
在前面的文章《分布式调度系统Apache DolphinScheduler系列(四)配置datax的增量同步》我们已经介绍过了datax中使用增量同步,但是这里的增量同步会涉及到一些数据问题,因为他只能通过全局设置的时间为起点进行增量同步,在数仓的建设里面,这个特性会导致很多重复性的数据,如果是aggregate模型的话,还会导致数据错误,所以本文的话,我们介绍一种很实用的方式,这也是在生产环境中使用范围很广的方式。
这个方式其实逻辑比较简单,主要利用的是:
1、dolphinScheduler任务之间传递参数 2、dolphinScheduler的前置任务
所以基于这两点,我们来介绍下整个增量同步的流程:
1、先准备一个A数据源
2、再准备一个B数据源
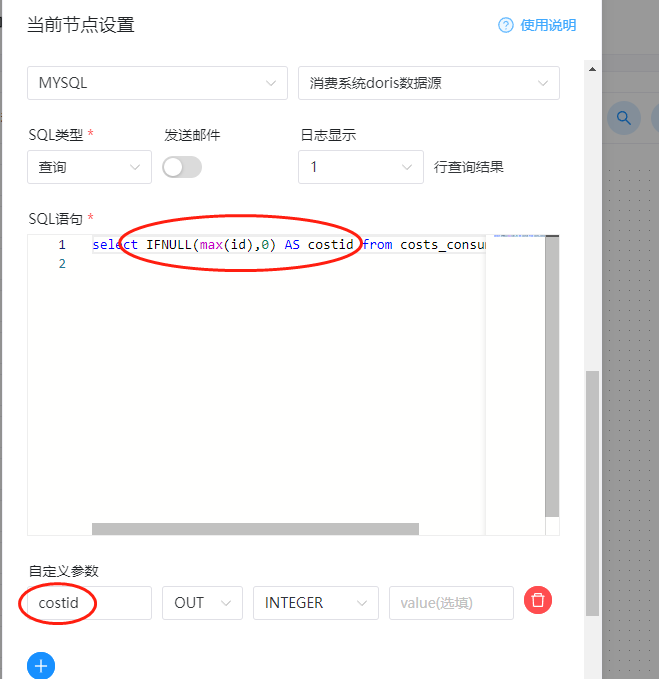
3、使用dolphinScheduler首先创建一个sql的任务,从B数据源查询最大的id。
4、把查询到的id作为自定义参数,方向为out,向外输出出去。
5、再建立一个datax的任务,编写json配置。
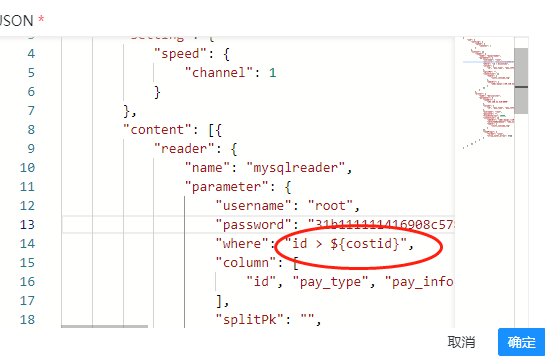
6、json配置从A数据源查询的时候添加where条件 id > ${id}
