
前面我们介绍了千人千面的个性化推荐系统的大致情况,为了接下来的千人千面的系统讲解,这篇文章我们使用java的方式来演示一下千人千面的个性化推荐系统。让大家先看看千人千面的实现效果。
整个流程是:
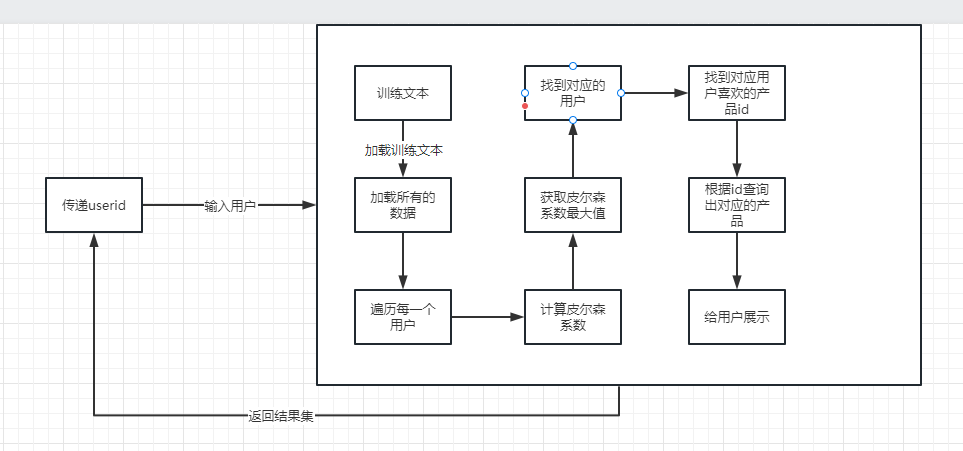
上图是一个简单的实现个性化推荐的整个流程图。下面我们就根据这个流程图来挨个进行演示一下:
一、准备训练数据集
这里我们既然要千人千面,那么肯定是需要获取用户的喜好的。所以这里我们先创建一些数据集来进行用户的定义,这里的数据集示例数据如下:
196 242 3 186 302 3 22 377 1 244 51 2 166 346 1
这份数据集的字段分别是:用户id,电影id,电影的打分分数。文末我们提供有数据集下载。
二、我们读取这里的数据,并且把他转换成DTO
2.1、首先声明一下DTO的类型,名为RelateDTO
/**
* 关系数据
*
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode
@ToString
@Builder
public class RelateDTO {
//用户id
private Integer useId;
//电影id
private Integer moduleId;
//打分
private Integer index;
}2.2、然后编写读取文件的方法,把他转换成DTO
/**
* 方法描述: 读取基础数据
*
*/
public static List<RelateDTO> getData() {
folderPath = new FileDataSource().getClass().getResource("/ml-100k").getPath();
List<RelateDTO> relateList = Lists.newArrayList();
try {
// 读取文件,这里使用commom-io包进行读取即可
List<String> lines = FileUtils.readLines(new File(folderPath + "\\u.data"), "UTF-8");
for (String line : lines) {
String[] items = line.split("\t");
// 用户id
Integer userId = Integer.parseInt(items[0]);
// 电影id
Integer movieId = Integer.parseInt(items[1]);
// 用户对电影的打分分数
Integer rating = Integer.parseInt(items[2]);
RelateDTO dto = RelateDTO.builder().useId(userId).moduleId(movieId).index(rating).build();
relateList.add(dto);
}
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return relateList;
}三、编写皮尔森计算函数
3.1、用户数据归类
我们从原始数据文件里面可以看到对应的是三个字段,用户id,电影id,用户的打分,那么我们需要把每一个用户所有的数据都进行下归类,代码如下:
// 根据用户id,对用户打分进行分组,形如{"userId":1,"user_movies_rates":[{"index":4,"moduleId":61,"useId":1},{"index":3,"moduleId":189,"useId":1}]}
Map<Integer, List<RelateDTO>> userMap = list.stream().collect(Collectors.groupingBy(RelateDTO::getUseId));3.2、编写皮尔森计算函数
/**
* 计算两个序列间的相关系数
*
* @param xList 这个是非当前用户的爱好打分
* @param yList 这个是当前用的爱好打分
* @return
*/
