
在前面我们介绍过rollup,rollup相当于可以支持在Aggregate数据模型和Unique数据模型的表里面做预聚合的操作。在Duplicate里面是没有预聚合的,因此rollup只能起到更改字段顺序让其命中索引的作用。那么如果我们想要在原始数据这种Duplicate表里面做聚合怎么办呢?这就是要用到我们今天介绍的物化视图。
doris中物化视图就是将原始表的数据进行一个预计算,然后把结果集保存到doris中,如果在原始表里面进行预计算类的sql查询的话,doris会自动去物化视图的表里面查询结果,极大的提升了查询效率。
物化视图有哪些优势呢?
1、对于那些经常重复的使用相同的子查询结果的查询性能大幅提升。 2、Doris自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证base 表和物化视图表的数据一致性。无需任何额外的人工维护成本。 3、查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。
下面我们演示下物化视图的具体使用。
一、创建一张用户消费表,并且插入一批数据:
CREATE TABLE `costs` ( `cost_id` int(11) NULL COMMENT "消费记录id", `store_id` int(11) NULL COMMENT "店铺id", `product_id` int(11) NULL COMMENT "产品id", `user_id` int(11) NULL COMMENT "用户id", `buy_nos` int(32) NULL COMMENT "购买数量", `costs_total` decimal(10,2) NULL COMMENT "消费总金额", `cost_cts` DATETIME NULL COMMENT "消费时间" ) ENGINE=OLAP DUPLICATE KEY(`cost_id`,`store_id`,`product_id`,`user_id`,`buy_nos`,`costs_total`,`cost_cts`) COMMENT "OLAP" DISTRIBUTED BY HASH(`cost_id`) BUCKETS 3 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2" );
