
在doris中使用join查询的时候,我们还可以利用Runtime Filter进行优化。他的原理是在join查询的时候会使用Filter对数据进行过滤,然后在各节点扫描表数据的时候可以减少扫描量,以此达到提高join优化查询的效率。
在使用Runtime Filter的时候,我们可以指定使用如下的filter,例如:
一、IN or Bloom Filter
根据右表在执行过程中的真实行数,由系统自动判断使用 IN predicate 还是 Bloom Filter 默认在右表数据行数少于1024时会使用IN predicate(可通过session变量中的runtime_filter_max_in_num调整),否则使用Bloom filter。
二、Bloom Filter
Bloom Filter: 有一定的误判率,导致过滤的数据比预期少一点,但不会导致最终结果不准确,在大部分情况下Bloom Filter都可以提升性能或对性能没有显著影响,但在部分情况下会导致性能降低。 备注: 1、Bloom Filter构建和应用的开销较高,所以当过滤率较低时,或者左表数据量较少时,Bloom Filter可能会导致性能降低。 2、目前只有左表的Key列应用Bloom Filter才能下推到存储引擎,而测试结果显示Bloom Filter不下推到存储引擎时往往会导致性能降低。 3、目前Bloom Filter仅在ScanNode上使用表达式过滤时有短路(short-circuit)逻辑,即当假阳性率过高时,不继续使用Bloom Filter,但当Bloom Filter下推到存储引擎后没有短路逻辑,所以当过滤率较低时可能导致性能降低。
三、MinMax Filter
包含最大值和最小值,从而过滤小于最小值和大于最大值的数据,MinMax Filter的过滤效果与join on clause中Key列的类型和左右表数据分布有关。 备注: 1、当join on clause中Key列的类型为int/bigint/double等时,极端情况下,如果左右表的最大最小值相同则没有效果,反之右表最大值小于左表最小值,或右表最小值大于左表最大值,则效果最好。 2、当join on clause中Key列的类型为varchar等时,应用MinMax Filter往往会导致性能降低。
四、IN predicate
根据join on clause中Key列在右表上的所有值构建IN predicate,使用构建的IN predicate在左表上过滤,相比Bloom Filter构建和应用的开销更低,在右表数据量较少时往往性能更高。 默认只有右表数据行数少于1024才会下推(可通过session变量中的runtime_filter_max_in_num调整)。 备注: 1、目前IN predicate已实现合并方法。 2、当同时指定In predicate和其他filter,并且in的过滤数值没达到runtime_filter_max_in_num时,会尝试把其他filter去除掉。原因是In predicate是精确的过滤条件,即使没有其他filter也可以高效过滤,如果同时使用则其他filter会做无用功。目前仅在Runtime filter的生产者和消费者处于同一个fragment时才会有去除非in filter的逻辑。
那如何使用Runtime Filter呢?
其实主要是在session里面设置下runtime_filter_mode这个属性,例如:
set runtime_filter_type="IN";
