
在前面我们介绍了spark sql的构成等等,这篇文章我们来演示下spark sql的使用,并且编写一个demo给大家看看。
一、准备json数据
在实际的生产环境中,我们分析数据最常见的数据源格式就是csv或者json格式的,在spark中提供了直接读取csv或者json格式的API,开箱即用。这里我们演示主要是以json的数据来进行演示,下面我们准备一份关于人员的json数据示例:
{"name":"田七","ic":"8cac0a02","id":"9999"}
{"name":"赵六","ic":"4231543","id":"4","url":"/storage/emulated/0/HPTC/HPTFace/4.jpg"}
{"name":"王五","ic":"53124","id":"3","url":"/storage/emulated/0/HPTC/HPTFace/3.jpg"}
{"name":"李四","ic":"41235","id":"2"}
{"name":"张三","ic":"5432","id":"1","url":"/storage/emulated/0/HPTC/HPTFace/1.jpg"}二、创建maven项目,并且引入依赖信息
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>三、编写spark sql的应用程序示例
package org.example
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object StudentCal {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().config(new SparkConf()).master("local[*]").appName("StudentCal").getOrCreate()
val dataframeRdd = session.read.json("hdfs://43.134.170.235:9000/usersource/user.txt")
//这里使用show来查看dataframe的信息
dataframeRdd.show();
dataframeRdd.where("id > 5").show()
dataframeRdd.where("id > 5").write.format("csv").save("hdfs://43.134.170.235:9000/usersql")
}
}最后我们运行下看下效果。
备注:
1、在前面我们介绍了dataframe可以看作是mysql的表,这里我们自爱上面使用了dataframeRdd.show来查看下dataframe的数据结构具体是一个什么样例,如图:
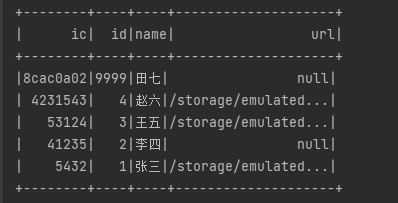
是不是和关系型数据库的表是一样的。
2、在sparksql中提供了现成的读取json数据格式的api,我们直接使用即可:
val dataframeRdd = session.read.json("hdfs://43.134.170.235:9000/usersource/user.txt")3、spark sql把数据读取进来之后会转换成dataframe格式的数据结构,此时我们可以直接像操作关系型数据库的表一样的操作,例如我们查询的时候添加where条件:
dataframeRdd.where("id > 5").show()4、根据spark的整体的3大块组成部分:数据源、transformation、写出数据,在最后一步里面,我们可以直接把dataframe数据写到对应的存储系统里面去。
dataframeRdd.where("id > 5").write.format("csv").save("hdfs://43.134.170.235:9000/usersql")5、从上面的案例来说,我们可以看到使用spark sql成功的为我们减少了开发代码量(也就是不用像之前的初级步骤对rdd做各种操作)。同时我们对于业务的处理可以使用我们最熟悉的sql的方式来进行处理,总体来说简单,明了。








还没有评论,来说两句吧...