
在前面我们演示了spark streaming的介绍,同时我们也提到过在spark2.x的部分里面提供了全新的结构化流处理也就是这里的spark structured streaming。这两个都是spark的流处理,但是从形象上来说是不同的东西,两者的差别是:
1、spark streaming里面使用的是rdd的数据处理方式,spark structured streaming里面使用的是datastream/dataset的数据处理方式 2、spark streaming使用的是微批聚合再进行批处理的方式,spark structured streaming使用的是类table表的方式来处理,相当于把所有的数据组成了一张大表,然后来一次数据就追加插入数据到这张表里面。 3、spark streaming的处理入口是spark context,spark structured streaming的处理入口是spark sql sessison.
整个spark structured streaming的流程图如下:
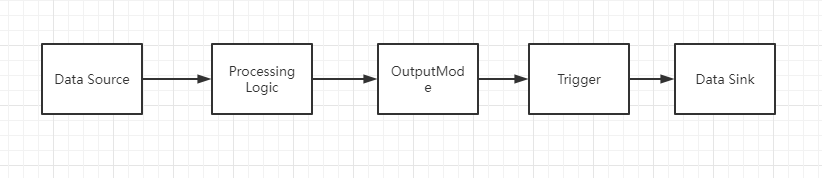
下面演示一下spark structured streaming的案例,还是一样的,通过kafka消息队列,然后在程序里面执行单词计数。
一、创建一个maven项目,并且在pom里面引入依赖信息
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>二、使用java语言编写一个kafka的生产者
package org.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
public class KafkaProduer {
private static final Logger log = LoggerFactory.getLogger(KafkaProduer.class);
private static final String TOPIC = "sp_test";
private static final String BROKER_LIST = "192.168.31.10:9092";
/**
* 消息发送确认 0,只要消息提交到消息缓冲,就视为消息发送成功 1,只要消息发送到分区Leader且写入磁盘,就视为消息发送成功
* all,消息发送到分区Leader且写入磁盘,同时其他副本分区也同步到磁盘,才视为消息发送成功
*/
private static final String ACKS_CONFIG = "1";
/**
* 缓存消息数达到此数值后批量提交
*/
private static final String BATCH_SIZE_CONFIG = "1";
private static KafkaProducer<String, String> producer;
static {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_LIST);
properties.setProperty(ProducerConfig.ACKS_CONFIG, ACKS_CONFIG);
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, BATCH_SIZE_CONFIG);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<String, String>(properties);
}
public void send() {
try {
// 等待启动日志打印完后再发送消息
String message = "this is a test";
ProducerRecord<String, String> record = new ProducerRecord<String, String>(TOPIC, message);
producer.send(record, (recordMetadata, e) -> {
if (e != null) {
log.info("发送消息异常!");
System.out.println("发送失败:"+e.getMessage());
}
if (recordMetadata != null) {
// topic 下可以有多个分区,每个分区的消费者维护一个 offset
System.out.println("发送成功,分区是:"+recordMetadata.partition()+", 位置是: "+recordMetadata.offset());
log.info("消息发送成功:{} - {}", recordMetadata.partition(), recordMetadata.offset());