这个值在doris中默认使用的是:IN or Bloom Filter,根据官方的建议同时使用Bloom Filter、MinMax Filter、IN predicate时性能更高。所以一般我们直接使用(全部用这个,不要改动):
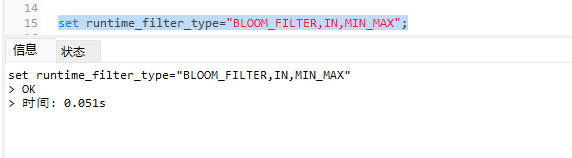
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
下面我们实战演示下:
一、创建一张学生表,并插入一些数据
CREATE TABLE students (id INT, name varchar(255),class_id int) DISTRIBUTED BY HASH (id) BUCKETS 1 PROPERTIES("replication_num" = "1");
insert into students values(1,'张三',1);
insert into students values(2,'李四',2);
insert into students values(3,'王五',3);二、创建一张班级表,并插入一些数据
CREATE TABLE classs (id INT, name varchar(255)) DISTRIBUTED BY HASH (id) BUCKETS 1 PROPERTIES("replication_num" = "1");
insert into classs values(1,'小一班');
insert into classs values(2,'小二班');三、执行下join sql
select students.* from students join classs on students.class_id = classs.id
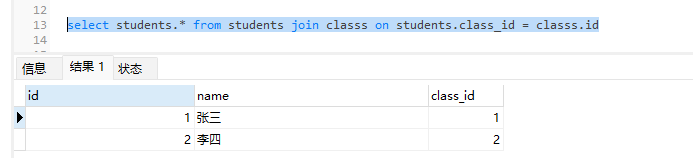
然后我们来分析下这个join的sql
explain select students.* from students join classs on students.class_id = classs.id;
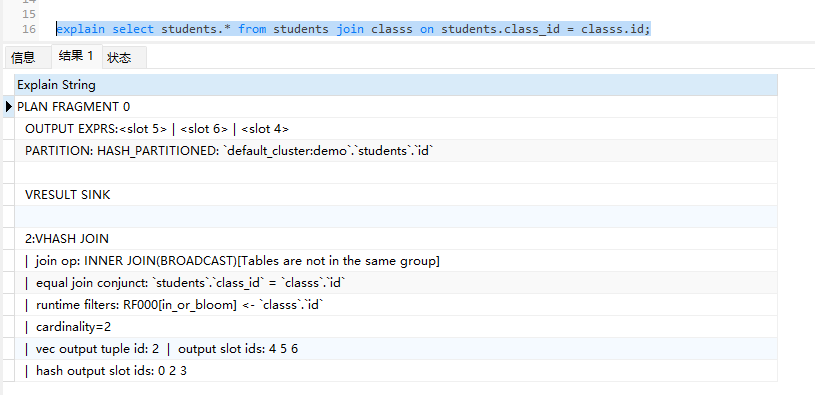
可以看到系统返回了:
runtime filters: RF000[in_or_bloom] <- `classs`.`id`
也就是系统默认使用的runtime filters是IN Or Bloom Filter。
此时我们按照惯例,设置使用所有的filter
set runtime_filter_type="BLOOM_FILTER,IN,MIN_MAX";
然后我们再分析下上一条sql
explain select students.* from students join classs on students.class_id = classs.id;
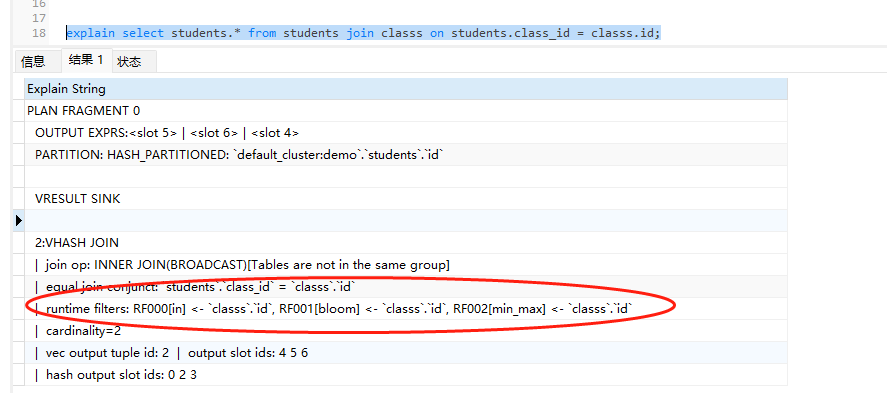
可以看到返回了
| runtime filters: RF000[in] <- `classs`.`id`, RF001[bloom] <- `classs`.`id`, RF002[min_max] <- `classs`.`id`
说明使用的是新的filter。此时doris会选择最优的filter进行join优化。然后我们在doris的profile分析里面可以看到两种不同的filter的耗时。
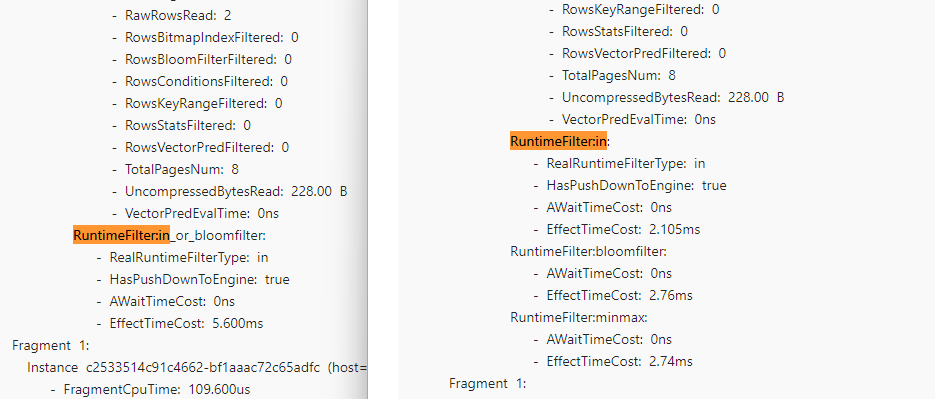
可以看到使用固定设置比默认的in_or_bloomfilter耗时更低。








还没有评论,来说两句吧...