
本文我们介绍下使用mapreduce进行排序的实战案例。在实际的场景中,排序是一个硬性的需求,所以我们在mapreduce中需要来实现这个排序功能。
在mapreduce中,排序会发生在map阶段,因此这里的话,我们需要在map阶段进行排序,同时mapreduce是根据输出的key进行排序的,如果输出的key是intwritable的话,则会按照数字进行排序,如果输出的key是其他类型,则会按照ascii码进行排序。下面我们来演示下,这里还是使用之前的wordcount进行排序。下面直接开始
1)编写map进行words的切分
这里我们首先肯定是需要对单词进行切分,切分后的结果是:
this 1 is 1 a 1 test 1
类似上面的示例数据,详细的代码如下:
package com.mr.demo.map;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
*
* 从hdfs上读取文本内容的时候,这里使用mapper需要如下的几个输入值:
*<输入键类型,输入值类型,输出键类型,输出值类型> 这种进行类型的对标,对于<输入键类型,输入值类型>我们可以统一使用<Object, Text>即可
*
* 备注:对于上诉的<Object, Text>,仅限于text文本类型,不适合其他类型
*
*
* @author Administrator
*
*/
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable>{
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountMapper.class);
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void cleanup(Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
LOGGER.info("当前解析到的行内容是:{}",value.toString());
//这里的value就是我们接受到的每一行的内容,我们主要针对于每一行的内容进行解析
StringTokenizer words = new StringTokenizer(value.toString());
while(words.hasMoreTokens()) {
word.set(words.nextToken());
context.write(word, one);
}
//上诉我们的输出内容是: this 1,is 1,a 1,word 1 这种一个单词,数量为1
}
@Override
public void run(Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
super.run(context);
}
@Override
protected void setup(Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.setup(context);
}
}2)准备reduce进行统计
在前面我们通过map把单词切分了,接下来我们就来统计下这里的单词,最后形成的数据样例如下:
this 5 is 2 a 1 test 10
这种,前面是单词,后面是单词的数量,详细的示例代码如下:
package com.mr.demo.reduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountReduce.class);
private IntWritable _sum = new IntWritable();
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void reduce(Text key, Iterable<IntWritable> value,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 到这里经过之前的map解析之后,然后经过shuffle传递过来的值样例是:this:[1,2,3,4,1],is:[1,2,2,1,2]
// 所以我们只需要把后面数组里面的值相加即可。
int sum = 0;
for (IntWritable val : value) {
sum += val.get();
}
_sum.set(sum);
LOGGER.info("对应的key:{} 总数量是:{}",key,sum);
context.write(key, _sum);
}
@Override
public void run(Reducer<Text, IntWritable, Text, IntWritable>.Context arg0)
throws IOException, InterruptedException {
super.run(arg0);
}
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.setup(context);
}
}3)转换下单词与总数的个数
这里我们再使用一个map,转换下这个单词和数量的个数,原来的示例如下:
this 5
转换后的结果是:
5 this
这样子我们后续就可以根据key进行排序了,示例代码的map如下:
package com.mr.demo.map;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SortMap extends Mapper<Object, Text, IntWritable, Text> {
private IntWritable _key = new IntWritable();
private Text _value = new Text();
@Override
protected void cleanup(Mapper<Object, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void map(Object key, Text value, Mapper<Object, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException {
String line = value.toString().trim();
String[] tokens = line.split("\t");
_key.set(Integer.valueOf(tokens[1]));
_value.set(tokens[0]);
context.write(_key, _value);
}
@Override
public void run(Mapper<Object, Text, IntWritable, Text>.Context context) throws IOException, InterruptedException {
super.run(context);
}
@Override