插入数据的sql是:
insert into costs values(1,1,1,1,5,2.08,'2022-11-11 09:00:00'); insert into costs values(2,5,1,6,8,3.18,'2022-11-12 09:00:00'); insert into costs values(3,7,1,2,2,4.99,'2022-11-13 09:00:00'); insert into costs values(4,2,1,9,3,5.66,'2022-11-11 09:00:00'); insert into costs values(5,1,1,3,3,6.08,'2022-11-11 09:00:00'); insert into costs values(6,3,1,2,5,7.28,'2022-11-16 09:00:00'); insert into costs values(7,2,1,2,5,8.38,'2022-11-09 09:00:00'); insert into costs values(8,2,1,3,5,3.08,'2022-11-10 09:00:00');
插入结果如下:
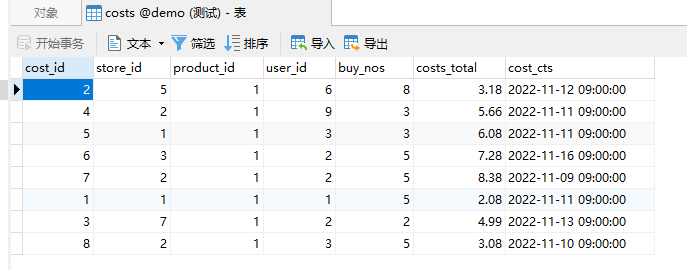
二、需求
这里我们的需求是查询某个人当天的消费总金额。
所以我们的sql应该是怎么样的呢?统计的sql如下:
select user_id,sum(costs_total) from costs GROUP BY user_id
思考一下,这里我们是相当于一张明细表,是没有做任何预计算的,此时我们在查询的时候,按照常理来说那肯定是需要进行实时计算的。那么我们有没有可能让其进行预计算,也就是在插入数据的时候就把结果计算出来,在查询的时候就不需要进行实时计算了。此时我们就需要使用到物化视图,这里我们创建一个物化视图:
create materialized view costsview as select user_id,sum(costs_total) from costs GROUP BY user_id
执行成功
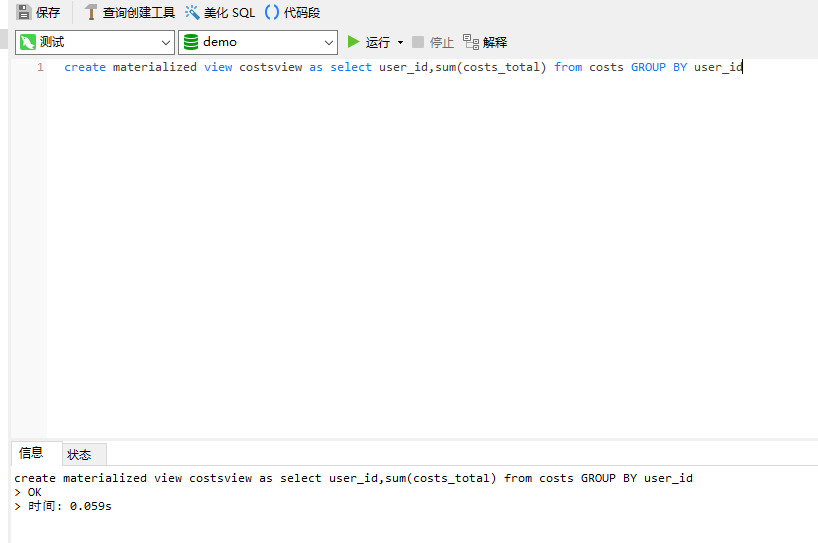
然后我们看下物化视图是否简历成功了。
desc costs all;
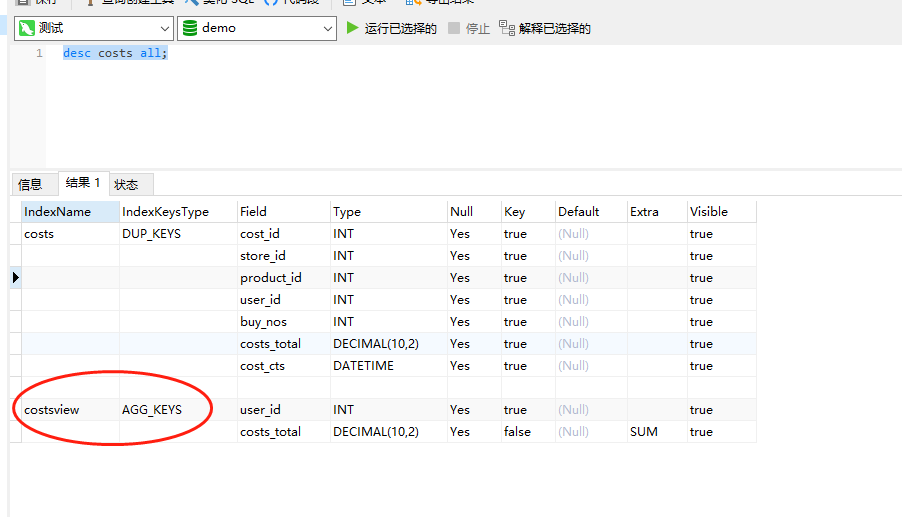
然后我们查询一下具体的数据,查看下是否使用了物化视图的结果。
explain select user_id,sum(costs_total) from costs GROUP BY user_id
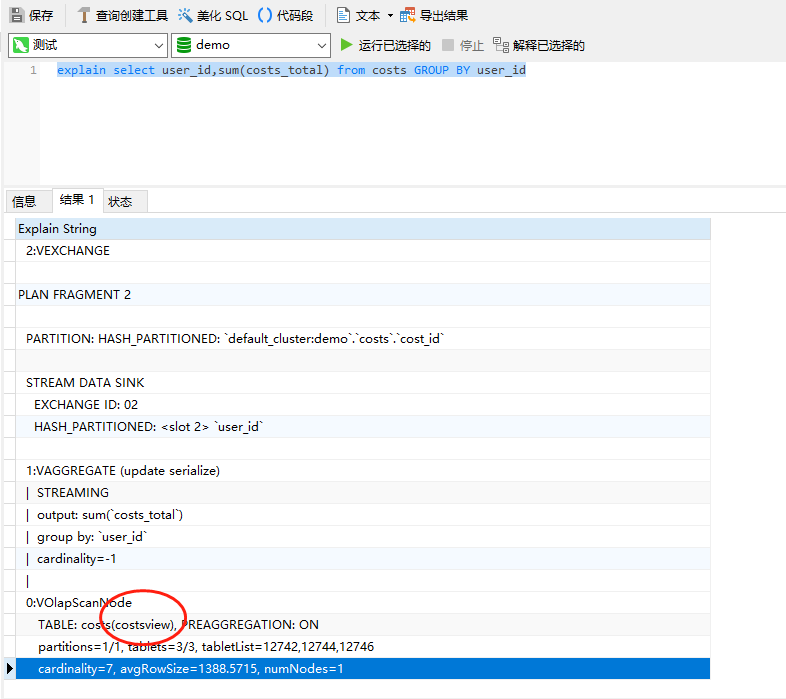
可以看到途中括号里面使用的就是物化视图的表。我们再换个其他的sql语句,例如:
explain select product_id,sum(costs_total) from costs GROUP BY product_id
这个sql我们是没有创建物化视图的,所以期望是在原始表里面进行查询,我们看下结果:
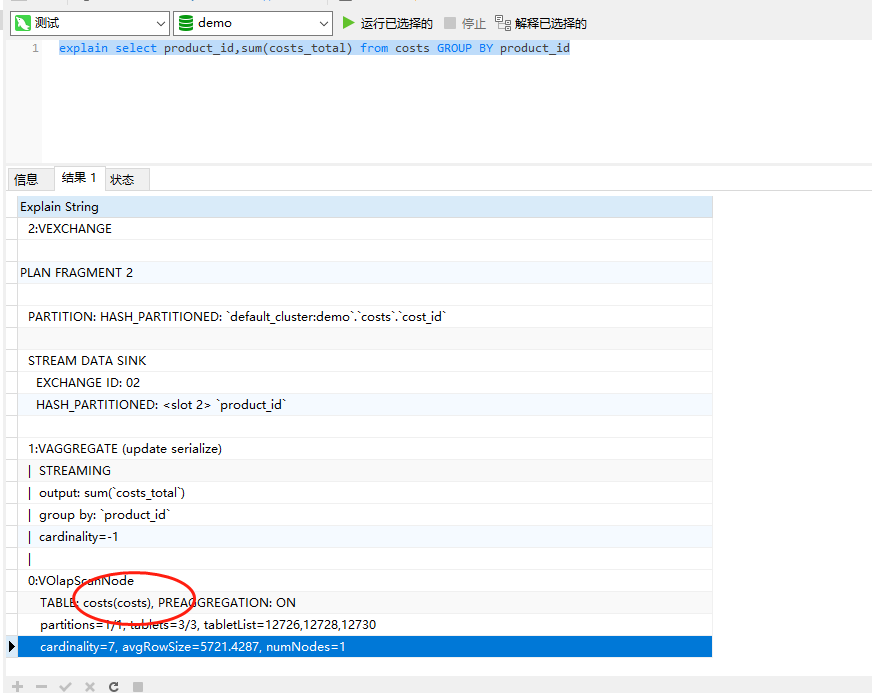
可以看到括号里面的就是读取的原始表。
根据上面的示例,我们可以完整的使用物化视图了,下面介绍下物化视图支持的聚合函数有哪些?
SUM, MIN, MAX (Version 0.12) COUNT, BITMAP_UNION, HLL_UNION (Version 0.13) BITMAP_UNION 的形式必须为:BITMAP_UNION(TO_BITMAP(COLUMN)) column 列的类型只能是整数(largeint也不支持), 或者 BITMAP_UNION(COLUMN) 且 base 表为 AGG 模型。 HLL_UNION 的形式必须为:HLL_UNION(HLL_HASH(COLUMN)) column 列的类型不能是 DECIMAL , 或者 HLL_UNION(COLUMN) 且 base 表为 AGG 模型。








还没有评论,来说两句吧...