
上一篇文章《Mysql的分区表介绍》我们介绍了mysql的分区表,如果我们正在使用分区表的话,那么在后面进行查询、排查优化等会涉及到一些知识点,这里我们列举一下:
1)创建分区表:
这里创建分区表的话,我们在前一篇文章已经演示过了,下面再列举下:
CREATE TABLE `wallet_consumer_logs` (
`id` bigint(19) NOT NULL,
`order_no` varchar(21) DEFAULT NULL COMMENT '流水号',
`transaction_id` varchar(40) DEFAULT NULL COMMENT '第三方支付流水号',
`time_bucket_id` bigint(19) DEFAULT NULL COMMENT '时间段id',
`device_id` bigint(19) DEFAULT NULL COMMENT '设备id',
`costs_consume_log_id` bigint(19) DEFAULT NULL COMMENT '消费机消费记录id',
`wallet_user_id` bigint(19) DEFAULT NULL COMMENT '用户钱包id',
`wallet_type` int(11) DEFAULT NULL COMMENT '钱包类型,0:余额钱包,1、补贴钱包',
`wallet_user_balance` decimal(10,2) DEFAULT NULL COMMENT '扣款前的余额',
`op_type` tinyint(1) DEFAULT NULL COMMENT '1:充值;2:减款;3:消费;4:补贴;5:退款;6补扣;7余额清理',
`op_user` varchar(30) DEFAULT NULL COMMENT '操作用户',
`amount` decimal(10,2) DEFAULT NULL COMMENT '本次操作金额',
`user_relation_id` varchar(19) DEFAULT NULL COMMENT '消费者用户id 云校园 用户表字段',
`remark` varchar(255) DEFAULT NULL COMMENT '备注',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`school_id` bigint(19) DEFAULT NULL COMMENT '学校id',
`branch_id` bigint(19) unsigned DEFAULT NULL COMMENT '校区id',
`dept_id` bigint(19) DEFAULT NULL COMMENT '部门id',
PRIMARY KEY (`id`,`create_time`) USING BTREE,
KEY `idx_school_id` (`school_id`) USING BTREE,
KEY `idx_branch_id` (`branch_id`) USING BTREE,
KEY `idx_dept_id` (`dept_id`) USING BTREE,
KEY `idx_user_relation_id` (`user_relation_id`) USING BTREE,
KEY `idx_order_no` (`order_no`) USING BTREE,
KEY `idx_costs_consume_log_id` (`costs_consume_log_id`) USING BTREE,
KEY `idx_device_id` (`device_id`) USING BTREE,
KEY `idx_wallet_user_id` (`wallet_user_id`) USING BTREE,
KEY `idx_op_type` (`op_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='钱包的所有消费记录日志表'
PARTITION BY RANGE (to_days(create_time))
(
PARTITION p202306 VALUES LESS THAN (to_days('2023-07-01')),
PARTITION p202307 VALUES LESS THAN (to_days('2023-08-01')),
PARTITION p202308 VALUES LESS THAN (to_days('2023-09-01'))
);2)添加分区
在前面我们介绍过range分区的话一般都以时间为主体进行创建的,所以像上文我们创建了6、7、8分区,此时我们添加一个9的分区,示例sql如下:
alter table `wallet_consumer_logs` add partition(PARTITION p202309 VALUES LESS THAN (to_days('2023-10-01')));3)删除分区
有时候我们有一部分记录不想要了,也就是当前表的数据支持物理删除,此时我们可以做的就是直接删除分区即可,例如:
alter table `wallet_consumer_logs` drop partition p202309;
4)查看分区
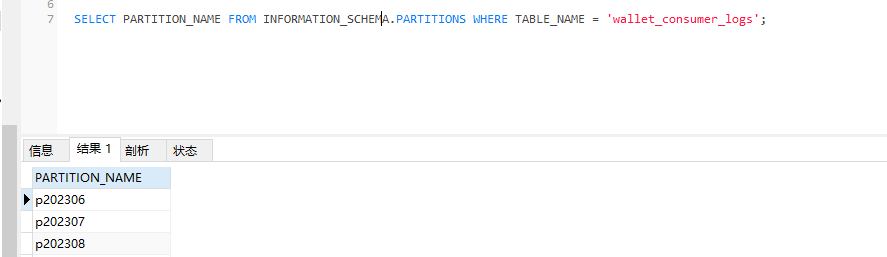
当然我们还可以查看当前表总共有哪些分区,示例sql如下:
SELECT PARTITION_NAME FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME = 'wallet_consumer_logs';
5)查询某个分区的数据
这里我们按照时间进行分区,传统的查询分区的数据方式是:
select * from wallet_consumer_logs where create_time > '2023-07-01' and create_time < '2023-08-01';
如果使用分区进行查询的话,直接使用:
select * from wallet_consumer_logs partition(p202307);
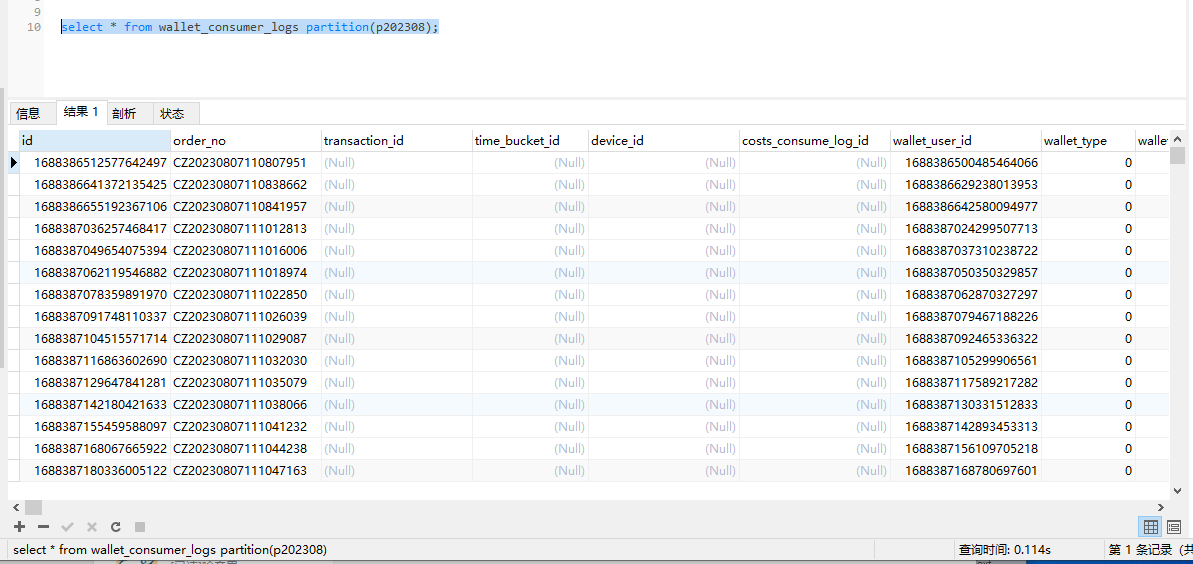
查询效率非常高。
6)清空某个分区的数据
有时候我们由于数据有误,需要重新把数据写入到某个分区里面去,我们可以使用如下的sql:
alter table `wallet_consumer_logs` truncate partition p202308;
这样子就可以把某个分区的数据给删除掉,而不删除这个分区,数据仍然可以写入到这个分区里面来。
以上就是对于分区的常用的操作sql。








还没有评论,来说两句吧...