private double pearson_dis(List<RelateDTO> xList, List<RelateDTO> yList) {
// x坐标
List<Integer> xs = Lists.newArrayList();
// y坐标
List<Integer> ys = Lists.newArrayList();
xList.forEach(x -> {
yList.forEach(y -> {
// 如果两个数据的电影id相同的话
if (x.getModuleId() == y.getModuleId()) {
// 把他们的打分情况加进去
xs.add(x.getIndex());
ys.add(y.getIndex());
}
});
});
// 上面形成了一个新的x,y坐标,x坐标还是非当前用户的,y坐标是当前用户的,例如:x集合为[5,2],y集合为[5,4] 备注:这个数据是第一组的数据
return getRelate(xs, ys);
}/**
* 方法描述: 皮尔森(pearson)相关系数计算,协同过滤算法中的皮尔森相关系数公式
*
*
* (1)、当相关系数为0时,X和Y两变量无关系。
*
* (2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
*
* (3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
*
*
* 通常情况下通过以下取值范围判断变量的相关强度: 相关系数 : 0.8-1.0 极强相关 0.6-0.8 强相关 0.4-0.6 中等程度相关
* 0.2-0.4 弱相关 0.0-0.2 极弱相关或无相关
*
*/
public static Double getRelate(List<Integer> xs, List<Integer> ys) {
// [5,2],[5,4]
int n = xs.size();
double Ex = xs.stream().mapToDouble(x -> x).sum();
double Ey = ys.stream().mapToDouble(y -> y).sum();
double Ex2 = xs.stream().mapToDouble(x -> Math.pow(x, 2)).sum();
double Ey2 = ys.stream().mapToDouble(y -> Math.pow(y, 2)).sum();
double Exy = IntStream.range(0, n).mapToDouble(i -> xs.get(i) * ys.get(i)).sum();
double numerator = Exy - Ex * Ey / n;
double denominator = Math.sqrt((Ex2 - Math.pow(Ex, 2) / n) * (Ey2 - Math.pow(Ey, 2) / n));
if (denominator == 0)
return 0.0;
return numerator / denominator;
}3.3、把计算出来的所有皮尔森相关系数进行排序
/**
* 在给定userId的情况下,计算其他用户和它的相关系数并排序
*
* @param userId
* @param list
* @return
*/
private Map<Double, Integer> computeNearestNeighbor(Integer userId, List<RelateDTO> list) {
// 根据用户id,对用户打分进行分组,形如{"userId":1,"user_movies_rates":[{"index":4,"moduleId":61,"useId":1},{"index":3,"moduleId":189,"useId":1}]}
Map<Integer, List<RelateDTO>> userMap = list.stream().collect(Collectors.groupingBy(RelateDTO::getUseId));
