
上一篇文章《Dinky 实时计算平台系列(十)Dinky使用指南之注册中心-Flink实例管理》我们介绍了Dinky添加单独的Flink集群,但是在实际工作中,很多公司会把flink的任务运行在Flink on yarn或者Flink kubernets native里面。此时其实从表象上来看就没有单独的flink集群了,只是作业上有flink的依赖环境而已。所以这种的话我们就没法使用Flink实际管理来添加集群了,只能使用集群配置管理来添加实例了。下面我们演示下Flink On Yarn的集群添加案例。
1)首先需要搭建一个hadoop环境
这里的话我们使用hadoop3来搭建一个hadoop环境,具体的搭建方案可参考:《Hadoop安装配置篇(一)Hadoop3.3.5单机版安装教程》。这里我们已经搭建好了,如下图:

然后我们把hadoop给启动起来

2)把flink相关的依赖包上传到hdfs上
如果需要在yarn上执行flink任务,那么我们需要执行的环境里面有flink相关的依赖包,这里我们统一把flink的依赖包上传到hdfs上,这里的依赖包可以直接在${Flink_home}/lib目录下取,也可以在我们前面配置的${Dinky_home}/plugins/flink1.17/dinky目录下取,这里我们从${Dinky_home}/plugins/flink1.17/dinky目录下取,所以执行如下的命令
#在hdfs上创建一个/flink目录 ./hadoop fs -mkdir /flink #在hdfs上创建一个/flink/lib目录 ./hadoop fs -mkdir /flink/lib #把依赖包上传到hdfs上的/flink/lib目录 ./hadoop fs -put /home/pubserver/dlink-release-0.7.3/plugins/flink1.17/dinky/*.jar /flink/lib/ #查看上传包的情况 ./hadoop fs -ls /flink/lib
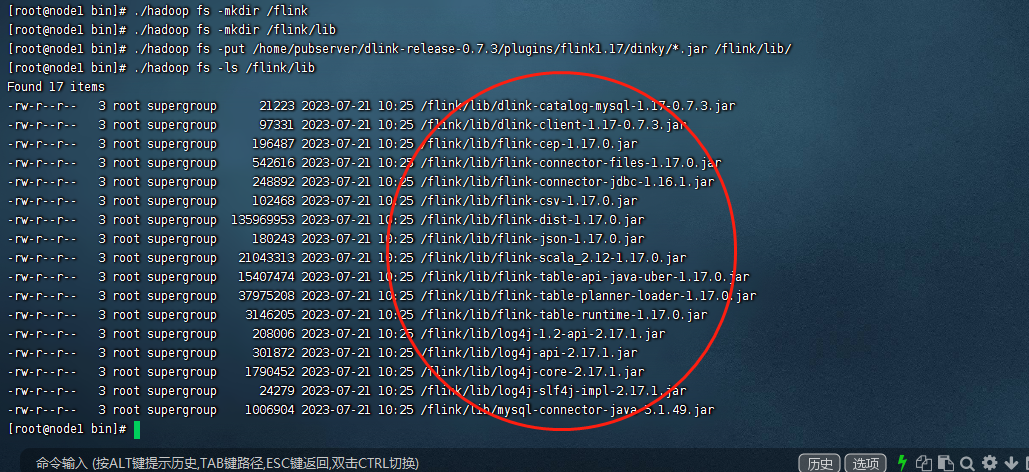
3)准备一份Flink的配置文件
这里主要是准备${Flink_home}/conf/flink-conf.yaml这个文件,我们可以直接去官网下载一个这个文件,同时也可以使用目前现成的,这里我们使用现成的即可,路径是:
/home/pubserver/flink-1.17.0/conf/flink-conf.yaml

4)添加dinky依赖
这里的集群配置主要是需要使用到hadoop,因此这里的话,我们需要在dinky的plugins里面添加hadoop的依赖,这里我们使用的是hadoop3,因此现成的依赖下载地址:dink-hadoop依赖下载。进入这个地址之后,我们直接下载这里的jar包:
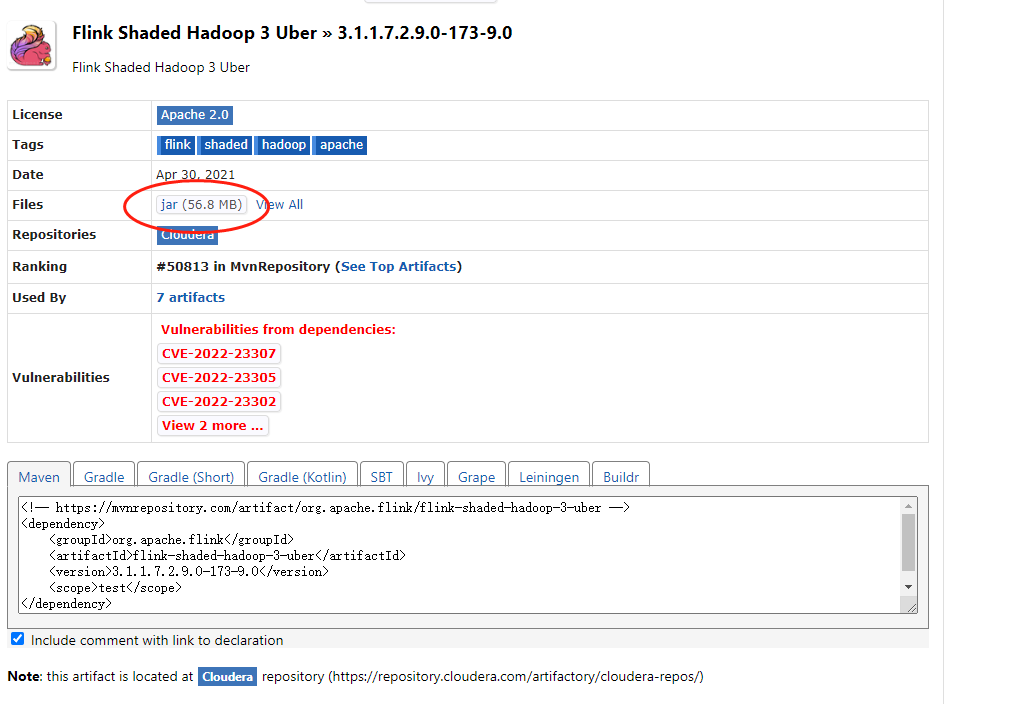
然后把这个jar包上传到dinky的如下目录:
${DINKY_HOME}/plugins/flink1.17/dinky上传完毕之后,可以在这个目录下看到具体的flink-shaded-hadoop-3-uber的包,如下图:
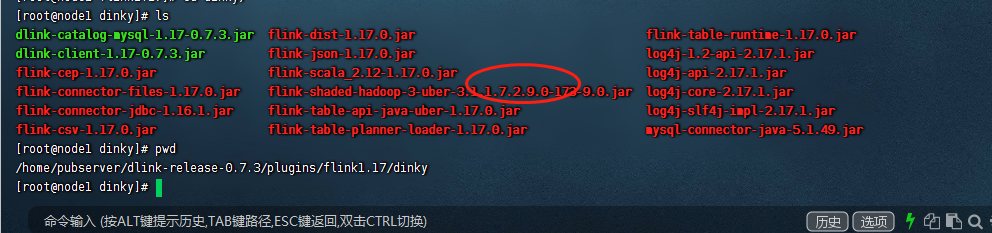
然后我们在这里重启下dinky。
5)配置dinky
登录到dinky平台,一次点击注册中心->集群管理->集群配置管理,然后点击新建按钮,会弹出如下的信息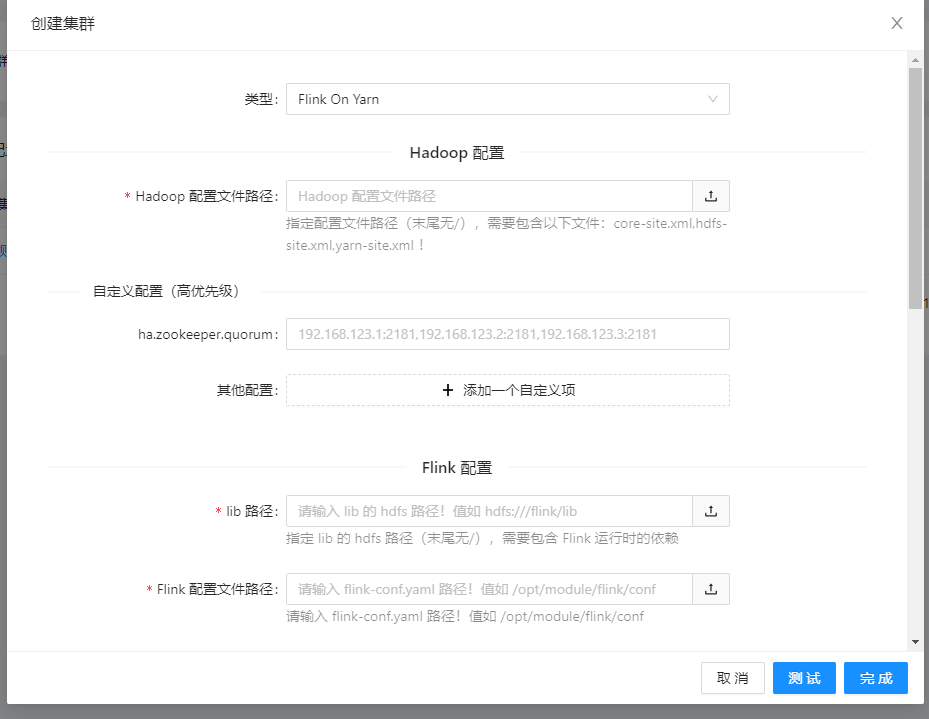
