
在日常中,除了使用正常的长讯之外,我们还会涉及到在Elasticsearch中进行数据统计。在elasticsearch中支持的聚合统计种类有:度量聚合统计和多桶型聚合统计。
度量聚合统计
是指一组文档的统计分科,可以得到最大值,最小值,平均值等结果
分桶型聚合统计
是指将匹配的文档切分为一个或多个桶,然后统计每个桶里面的文档数量
本篇文章主要介绍的是度量聚合统计。下面我们来演示一下。
一、准备一份indexmapping
put /devices
{
"mappings": {
"properties": {
"device_uuid": {
"type": "keyword"
},
"device_name": {
"type": "keyword"
},
"device_category": {
"type": "integer"
},
"device_score": {
"type": "double"
},
"device_cts": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}这里我们填写了设备名称,设备分类,设备分数,设备时间等几个参数,分别作用于不同的类型,用来演示接下来的聚合计算。
二、向devices索引里面插入数据
post /devices/_doc/1
{"device_uuid":"111","device_name":"设备111","device_category":"1","device_score":"1.01","device_cts":1669433306000}
post /devices/_doc/2
{"device_uuid":"222","device_name":"设备222","device_category":"1","device_score":"1.02","device_cts":1669433306000}
post /devices/_doc/3
{"device_uuid":"333","device_name":"设备333","device_category":"1","device_score":"1.03","device_cts":1669433306000}
post /devices/_doc/4
{"device_uuid":"444","device_name":"设备444","device_category":"2","device_score":"1.04","device_cts":1669433306000}
post /devices/_doc/5
{"device_uuid":"555","device_name":"设备555","device_category":"2","device_score":"1.05","device_cts":1669433306000}
post /devices/_doc/6
{"device_uuid":"666","device_name":"设备666","device_category":"2","device_score":"1.06","device_cts":1669433306000}