protected void setup(Mapper<Object, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException {
super.setup(context);
}
}4)定义排序类型
这里的话我们可以根据key进行升序排序,也可以根据key进行倒序排序,因此这里我们需要定义一个排序类,示例代码如下:
package com.mr.demo.sort;
import org.apache.hadoop.io.IntWritable;
public class WordCountSort extends IntWritable.Comparator{
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
//这里直接使用默认方法即可,如果是正数,代表升序,如果是负数,代表降序
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}5)编排job
这里比较特殊,我们可以看到有2个map,1个reduce,然后整个是需要流程进行的,因此这里主类的话我们需要创建两个job,然后挨个执行,示例代码如下:
package com.mr.demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import com.mr.demo.map.SortMap;
import com.mr.demo.map.WordCountMapper;
import com.mr.demo.reduce.WordCountReduce;
import com.mr.demo.sort.WordCountSort;
/**
* 这里我们首先编写一个计数的job
*
* @author Administrator
*
*/
public class WordCountJobs {
public static void main(String[] args) throws Exception {
// 在运行mapreduce的时候,我们一般都是直接执行hadoop
// -jar的时候会把这个动态的参数传递进来,因此我们还是尽量保持一致,但是这里的话,我们主要是在本地运行测试,因此这里做下判断,在本地运行的时候稍微简化一点。
if (null == args || args.length == 0) {
args = new String[] {
// 这里的输入文件可以是一个文件夹,也可以是一个具体的文件路径
"/wordcount",
//临时文件夹
"/wordcounttmp",
// 这里的输出需要指定一个文件夹
"/wordcounttarget" };
}
// 首先都要创建下这里的configuration,这里我们由于是演示的项目,因此没有特别需要配置configuration的地方,如果没有单独配置,那么所有的配置就直接拿取整个hadoop集群的配置。
Configuration configuration = new Configuration();
// 首先我们看看target目录是否存在,存在的话把他给手动删除一下
deleteOutPut(args[1], configuration);
deleteOutPut(args[2], configuration);
// 然后我们在这里编写mapreduce,来计数
Job job = Job.getInstance(configuration, "word count");
//设置运行的类,一般都是本类
job.setJarByClass(WordCountJobs.class);
//设置mapper类
job.setMapperClass(WordCountMapper.class);
//设置reduce类
job.setReducerClass(WordCountReduce.class);
//指定输出的内容key
job.setOutputKeyClass(Text.class);
//指定输出的内容value
job.setOutputValueClass(IntWritable.class);
//添加需要读取的数据源目录
FileInputFormat.addInputPath(job, new Path(args[0]));
//添加需要输出的数据目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
int code = job.waitForCompletion(true) ? 0 : 1;
if (code == 0) {
Job jobs = Job.getInstance(configuration, "word count sort");
jobs.setJarByClass(WordCountSort.class);
jobs.setMapperClass(SortMap.class);
jobs.setOutputFormatClass(TextOutputFormat.class);
jobs.setOutputKeyClass(IntWritable.class);
jobs.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(jobs, new Path(args[1]));
FileOutputFormat.setOutputPath(jobs, new Path(args[2]));
jobs.setSortComparatorClass(WordCountSort.class);
code = jobs.waitForCompletion(true) ? 0 : 1;
}
System.exit(code);
}
/**
* 去服务器上删除掉输出目录,避免输出目录已经存在而报错
*
* @param args
* @throws IOException
*/
private static void deleteOutPut(String path, Configuration configuration) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(new Path(path))) {
fileSystem.delete(new Path(path), true);
}
}
}可以看到这里由2个job,每个job都有自己的输出和输出,然后第一个job执行完毕之后再会执行第二个job。
6)把项目打包上传服务器运行下:
hadoop jar MRDemo-1.0-jar-with-dependencies.jar com.mr.demo.WordCountJobs
我们可以看到在yarn上执行了两个任务:
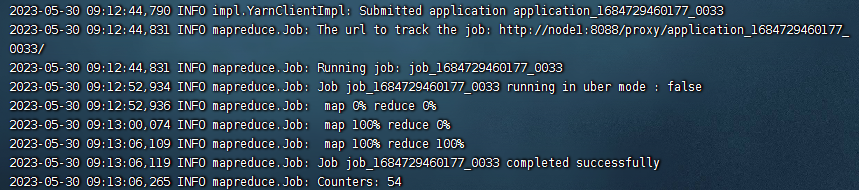
和
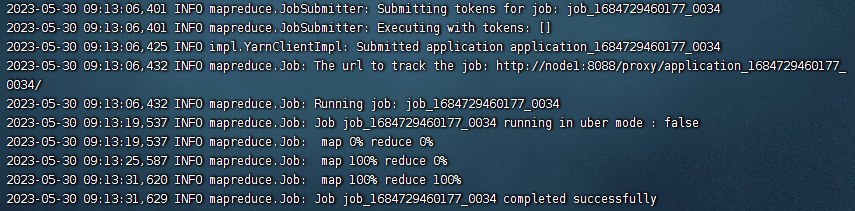
最后我们看下结果输出:
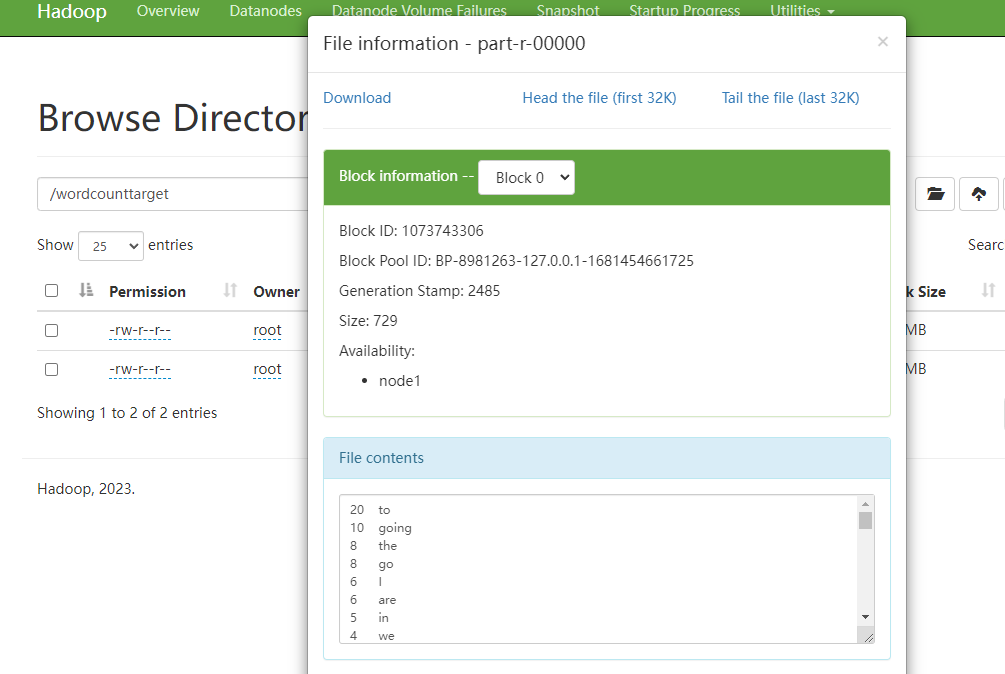
可以看到实现了倒序的排序。最后按照惯例,附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...