这里每一项的提示都比较全,按照这里的信息填写就可以了,我们这边部署的是hadoop单机,因此这里我们填写如下几项即可:
类型:Flink On Yarn Hadoop配置文件路径:/home/pubserver/hadoop-3.3.5/etc/hadoop lib路径:hdfs:///flink/lib Flink配置文件路径:/home/pubserver/flink-1.17.0/conf 集群配置名称:测试集群1
具体配置如下图:
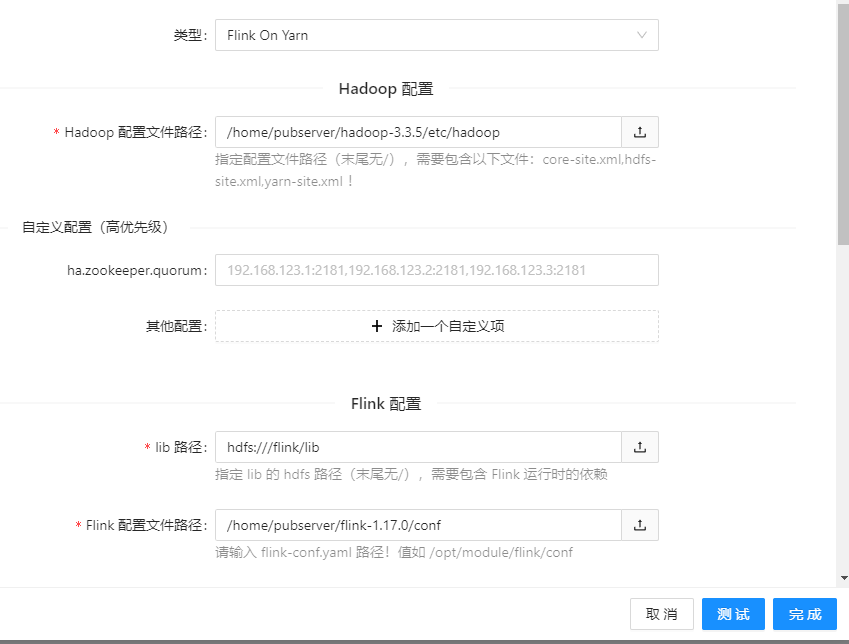

填写完毕之后,一定要测试一下,当页面显示测试成功的时候:
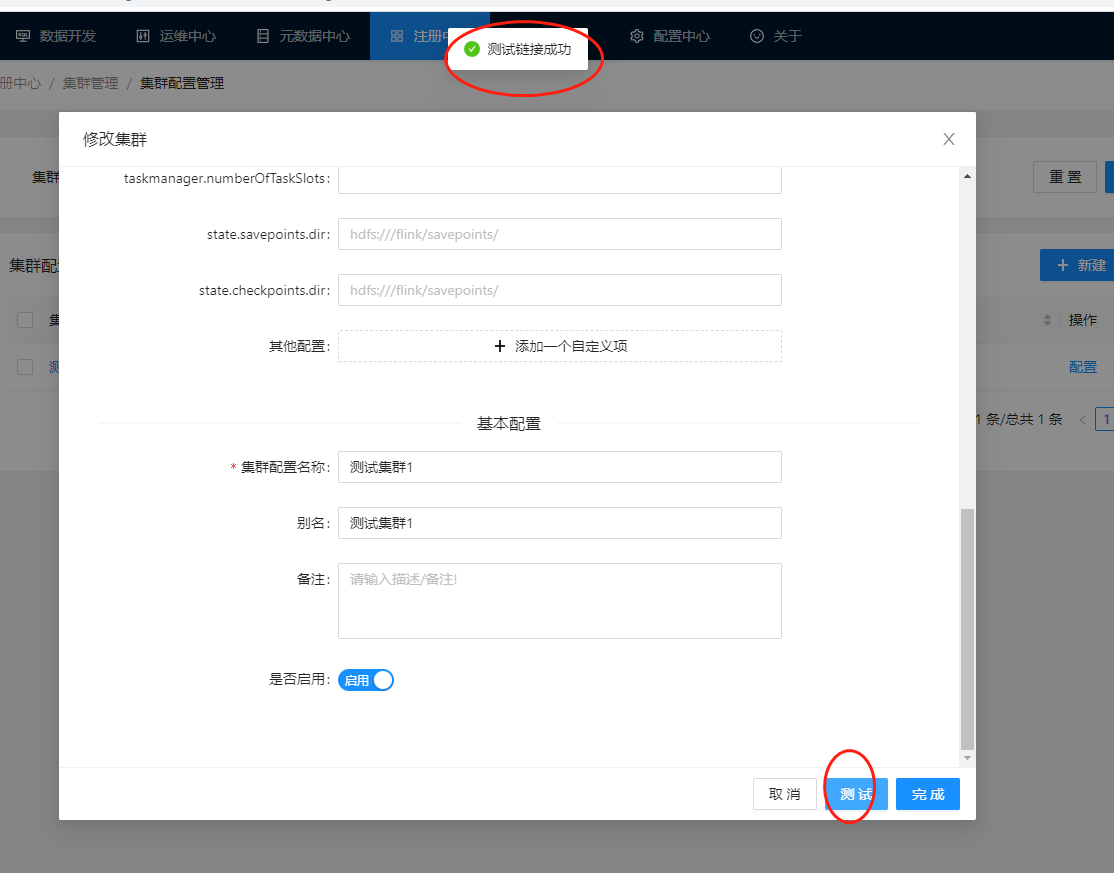
就代表配置完成了,然后点击完成进行保存。然后我们在页面上就可以看到刚才创建的测试集群1了,如下图:

可以看到创建的集群状态都是正常的。
备注:
1、创建这个集群的话,需要启动的组件有hadoop和dinky,不需要启动flink








还没有评论,来说两句吧...