
在使用spark流处理的时候,我们会经常涉及到时间窗口函数,但是由于生产环境中消息队列或者其他的数据源他不总是及时到达这条数据,举个例子:有一条10点10分产生的数据,他被及时的放入到了kafka里面,但是由于消费者或者其他跟不上等原因,这条数据结果是10点20分才到达消费者,此时这条数据按照常规业务来说,已经过了时间窗口(也就是在10点10分包含的时间段内应该被处理),此时这条数据不能被进入到新的时间窗口进行统计(也就是不能在10点20分这个时间断进行统计,如果统计的话数据就不对了),因此相当于这条数据我们就要被抛弃掉,此时我们就可以直接标记水印,spark的内部在进行流聚合的时候就会自动把这些数据删除掉。
设置水印还有一个问题,也就是及时的让数据被垃圾回收,避免集群内部出现内存不足的情况。
那么水印如何使用呢?其实就是短短的一句代码,如下:
df.withWatermark("cts","1 seconds")这个代码的含义是什么呢?
第一个参数这里我们列举的是cts,也就是df里面含有这个cts的值,一般这个参数都是时间戳的参数类型
第二个参数这里我们写的是1秒钟,也就是我们可以容忍这个数据比原计划晚1秒达到,超过1秒则抛弃掉,如果在延迟时间1秒内到达的话,我们还算他是有效数据,同时进行数据处理。
在面再用图的方式给大家介绍下:
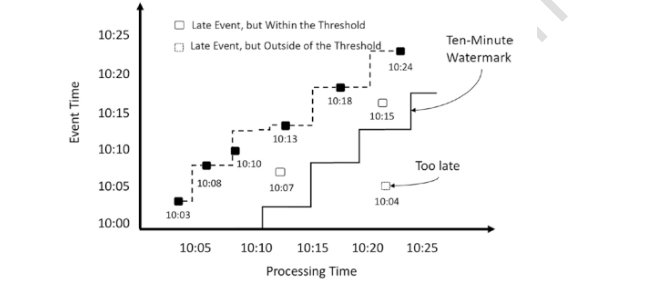
比如我们设置的水印是10分钟,name此时在10点10分的时候,有一条10点07分的数据来了,此时他在10点3分到10点13分之间,所以这个数据是有效的。
如果在10点20分来了一条数据是10点4分的。则此时已经超过10分钟了,这个数据就来的太晚了,直接抛弃掉。








还没有评论,来说两句吧...