
上文《人工智能AI本地大模型系列(三)使用ollama部署阿里开源大模型Qwen2》我们演示了在本地服务器上部署大模型Qwen2-7b。最后演示的时候我们是使用命令行来演示问答的,如下图:
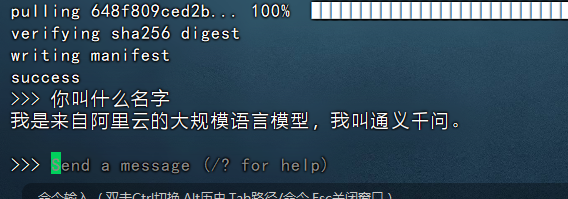
试想一下,百度文心一言都可以直接使用界面来进行交互了,那么有没有现成的可交互的UI框架呢?答案是有的,就是本文介绍的Dify。本文我们来演示一下Dify的部署安装及结合前面的Qwen2-7b模型进行交互。
一、安装docker环境
Dify只是一个dashboard,所以这里的话咱们一般不用使用物理部署了,直接使用docker启动一个即可,所以一定要先确保服务器上有docker环境和docker-compose环境。
docker的安装可参考:《docker安装》
docker-compose安装可参考:《docker-compose安装》
二、clone dify源码
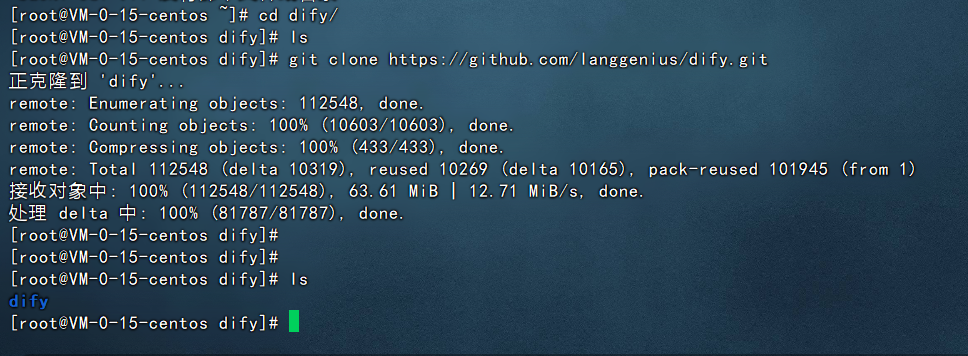
Dify是一套开源的代码,所以需要把它的代码从github上clone到本地:
git clone https://github.com/langgenius/dify.git
如下图:
三、启动Dify
接下来就是启动Dify了,进入到dify/docker目录下,可以看到有对应的docker-compose.yml文件

我们执行如下的命令来启动
#拷贝env文件 cp -r .env.example .env #执行环境 . .env #启动dify docker-compose up -d
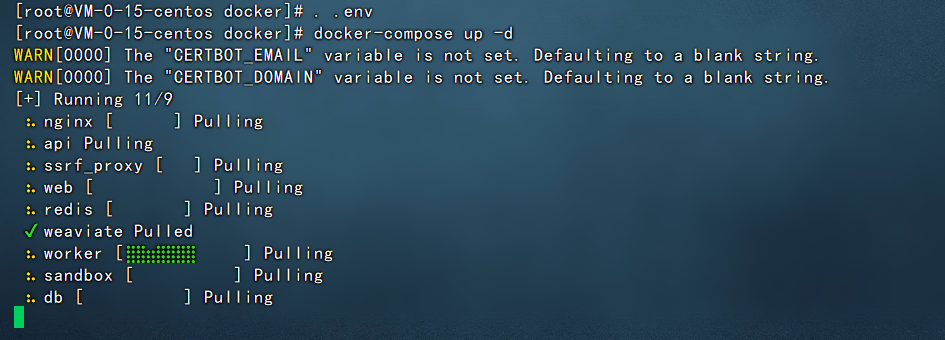
然后等待片刻,dify就能启动完成了。