Map<Double, Integer> distances = new TreeMap<>();
userMap.forEach((k, v) -> {
// 这里根据group之后的数据,计算不同于传递进来的userid的用户的距离数据
if (k != userId) {
// 使用皮尔森系数相关公式计算相关度,
double distance = pearson_dis(v, userMap.get(userId));
// 最后行程一个相关度+userid的map集合,例如:(0.2,5)
distances.put(distance, k);
}
});
return distances;
}四、获取最相关的相关性数据
// 上面的相关度已经使用treemap进行排序了,默认是从小到大,在皮尔森算法中,相关度为1或者-1的时候,相关度是最大的,也就是皮尔森计算的是绝对值,所以我们一般取第一个用户即可。 Integer nearest = distances.values().iterator().next();
这个方法获取到的就是最相关的那一个用户。所以这里的nearest是最相关的用户id。
五、找出相关的电影列表进行推荐
5.1、获取相关用户看过的电影
上面我们获取到了最相关的用户,同时在前面也根据用户进行了group by分组操作。因此这里我们根据用户id,获取出当前用户看过的电影
// 最近邻用户看过电影列表 List<Integer> neighborItemList = userMap.get(nearest).stream().map(e -> e.getModuleId()).collect(Collectors.toList());
5.2、获取当前用户看过的电影
当前用户看过的电影就不需要再推荐了
// 指定用户看过电影列表 List<Integer> userItemList = userMap.get(userId).stream().map(e -> e.getModuleId()).collect(Collectors.toList());
5.3、找出两个电影的差集作为电影的推荐列表
把相似用户看过的电影排除掉当前用户已经看过的,就是我们最后想要得到的电影列表
// 找到最近邻看过,但是该用户没看过的电影,计算推荐,放入推荐列表
List<Integer> recommendList = new ArrayList<>();
for (Integer item : neighborItemList) {
if (!userItemList.contains(item)) {
recommendList.add(item);
}
}
Collections.sort(recommendList);以上我们就获取到了完整的电影推荐列表了。
六、测试获取对应的电影列表
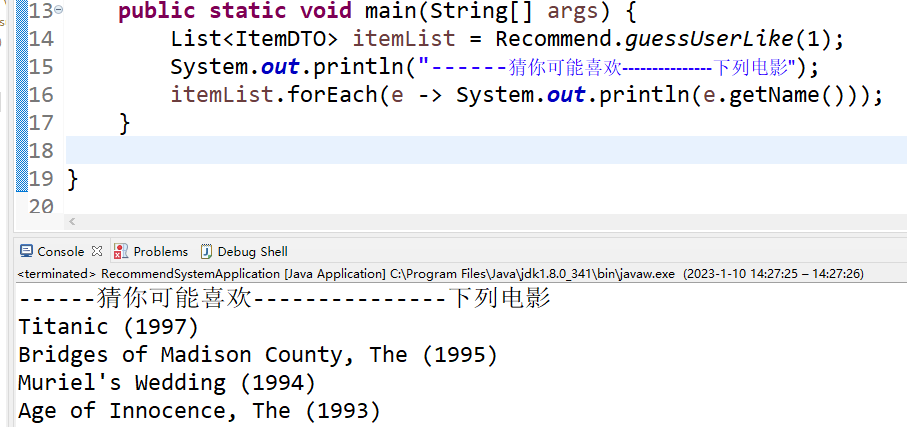
public static void main(String[] args) {
List<ItemDTO> itemList = Recommend.guessUserLike(1);
System.out.println("------猜你可能喜欢---------------下列电影");
itemList.forEach(e -> System.out.println(e.getName()));
}6.1、这里我们测试传入用户id为1的用户,看下他推荐的是什么电影
6.2、这里我们测试传入用户id为2的用户,看下他推荐的是什么电影

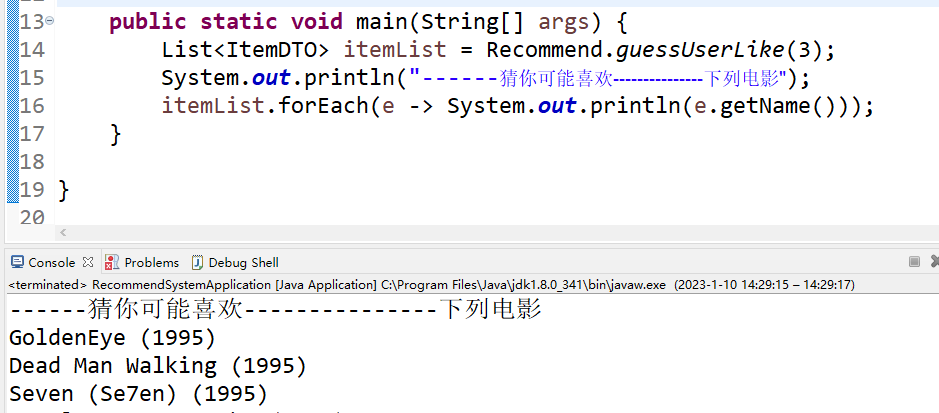
6.3、这里我们测试传入用户id为3的用户,看下他推荐的是什么电影
以上我们可以看到每个人获取到的数据都是不一样的,这样就完成了很简单的千人千面的个性化推荐展示。
备注:
1、后期我们会演示通过大数据的方式完成千人千面的个性化展示,使其更趋近于生产环境的使用,本文主要是简单的编写一个演示示例,为了给大家看下整个千人千面的个性化展示的效果。
最后附上本文的代码下载和数据集下载,登录就可以看到。








还没有评论,来说两句吧...