
上一篇文章《人工智能AI本地大模型系列(二)ollama的部署》我们介绍了ollama的安装。同时也在前面介绍了,ollama是用来安装部署本地大模型的管理环境。本文我们来演示一下使用ollama部署阿里开源的Qwen2模型。
Qwen2模型是阿里巴巴开源2024年6月发布的的大模型,官方的解释是:
Qwen2所有尺寸模型都使用了GQA(分组查询注意力)机制,以便让用户体验到GQA带来的推理加速和显存占用降低的优势
这里由于我们的服务器配置低,所以我们部署Qwen2-7B模型即可。下面演示下如何安装。
首先我们进入到刚才安装了ollama的服务器,执行如下的命令:
ollama run qwen2:7b
然后系统就会自动开始安装qwen2-7b模型了,如下图:

稍等片刻,看到如下的界面就代表qwen2-7b模型安装好了。
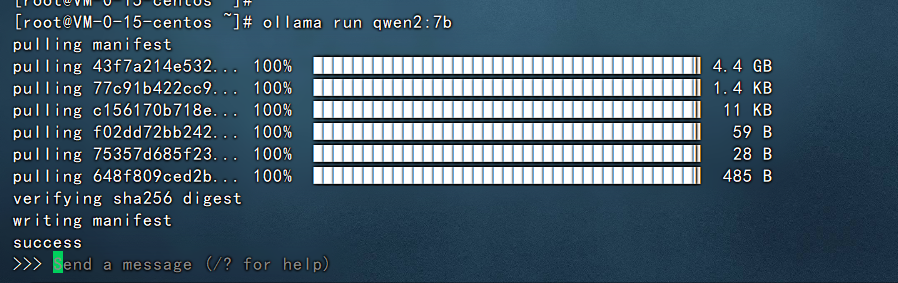
在最后可以看到让我们输入问题,他可以进行回答,比如我们输入:你叫什么名字,然后回车就可以看到他开始回答了。如下图:
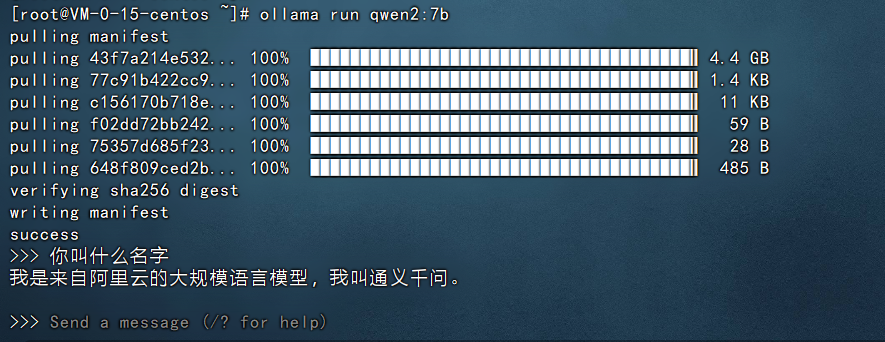
以上就是在本地部署qwen2-7b大模型的案例。
备注:qwen2-7b大模型非常吃内存,建议服务器的内存至少16G及以上。








还没有评论,来说两句吧...