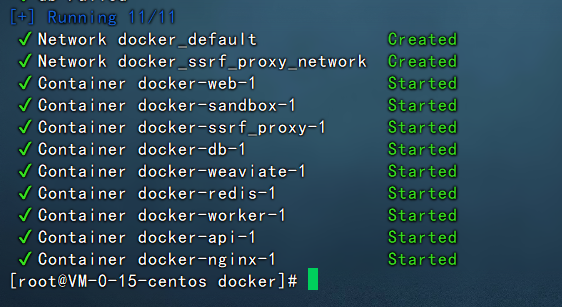
启动完成之后,使用docker ps可以看到有10个docker实例运行起来。
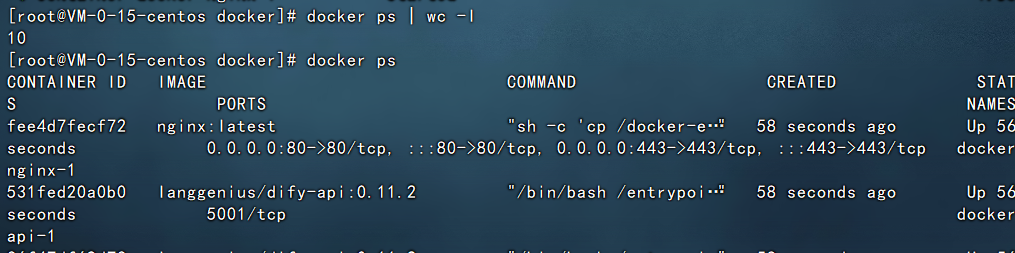
四、访问Dify
接下来就可以在浏览器中访问Dify了,输入服务器的ip即可:http://ip 端口是默认的80。第一次访问需要设置管理员账户:
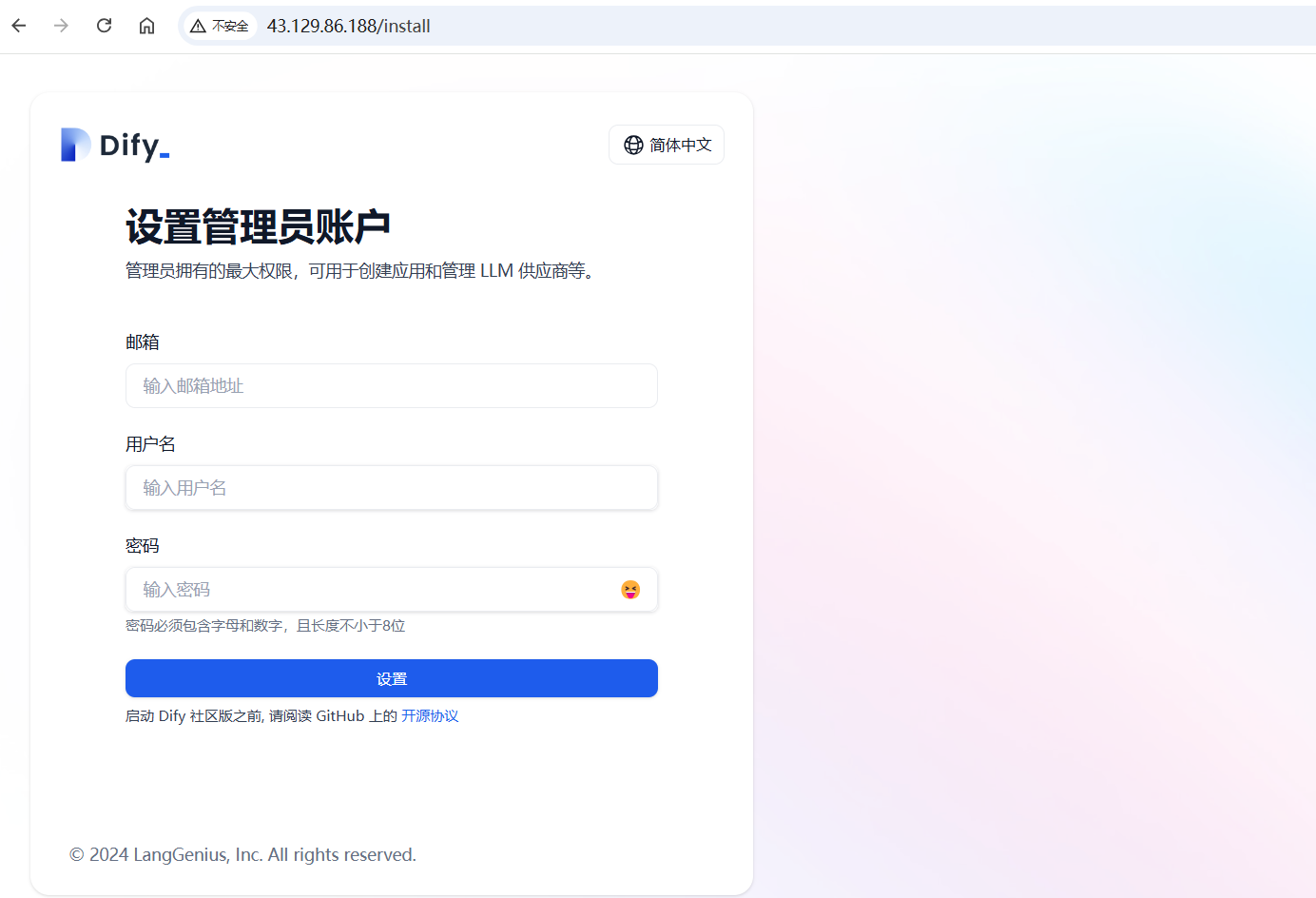
设置之后会跳转到登录页面,输入刚才的管理员信息就可以访问了:
五、集成Qwen2-7B
