
最近处于学习复盘的阶段,因此准备写一系列关于flink的实战相关的文章。今天介绍下第二篇,在flink中使用DataSTream API处理无界数据流。
学习下基础知识
1、DataStream API是flink里面做流计算的一种api。
2、无界数据流就是指数据像流水一样源源不断的涌入进来,没有停止的边界。
3、DataStream API的任务在flink集群里面执行的时候,是一个常驻性的任务进程,当程序启动之后源源不断的从数据源获取数据回来,然后结合具体的业务逻辑进行处理。
实战化
这里我们主要演示下使用DataStream API处理一批英文语句,然后进行下wordcount操作。
一、首先创建一个StreamWordCount的类
package com.flink.demo;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.flink.demo.function.Splitter;
import com.flink.demo.sources.MySources;
/**
* 这里主要演示下flink的DataStream API对数据进行wordcount的操作
*
* @author Administrator
*
*/
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 获取flink的执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 添加自定义的数据源,然后group by计算wordcount
SingleOutputStreamOperator<Tuple2<String, Integer>> dataStream = environment.addSource(new MySources())
.flatMap(new Splitter()).keyBy(0).sum(1);
// 持续输出打印
dataStream.print();
// 给运行时任务起一个job名称
environment.execute("flink StreamWordCount");
}
}这里就是一个非常简单使用DataStream API进行流处理的简单样例,里面主要做几件事情
1、定义一个数据源,这里我们是自己定义的一个类,Mysources类,在实际的工作中,这里的数据源名称叫做connector,常用的数据源有:消息队列(例如:kafka,metaq,rocketmq等),数据库(mysql,doris等),缓存(redis等)。
2、把接收的数据进行切割,然后进行group by和求和。
3、把结果打印出来。
4、让当前的任务成为常驻进程,所以这行代码:
environment.execute("flink StreamWordCount");一定要加上。如果没有这行代码,这就不是一个完整的流处理任务,也不会常驻在flink集群里面。
这里使用的其他类代码如下:
1)MySources类
package com.flink.demo.sources;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* 由于是demo,所以这里我们自定义一个source,然后自动向source发送数据
*
* @author Administrator
*
*/
public class MySources implements SourceFunction<String> {
private boolean running = Boolean.TRUE;
private static final String[] words = new String[] { "this", "is", "flink", "DataStream", "API", "test" };
private static final Random RANDOM = new Random();
private static final long serialVersionUID = -5258863350761775561L;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (running) {
this.sendDatas(ctx);
TimeUnit.SECONDS.sleep(1);
}
}
/**
* 随机发送数据
* @param ctx
*/
private void sendDatas(SourceContext<String> ctx) {
ctx.collect(words[RANDOM.nextInt(words.length)]);
}
@Override
public void cancel() {
running = Boolean.FALSE;
}
}2)Splitter类
package com.flink.demo.function;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
*
* @author Administrator
*
*/
public class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>>{
private static final long serialVersionUID = -5874538656857236727L;
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
out.collect(new Tuple2<String, Integer>(value, 1));
}
}二、测试验证
运行StreamWordCount类的main方法即可。然后看效果
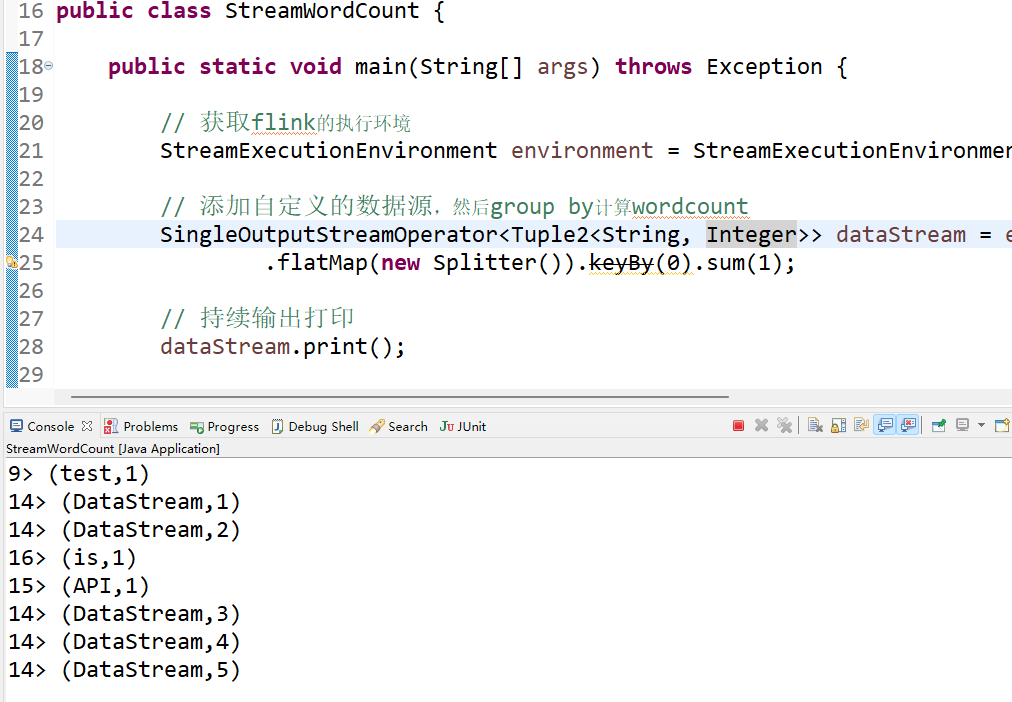
在这里我们可以看到控制台有源源不断的打印输出出来。
以上我们使用Data Stream API处理无界数据流的实战就完成了,最后附上源码下载:点击下载。








还没有评论,来说两句吧...