
今天有个业务需要用到elasticsearch做汉子的最大化匹配,因为这些数据来源于不同数据源,录入的文字有差异,需要把这不同的数据源根据名字关联起来,因此使用sql等去匹配度不会很高,用人工匹配数据量太大也是一件很麻烦的事情。所以这里我们使用elasticsearch的ik分词做个最大化匹配,再进行人工快速预览手动纠正个别数据。这篇文章给大家介绍下elasticsearch的ik分词安装和运用。
一、安装
1)首先需要有一个elasticsearch,这里我们使用的是7.7.0
2)7.7.0的es版本对应的ik应该也是7.7.0版本,所以我们直接在下载地址修改下版本号即可。下载地址是:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.7.0 这里大家需要什么版本就改修版本号即可。
3)下载下来后,在elasticsearch的plugins目录下创建一个ik的目录。
4)然后我们把下载的ik的zip包解压到这个ik目录下。

此时我们就可以进行测试了
crul http://192.168.31.20:9200/xq/_analyze
body是
{
"analyzer": "ik_max_word",
"text": "中华南大街438号怡景铭座小区"
}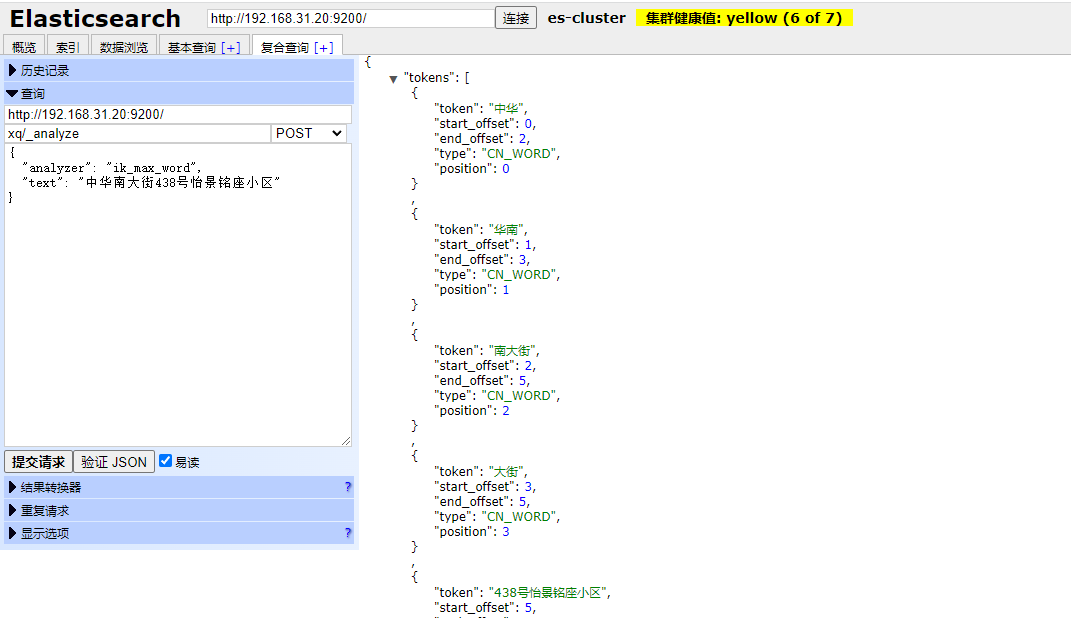
可以看到分词成功。
二、IK如何添加自定义词典?
1)进入到ik的config目录下
cd /mnt/elasticsearch-7.7.0/plugins/ik/config
2)在此目录下创建一个mydic.dic的文件,然后把自定义的词一行一个保存到这个mydic.dic的文件下。
3)在IKAnalyzer.cfg.xml文件里面配置下上面的mydic.dic
<!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">mydic.dic</entry>
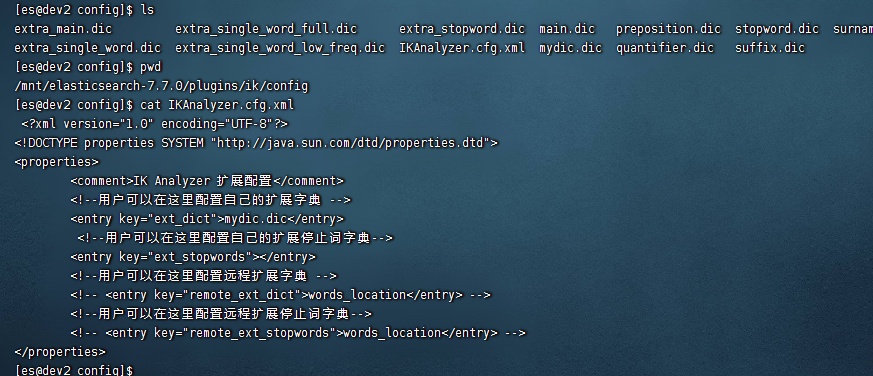
然后在重启,使用刚才的测试案例,即可匹配到ik分词的自定义分词了
三、如何配置远程自定义词典,实现热更新
1)把远程的词典做一个txt,例如:a.txt
2)把a.txt放在远程可以访问地方,例如nginx的路径下,访问路径是:http://192.168.31.30:8080/ik/a.txt
3)配置这里的remote_ext_dict
<entry key="remote_ext_dict">http://192.168.31.30:8080/ik/a.txt</entry>
4)然后重启es。
5)实现动态热加载分词的话,可以直接在a.txt里面进行追加即可。
6)es这个动态热加载大约1分钟左右生效。








还没有评论,来说两句吧...