
本文我们开始正式进入人工智能AI本地大模型的实施了。既然是本地部署大模型,那么我们就要开始各种安装部署了。本文我们主要介绍ollama的部署。
在本地部署人工智能大模型的时候,我们最常使用到的就是ollama这个开源框架。这个开源框架的官方解释是:
Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、Phi 3、Mistral、Gemma等开源的大型语言模型。
我们再打个比喻来解释下什么是ollama。
对于开发的同学来说,我们知道目前最常用的docker。docker是一个容器环境,我们所有的应用就是打包的docker镜像,然后运行在docker环境里面的。所以结合ollama的解释,就是ollama就相当于一个docker环境,也就是AI大模型的管理平台,大部分开源的大模型,我们可以直接在ollama上进行安装部署。这样子的理解是不是比较清楚了。

所以要在本地实现大模型的话,我们首先需要安装部署一套ollama环境,下面我们演示一下。
一、准备环境
这里我们在服务器上安装部署ollama,所以对应的环境主要是linux系统,大家要准备在本地部署大模型的话,建议统一使用服务器linux系统,同时cpu,内存这些尽量大一点,比如16C64G这样的配置。
二、下载ollama
想要安装ollama的话,他的安装包比较简单,我们可以去官网:https://ollama.com/ 下载即可(打开这个首页就会直接看到下载按钮)
点击Download即可下载,这里我们选择linux版本即可,他是一个脚本:
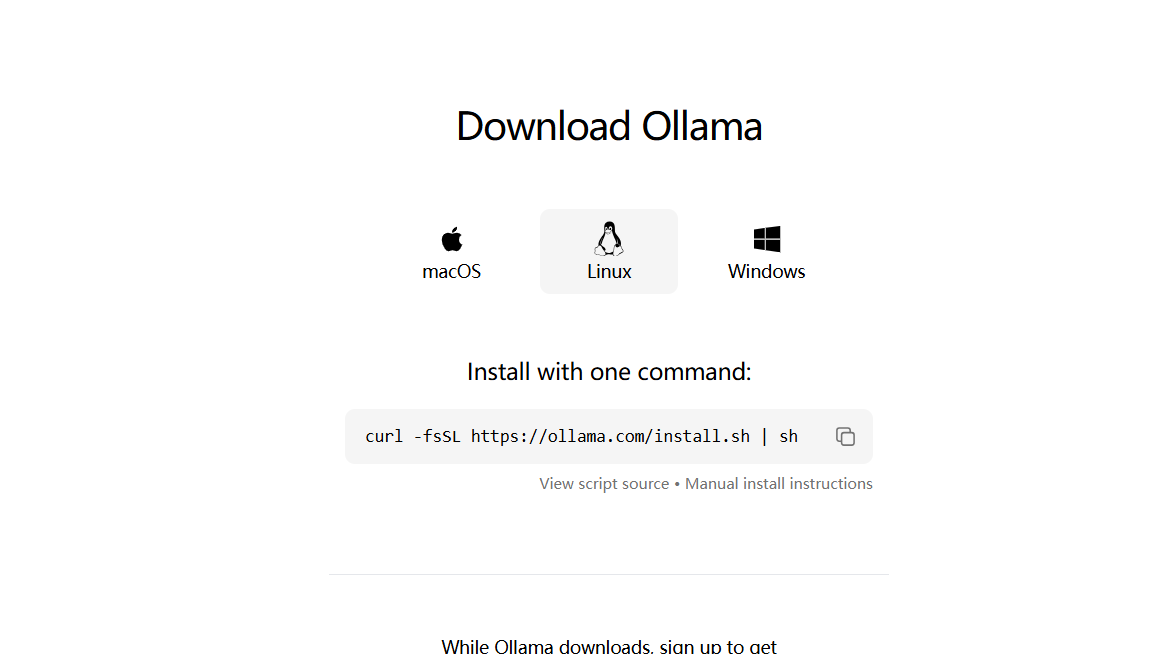
我们把它复制下来,完整的内容是:
curl -fsSL https://ollama.com/install.sh | sh
三、安装ollama
接下来我们就去服务器进行安装即可,执行上面的curl命令,示例图如下:

执行之后,服务器就会开始自动下载及安装。稍微等待片刻即可。出现如下界面就代表安装完成了。
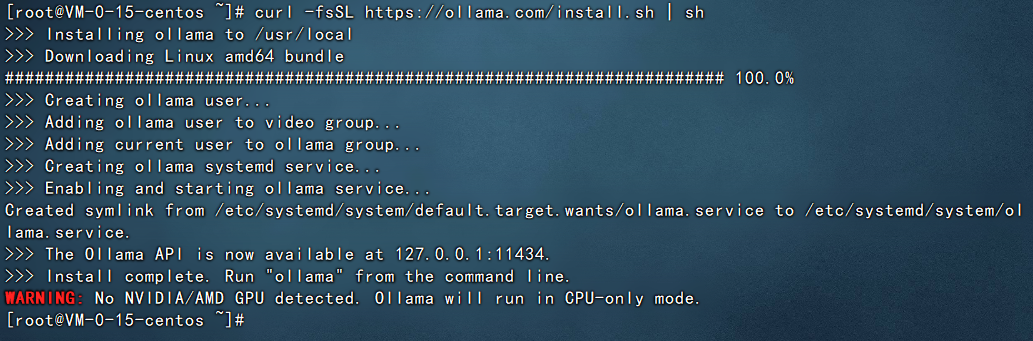
备注:
1、这里在安装的过程中国内网络问题可能会比较复杂,建议使用香港的服务器来实施。
至此,我们的ollama环境已经部署完成了,在控制台我们可以使用
ollama help
查看ollama如何使用。
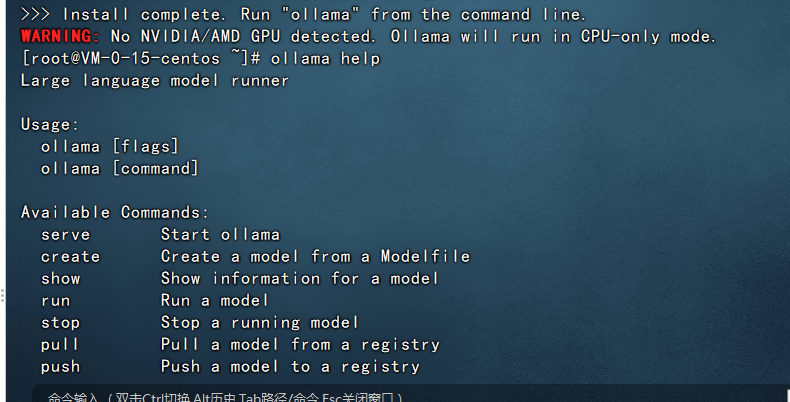
ollama启动完成之后会提供一个11434的端口供其他应用程序访问,示例如下:

从上图大家发现问题没?ollama提供的11434端口仅支持127.0.0.1访问或者localhost访问,不支持使用服务器的ip进行访问,所以这里我们需要调整一下,让11434端口供其他程序可以访问。
1、修改 /etc/systemd/system/ollama.service文件,添加上
Environment="OLLAMA_HOST=0.0.0.0" Environment="OLLAMA_ORIGINS=*"
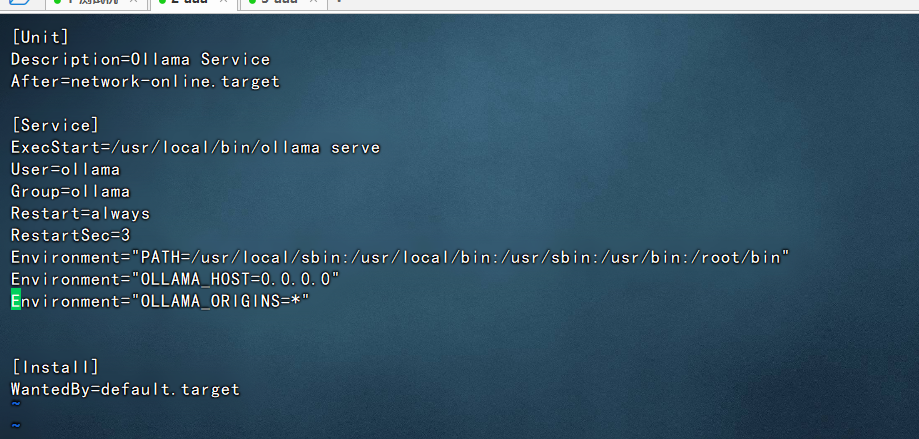
2、重启ollama
systemctl daemon-reload systemctl restart ollama
此时我们再查看11434端口就是可以直接使用ip进行访问了:
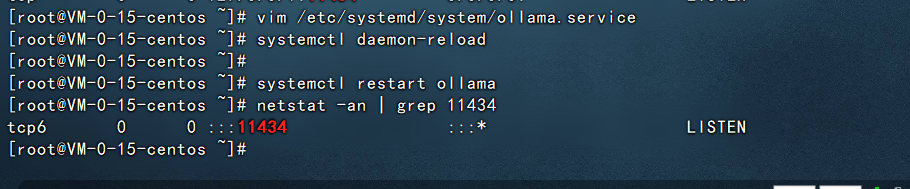
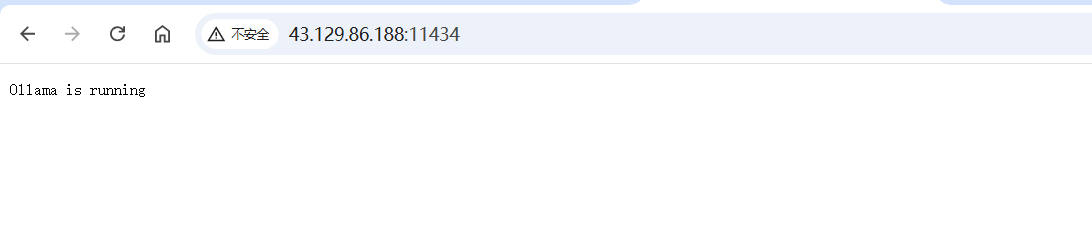
再使用浏览器访问看看








还没有评论,来说两句吧...