
Elasticsearch我们只是是搜索引擎框架,在项目中使用非常频繁,在做大数据的环节里面,数据采集的速度会非常快,我们如何快速的把这些数据都存储到elasticsearch中呢?如何加快elasticsearch的索引速度呢?这篇文章我们就来介绍下。
首先先说下,在大数据的环节里面,我们数据采集和存储的流程一般如下:
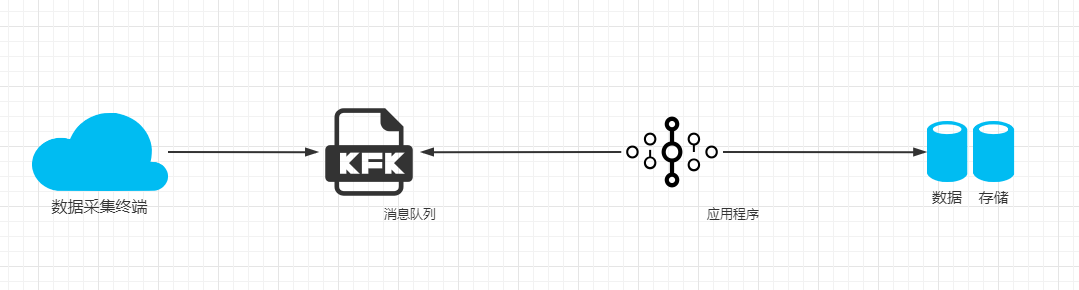
我们大多都是通过应用程序从消息队列里面进行数据消费的,所以这里假设数据存储室elasticsearch,我们该如何提升elasticsearch的索引速度呢?下面我们来介绍下详细的方法和措施
一、java程序使用bulk+多线程的方式进行数据的推送
由于项目的不同,线上环境的不同,服务器配置的不同,每一个document的数据不同,elasticsearch使用的版本不同,elasticsearch的配置不同,所以这里没有一个固定的bulk数据条数和多线程的线程数,因此在实际开发过程中,我们需要提前在针对生产环境的index做测试,挨个一步一步的把最有的bulk数量和多线程数量给测试出来,并且应用到生产环境中。具体测试步骤如下:
1、根据生产要求和数据预估量,创建相关的index mapping和分片数量
2、先使用单线程,bulk数量为100进行测试
3、再使用单线程,bulk数量为200这种,挨个100,100的新增,然后测试差不多合适的bulk数据量。
4、上诉bulk的数量应该固定了,那么此时增加到2个线程,进行测试。
5、再挨个 4个线程,8个线程,16个线程这样逐个增加,这样子计算出合适的多线程数量。
6、最后生产上的部署就可以使用上诉测试完的bulk数量和多线程数量。
建议:bulk每次的数据不能超过10M。
二、配置refresh时间
我们知道refresh就是把数据刷入到磁盘中,能供及时查询得到。如果当前的elasticsearch环境不是在线上实时性要求较高的环境下,可以调整下index.refresh_interval这个参数,把时间设置大一点,默认的是1s,生产上可以设置5s或者10s左右,适用于对实时性要求不高的场景
三、增大index buffer
我们直到数据是首先被写入indexbuffer的,然后再被刷入内存中,所以设置大一点index buffer,可以一次性存储更多的数据,增加了索引数据量。设置的属性是:indices.memory.index_buffer_size,那么这个值怎么计算呢? 一般我们是这样的,一个shard我们线上一般分配一个G内存,如果当前index有10个分片,则indices.memory.index_buffer_size的值我们设置就为10g。
四、禁止swapping
这个不用多数,在es的服务器上都要掉这个swapping。
五、禁止refresh和replia
这里其实就是在索引的时候关闭掉elasticsearch的一些功能,待索引完毕后再打开这些功能。但是这个主要应用于离线的环境,在线的环境是不适用的。因为禁止之后,虽然索引的速度快了。但是一旦打开,集群内就会产生副本和刷新,此时大量的网络io被占用,服务器内存和cpu的使用率也会飙升,同时会持续一段时间,此时的查询性能会非常差。而且还有这个这个功能一般我们都是人工操作,虽然可以做成自动化脚本,但是还得需要人员去核对。所以这个点的操作性比较差,适合完全离线的环境。








还没有评论,来说两句吧...