7、测试运行下面我们来实战演示一下,这里主要是演示mysql从datax里面读取数据,所以这里的话我们首先建立一个sql任务从doris中查询最大的id
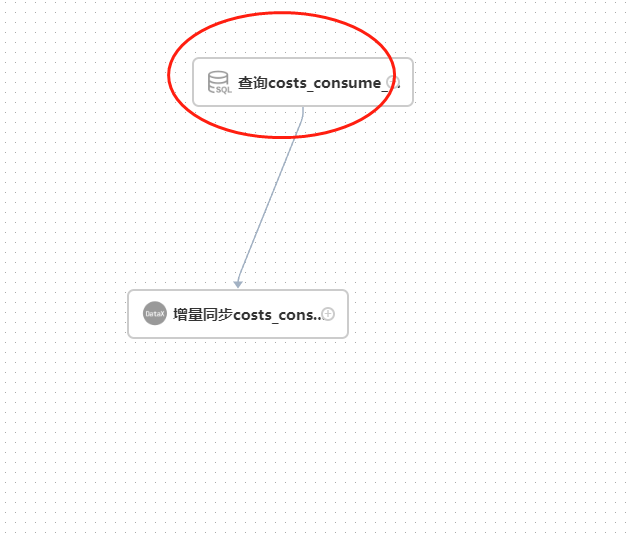
在编辑这个任务的时候,我们需要把id查询出来,并且把id作为out类型,示例如下:
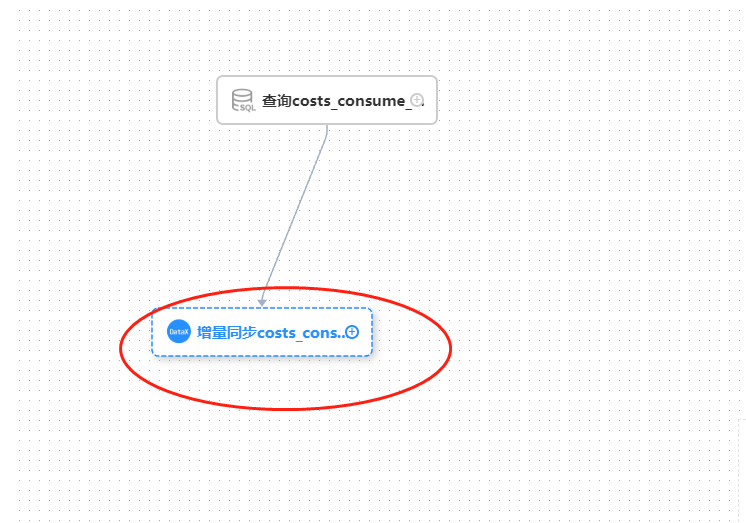
接着我们再创建一个datax的任务
在json的配置文件里面获取这个变量值:
然后我们把在前置任务里面,把前面的sql任务添加为前置任务:
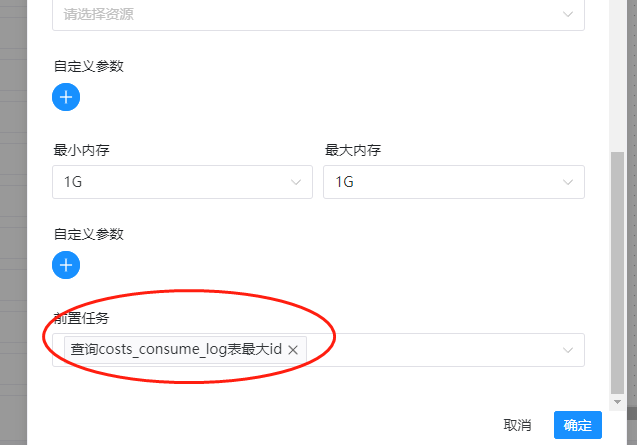
最后我们保存,两个任务之间就建立了关联性了。
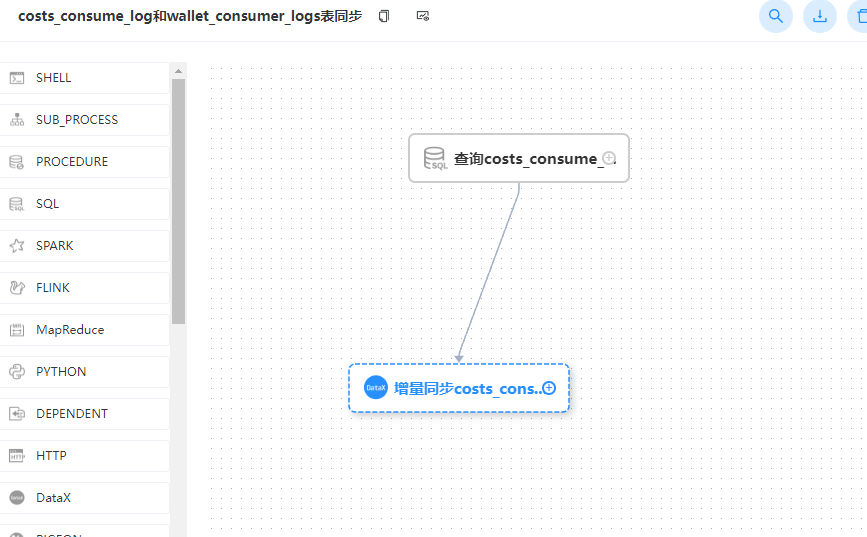
然后我们运行一下,可以看到运行是成功的:
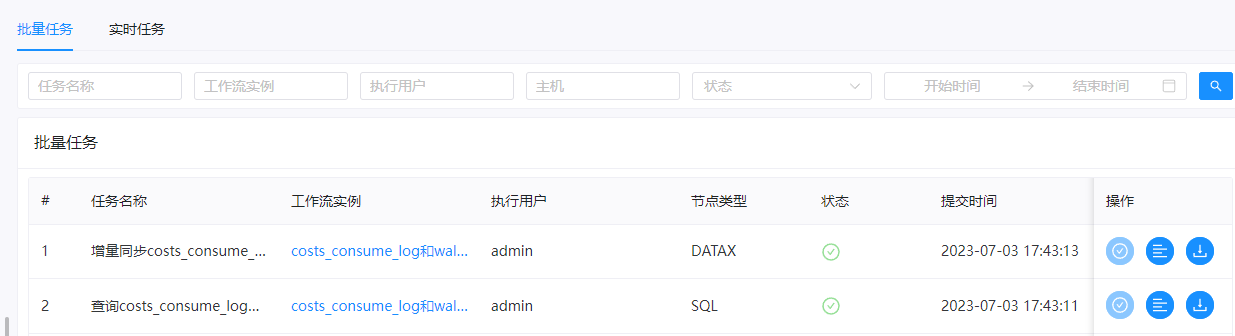
对应的doris中也有数据。
备注:
1、以上方法我们合理的利用任务之间传递参数。
2、以上方法我们合理的创建一条任务链
3、以上方法我们可以实现多样化的增量数据同步。








还没有评论,来说两句吧...