post /devices/_doc/7
{"device_uuid":"777","device_name":"设备777","device_category":"3","device_score":"1.07","device_cts":1669433306000}
post /devices/_doc/8
{"device_uuid":"888","device_name":"设备888","device_category":"3","device_score":"1.08","device_cts":1669433306000}
post /devices/_doc/9
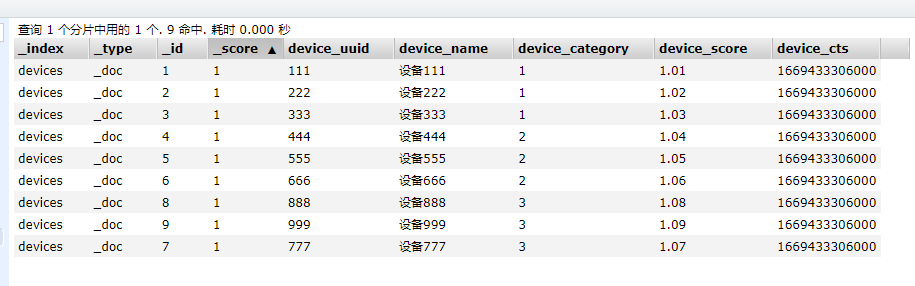
{"device_uuid":"999","device_name":"设备999","device_category":"3","device_score":"1.09","device_cts":1669433306000}存储数据的结果是:
三、使用度量聚合计算,求整个库的device_score的最大值,最小值,平均值,总和
post /devices/_search
{
"size": 0,
"aggs": {
"min_price": {
"min": {
"field": "device_score"
}
},
"max_price": {
"max": {
"field": "device_score"
}
},
"avg_price": {
"avg": {
"field": "device_score"
}
},
"sum_price": {
"sum": {
"field": "device_score"
}
}
}
}求出结果: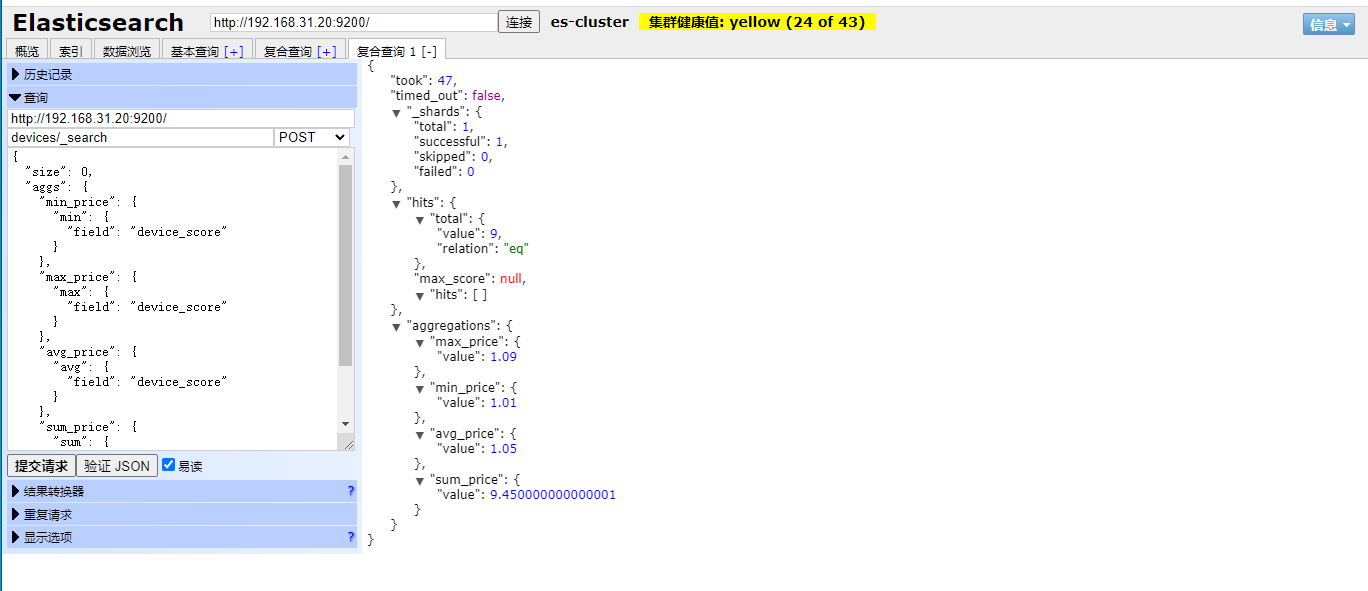
可以看到数据被正确的计算出来了。
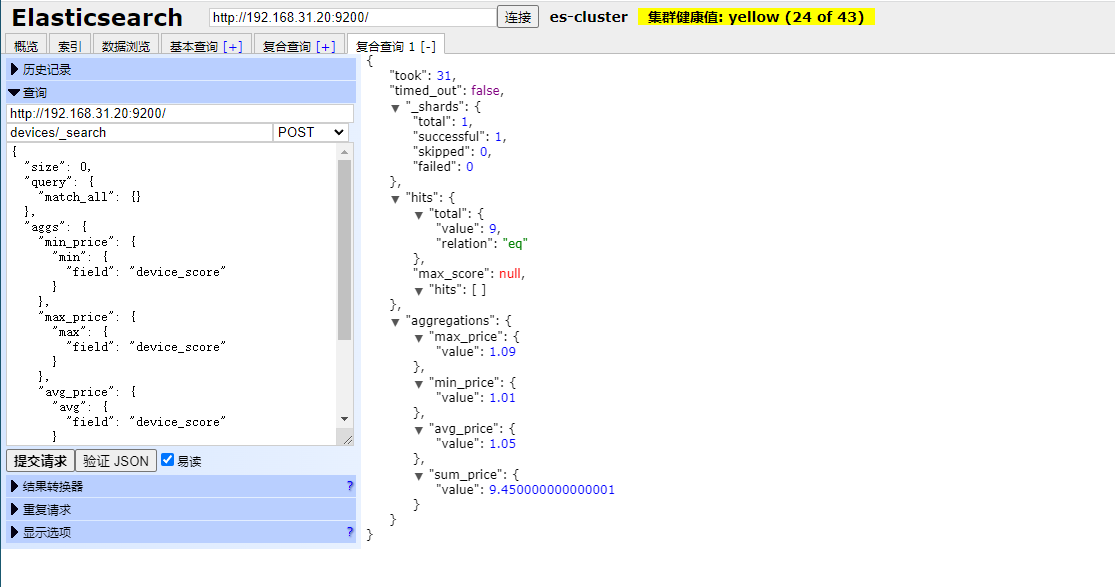
除了上面直接聚合之外,我们还可以添加查询条件,例如:
post /devices/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"min_price": {
"min": {
"field": "device_score"
}
},
"max_price": {
"max": {
"field": "device_score"
}
},
"avg_price": {
"avg": {
"field": "device_score"
}
},
"sum_price": {
"sum": {
"field": "device_score"
}
}
}
}
备注:
1、在进行度量聚合计算的时候,这边都在整个索引库和整个查询条件结果里面进行计算。
2、在度量聚合计算里面,可以单独进行聚合计算,也可以根据条件进行查询,然后在查询结果里面进行聚合。
3、使用度量聚合计算对种类这些是没有区分的,全是在一个结果集里面。
4、在使用聚合计算的时候如果涉及到小数会产生精度问题。








还没有评论,来说两句吧...