一行line
val lines = maped.map(_._2)
//空格进行切割
val words = lines.flatMap(_.split(" "))
//组成键值对
val pair = words.map(x => (x,1))
//实现reduce
val wordCounts = pair.reduceByKey(_+_)
//最后打印结果
wordCounts.foreach(println)
})
//开始运行流处理的监听
ssc.start
//使程序长期运行在单独的进程里面,如果没有下面这一行的话,程序会自动退出去,就不是一个常驻进程了。
ssc.awaitTermination
}
}五、运行下spark streaming程序,看下效果
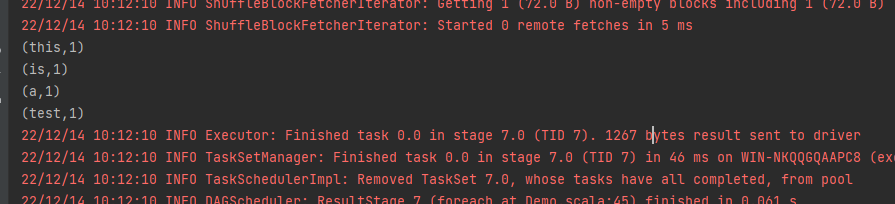
可以看到成功的实现了单词计数的功能,同时这里的spark streaming程序是一个常驻进程,日志会按照每一个微批的时间间隔进行打印输出。
备注:
1、spark streaming是spark2.x之前的产物,所以这里介绍不多,他的主要原理是使用微批的模式组成一个个Dstream,然后再进行RDD的处理。再来个流程图:
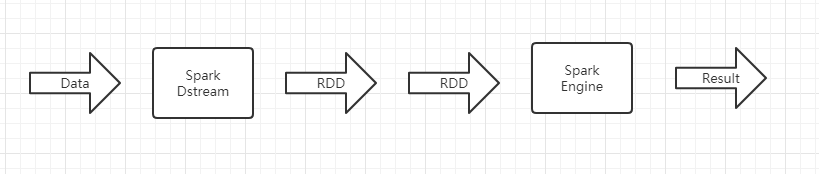
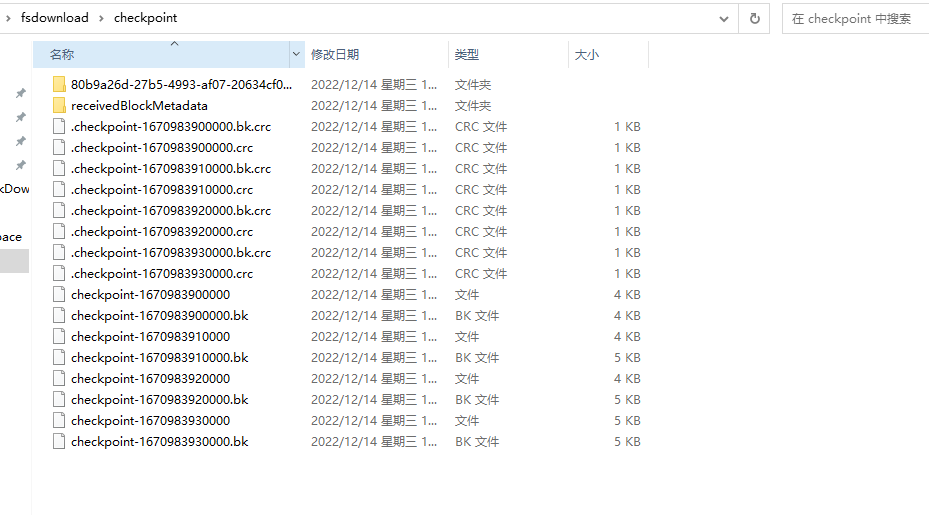
2、在流处理的过程中,一定要切记设置chekpoint目录,如果是file类型的话(也就是本地文件),需要以:file:/// 开头,这里记得是三个斜杠。我们看下chekpoin上记录了哪些信息
3、使用流处理的时候,切记添加此行代码,让程序处于一个常驻进程中。
ssc.awaitTermination
4、使用spark streaming进行流处理的时候,入口是spark context对象。
最后附上本案例的源码,登录后即可下载








还没有评论,来说两句吧...