}
});
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != producer) {
producer.close();
}
}
}
public static void main(String[] args) {
KafkaProduer producer = new KafkaProduer();
producer.send();
}
}三、测试运行下kafka produer的代码
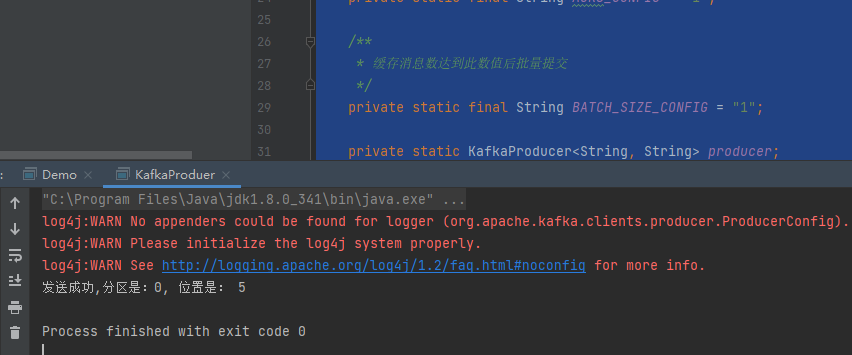
kafka生产者没有问题,这里其实使用的还是之前streaming演示里面的kafak生产者。
四、使用scala编写spark structured streaming的应用程序,实现单词计数
package org.example
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo {
def main(args: Array[String]): Unit = {
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
// 构建SparkSession实例对象
val session = SparkSession.builder().appName("demo").master("local[1]")
// 设置Shuffle分区数目
.config("spark.sql.shuffle.partitions", "3").getOrCreate()
// 导入隐式转换和函数库
import session.implicits._
val kafkaStreamDF: DataFrame = session.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.31.10:9092")
.option("subscribe", "sp_test")
.option("startingOffsets", "earliest")
//设置每批次消费数据最大值
.option("maxOffsetsPerTrigger", "100000")
.load()
//进行词频统计
val resultStreamDF: DataFrame = kafkaStreamDF
// 获取value字段的值,转换为String类型
.selectExpr("CAST(value AS STRING)")
// 转换为Dataset类型
.as[String]
// 过滤数据
.filter(line => null != line && line.trim.length > 0)
// 分割单词
.flatMap(line => line.trim.split("\\s+"))
// 按照单词分组,聚合
.groupBy($"value").count()
// 设置Streaming应用输出及启动
val query: StreamingQuery = resultStreamDF.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.option("numRows", "10")
.option("truncate", "false")
.option("checkpointLocation","C:\\Users\\Administrator\\Desktop\\fsdownload\\checkpoint")
.start()
query.awaitTermination() // 查询器等待流式应用终止
query.stop() // 等待所有任务运行完成才停止运行
kafkaStreamDF.checkpoint()
resultStreamDF.checkpoint()
}
}五、运行下效果看看
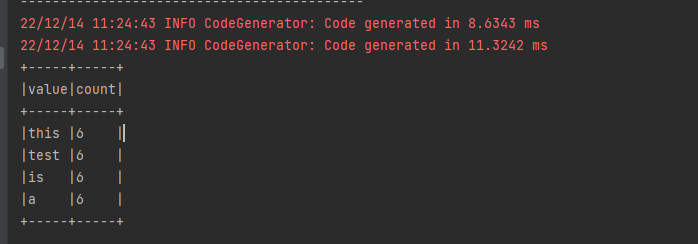
备注:
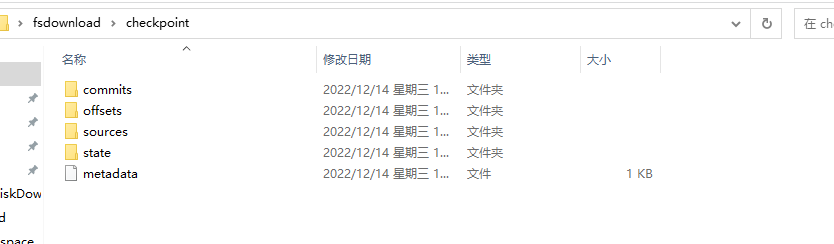
1、所有使用到流计算的地方都需要设置checkpoint,在spark structured streaming里面设置checkpoint的方式和之前是不一样的,这里设置checkpoint需要在writeStream里面的option进行设置。
.option("checkpointLocation","C:\\Users\\Administrator\\Desktop\\fsdownload\\checkpoint")同时在checkpoint里面存储的信息也和之前不一样,现在存储的信息如下:








还没有评论,来说两句吧...