
在上一篇文章《Mapreduce实战案例(三)实现reduce端join》中,map里面我们是先把数据转化成了json,然后再转换成string,然后再把string放入到text类型里面进行向reduce传递的,如下图:
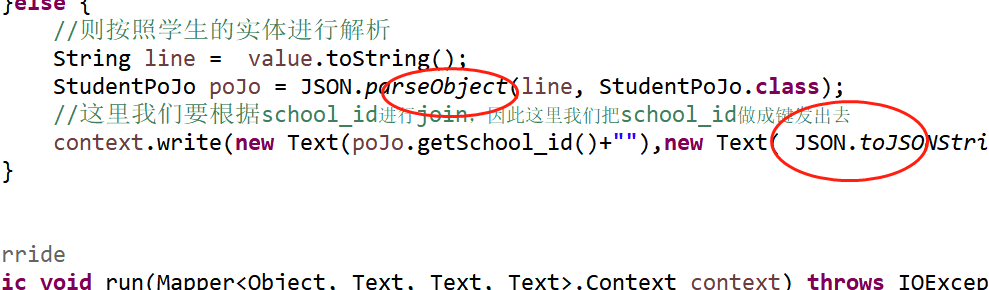
在reduce中,我们直接获取到string,再转换成json,如下图:
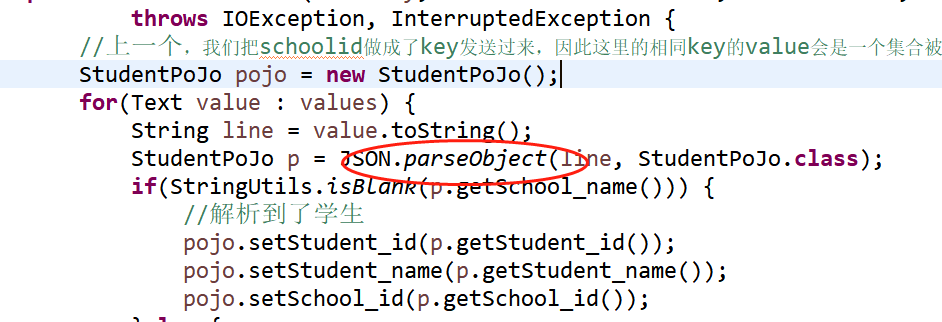
这样子我们不管在map还是reduce中使用的都是student对象,那么有没有可能我们map直接向reduce传递这个student对象就好,不用转来转去的。答案是有可能,就是需要自己实现这里的writable。下面我们直接来实操下:
1)我们把studentpojo改造下,之前实现的是Serializable序列化,这里的话我们修改成Writable实例化即可,如下图:

既然实现了这个序列化的话,我们就要实现这里的序列化和反序列化的方法:
public void write(DataOutput out) throws IOException {
LOGGER.info("准备写入的数据是:{}", this.toString());
// int类型使用writeInt
if (null != student_id) {
out.writeInt(student_id);
} else {
out.writeInt(-1);
}
if (null != school_id) {
out.writeInt(school_id);
} else {
out.writeInt(-1);
}
// string类型使用writeUTF
if (StringUtils.isNotBlank(student_name)) {
out.writeUTF(student_name);
} else {
out.writeUTF("");
}
if (StringUtils.isNotBlank(school_name)) {
out.writeUTF(school_name);
} else {
out.writeUTF("");
}
if (StringUtils.isNotBlank(school_address)) {
out.writeUTF(school_address);
} else {
out.writeUTF("");
}
}
public void readFields(DataInput in) throws IOException {
// int类型使用readInt
student_id = in.readInt();
school_id = in.readInt();
// string类型使用writeUTF
student_name = in.readUTF();
school_name = in.readUTF();
school_address = in.readUTF();
}备注:
1、这里的话我们的输入和输出数量要保持一致,即使某些字段为空也需要有一个占位符,不然在读取的时候读取不到。
2、这里我们使用了Writable序列化就不要再添加Serializable序列化了。
2)修改mapper,把出类型修改为这里的StudentPoJo2,示例图如下:
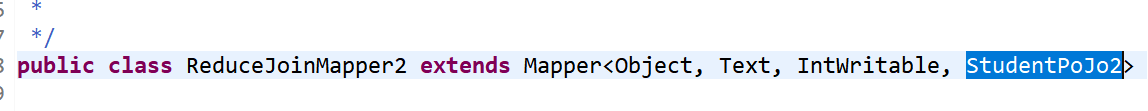
然后我们在map里面使用context直接写studentpojo对象即可,如下图:

3)修改reducer的读取,把输入类型修改为studentpojo,如下图:

然后在reduce里面我们直接获取这个studentpojo对象即可:

然后我们这里把job名称设置为2:

然后我们把项目打包上传到服务器上运行下看看:
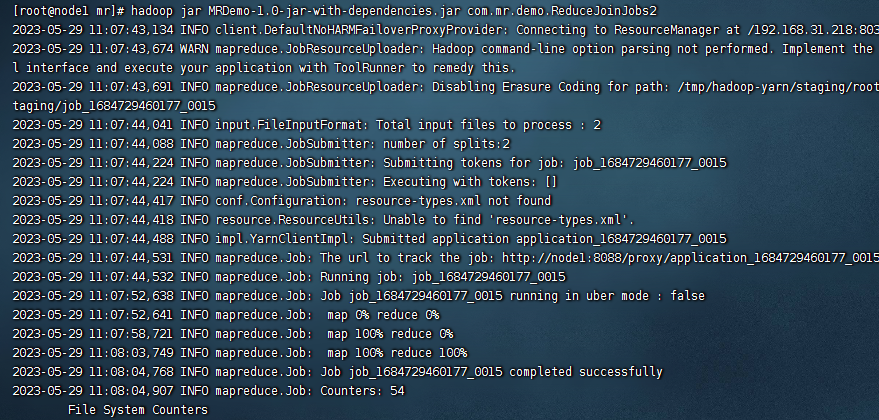
可以看到完全没问题。最后附上本案例的源码,登录后即可下载:








还没有评论,来说两句吧...