接下来我们需要继承qwen2-7b大模型了,首先进入到Dify的dashboard,点击右上角的头像,会看到有个设置的按钮:
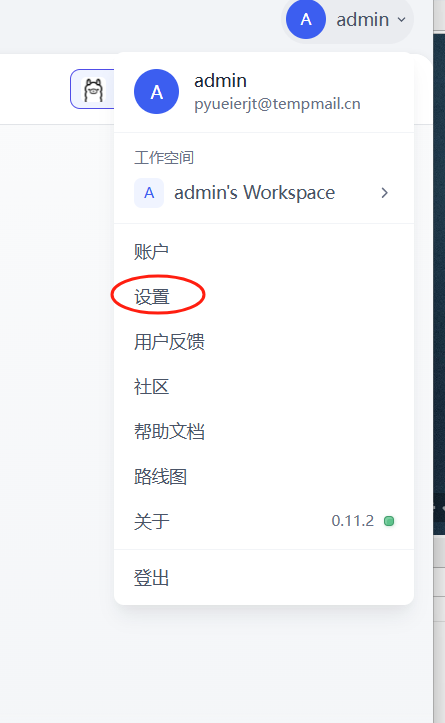
点击设置按钮,选择模型供应商,由于我们在这里添加前面在本地部署的ollama,所以这里选择ollama:
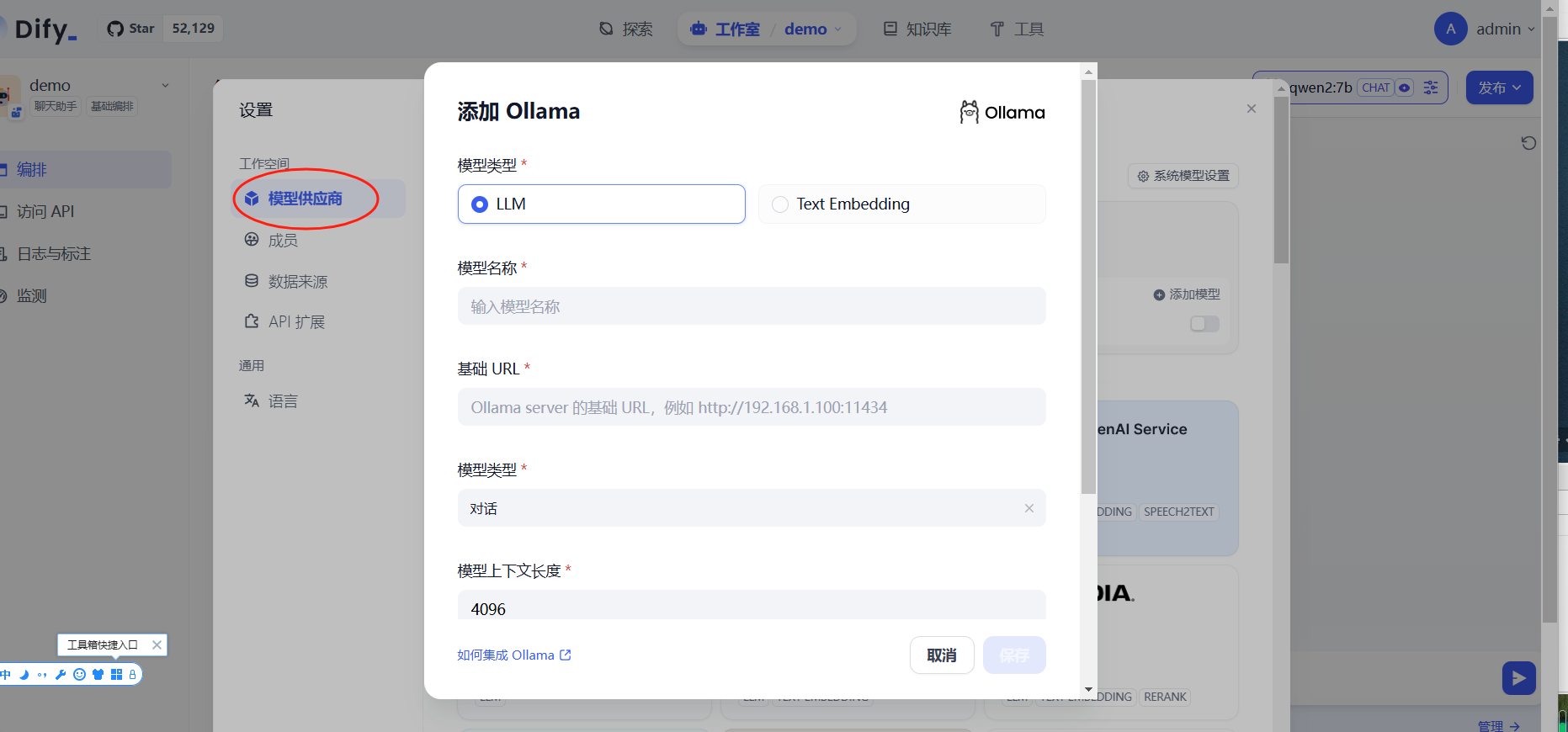
这里填入的信息如下:
模型名称:填写 qwen2:7b
这里的模型名称不能随便填写,需要填写在服务器上运行的名称,即下图:
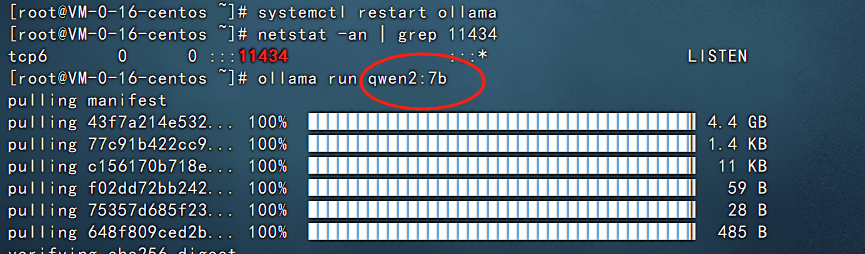
如果写其他的名称,那么配置ollama会提示404找不到,所以这里一定要注意,填写的名称就是运行的模型名称,字符串必须保持完全一致。
基础URL: 这里填写服务器的ip+11434端口即可,例如:http://192.168.1.129:11434
注意这里一定要添加前缀http://,同时端口是11434,我们在前面已经把11434端口修改为0.0.0.0/0访问了,如果配置不成功,可查看《人工智能AI本地大模型系列(二)ollama的部署》文末的具体解决方案。
