
在前面《Elasticsearch优化系列(二)配置ZGC垃圾回收器》我们介绍了ZGC垃圾回收器的使用,在实际的使用过程中其实我们还是会遇到一些问题,本文记录下相关的问题。
1)查询耗时增加
关于查询耗时的增加,主要是由于发生了Allocation Stall。在传统的G1垃圾回收里面,当内存满了之后,会发生full gc。在ZGC垃圾回收器里面他没有full gc,但是他会发生Allocation Stall情况,这个Allocation stall主要是由于内存分配速率过快,导致ZGC回收不过来,触发部分线程的暂停挂起。这个效果和full gc的效果看起来是差不多的,最终都是影响查询性能。所以我们可以通过适当的调试来缓解这个问题。例如:
1、适当的使用-xmx调大堆内存,例如64G的内存服务器,在之前一般我们配置26G左右内存,这里可以调整到28 32G左右。 2、适当的调大ZAllocationSpikeTolerance(用来估算当前堆内存分配速率的),调大后可更快的触发GC。(配置的值是:-XX:ZAllocationSpikeTolerance=5) 3、根据不同的堆大小,调大GC线程数 ConcGCThread,降低并发标记时间。(配置的值是:-XX:ConcGCThreads=2) 4、配置动态GC线程,降低CPU的使用量。(配置的值是:-XX:+UseDynamicNumberOfGCThreads)
2)查询日志出现一些毛刺或者日志中发现有超大的暂停时间
这里我们通过1的配置之后,如果分析日志,还是能发现一些几十到几百乃至更大的超时时间的话,这时候我们可以通过关闭NUMA的auto Balance来环节这个问题。因为使用ZGC垃圾回收一般暂停时间很少超过10ms的。关闭NUMA的auto Balance方法是:
#更新内核,给所有内核加上该参数 grubby --update-kernel=ALL --args="numa=off" #重启服务器 reboot now #校验是否生效 cat /proc/cmdline
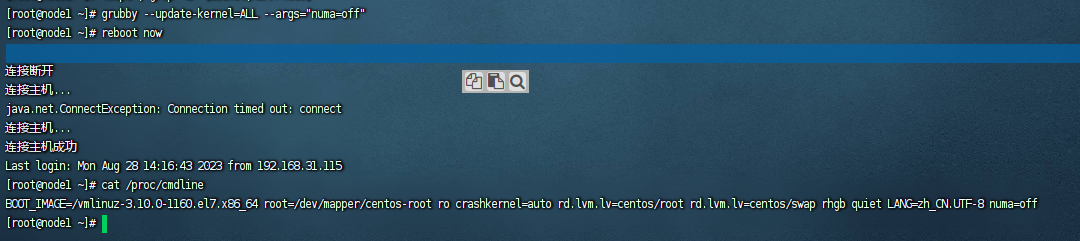
出现如上图所示就代表关闭了NUMA的anto Balance了。
3)开启压缩
在jdk15以上,jdk自带了压缩功能,当我们在elasticsearch的jvm.options文件中配置:
-XX:+UseCompressedClassPointers
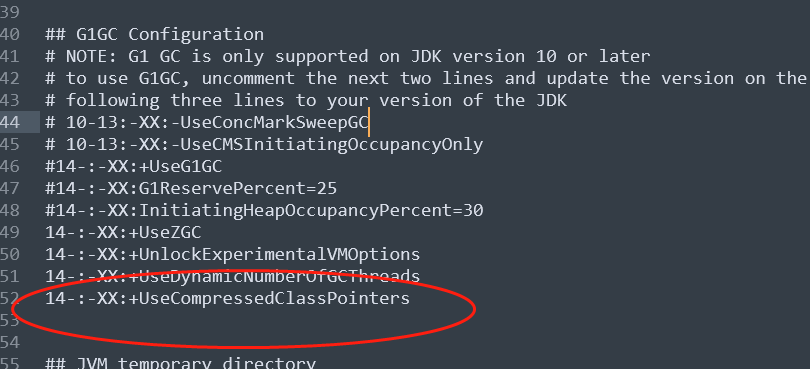
配置这个参数达标的是开启java的压缩,他通过减少所有对象的报头的大小,从而减少整体堆的使用。
但是这个参数在内存是32G以下的环境中使用效果较佳。服务器内存超过32G的话,一般也没必要配置这里的压缩。
4)把未使用的内存归还给操作系统
在elasticsearch集群配置的时候,我们知道一般我们是配置一半左右的内存给elasticsearch,剩余的部分留给操作系统。在一些实际的场景里面,有时候我们会定时更新大量数据,此时整个内存的使用率会突增。如果此时发生了查询,那么lucene会依靠操作系统来提升查询速度,所以我们可以尽量把不用的内存归还给操作系统,配置信息示例如下:
-XX:ZUncommitDelay=300 #(这里300的单位是秒) -XX:SoftMaxHeapSize=8g #这是软限制堆大小,这个大小一般不超过xmx的值。








还没有评论,来说两句吧...