剩下的信息全部都可以保持默认,我这里的填写的示例如下:
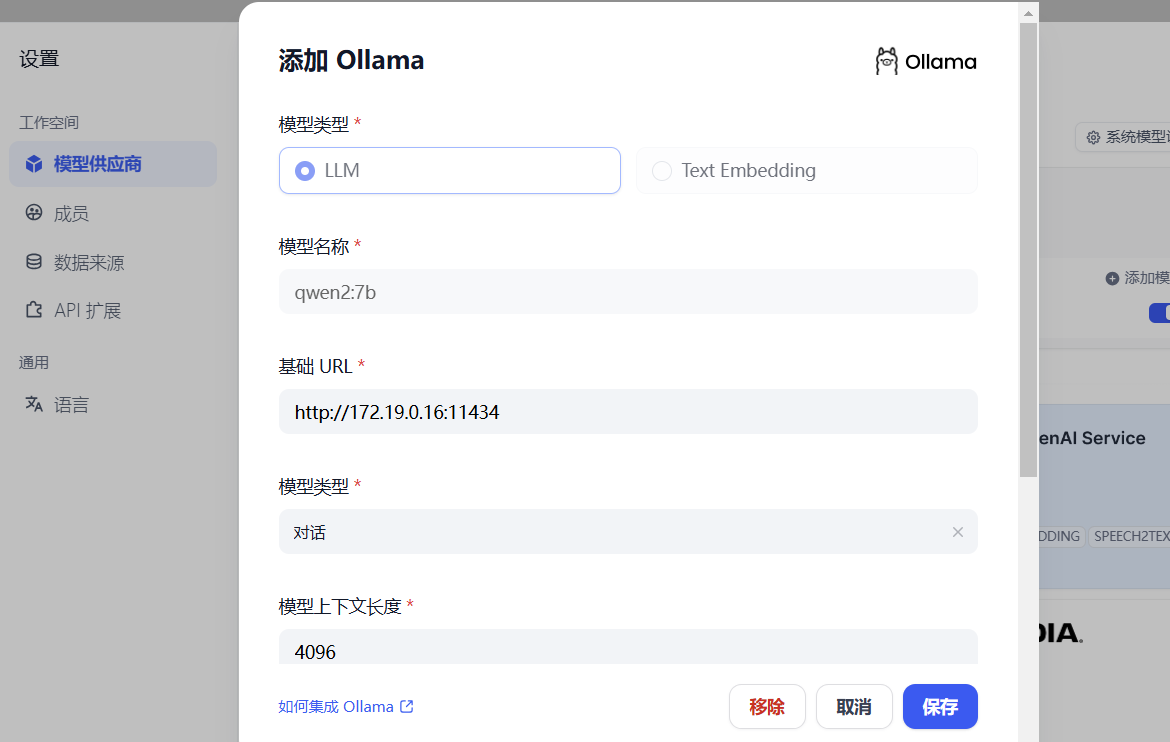
最后点击保存。
接下来就是创建应用的环节,选择聊天助手,创建一个空白应用
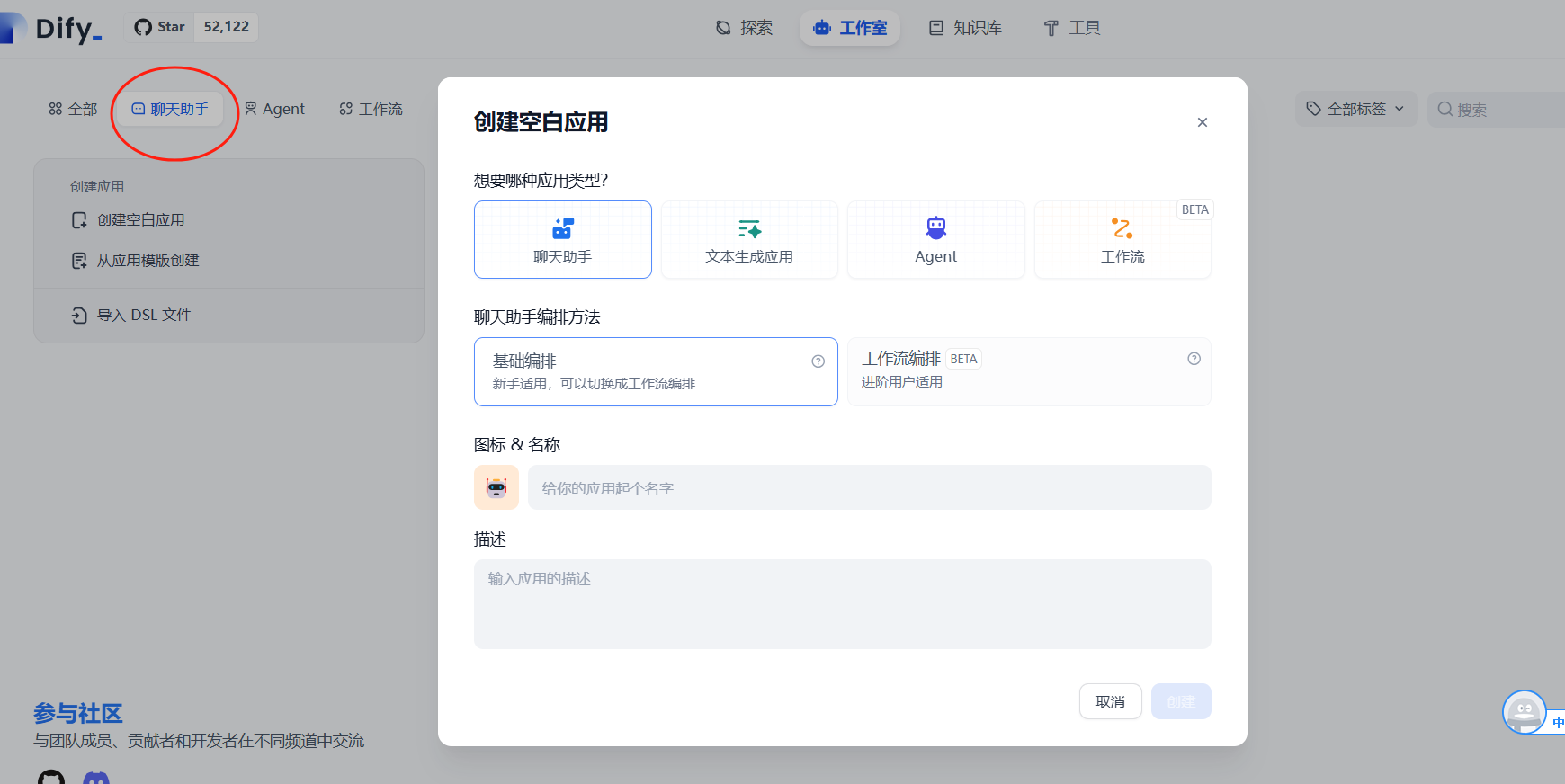
填写名称和描述,点击创建就会进入到聊天助手应用里面:
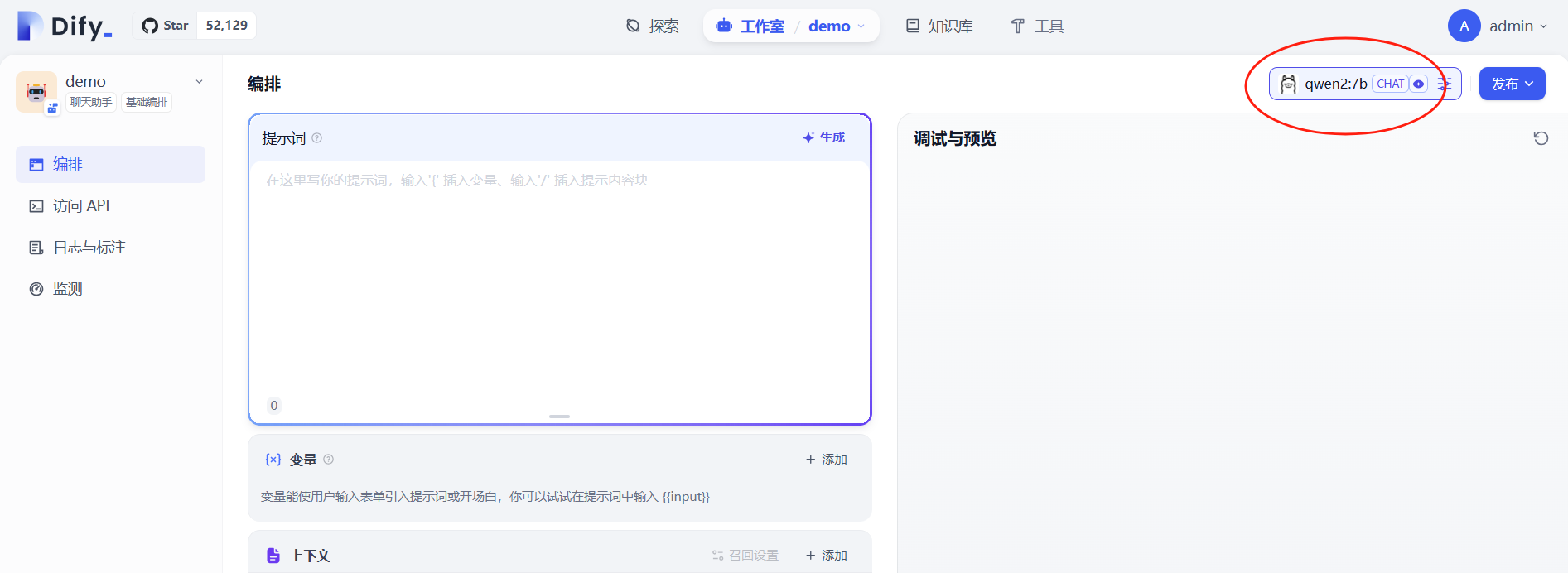
然后我们在右上角可以看到刚才添加的qwen:7b模型:
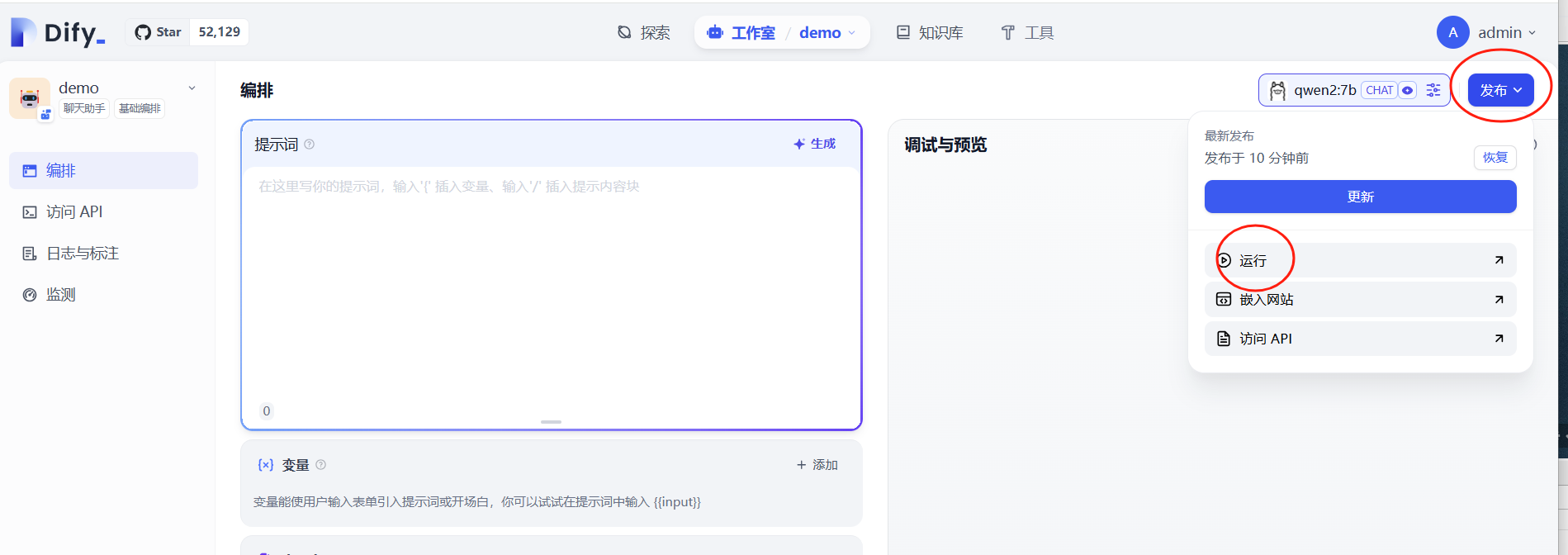
点击上面的发布
就可以进入到聊天界面聊天了,示例如下:
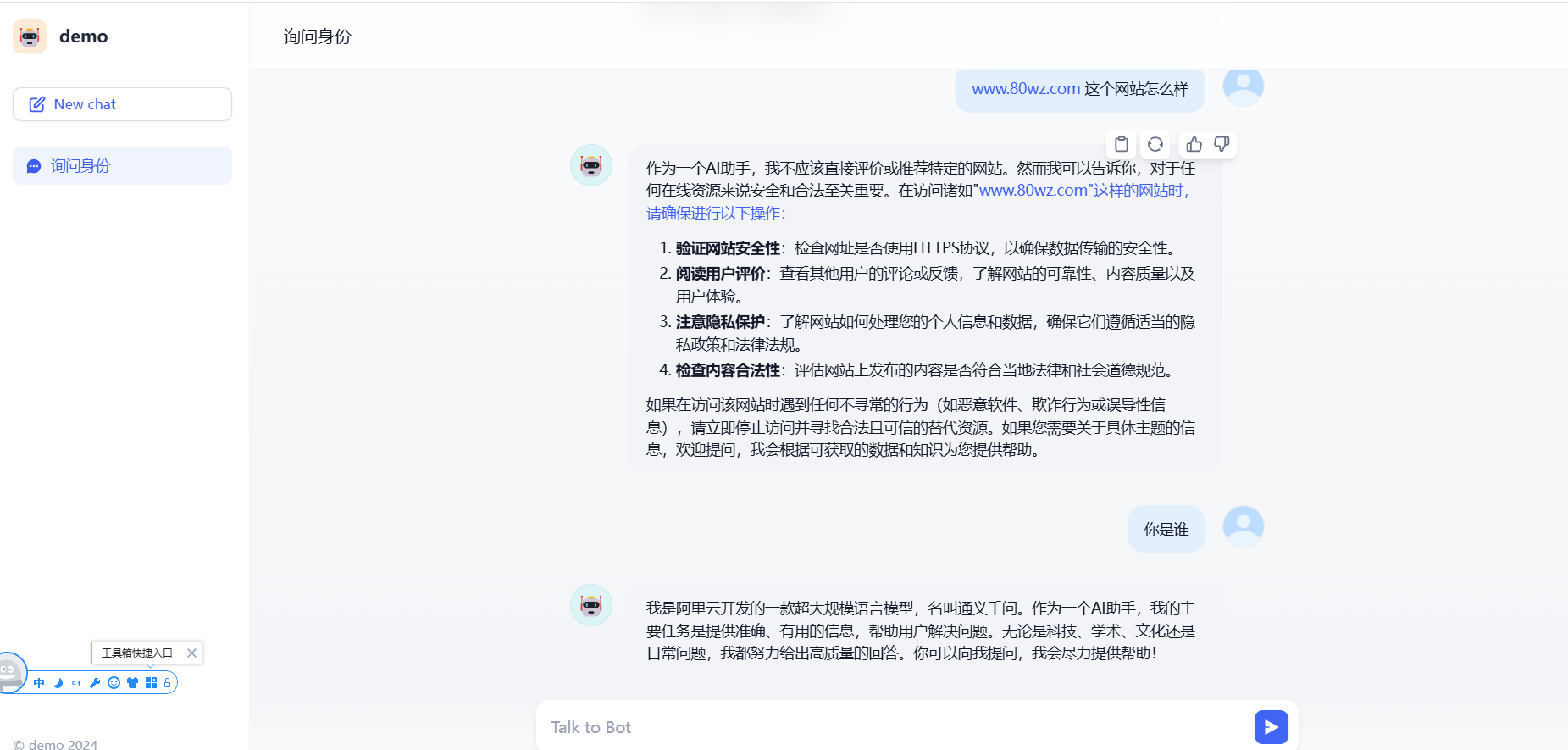
是不是很方便。
特别注意下,这里的响应速度是由服务器的配置决定的,比如我们这里是8C16G的配置,提问的时候CPU是完全跑满的,回答也是等待了好大一会。
以上就是我们使用dify集成本地部署的qwen:7b大模型的案例。后面我们会挨个介绍如何进行本地知识库集成等案例,让其更加贴合业务场景。








还没有评论,来说两句吧...