
本文我们来演示下Druid伪集群的安装。
前置说明
在部署安装druid的时候,一般我们还是建议使用集群的方式进行安装,这样可以做到存算分离,在druid进行安装的时候从大体上主要分为3类节点,分别是:
1、master节点 2、query节点 3、store节点
从上诉的节点区别,我们就能很好的明白为什么这里是存算分离,query节点负责查询及计算,store节点主要负责存储,master节点统管集群元数据信息。所以在实际部署的时候,我们也能根据节点信息来规划整个集群的服务器配置信息。
部署安装
接下来我们就来演示下在单机节点上部署Druid伪集群的案例。直接开始:
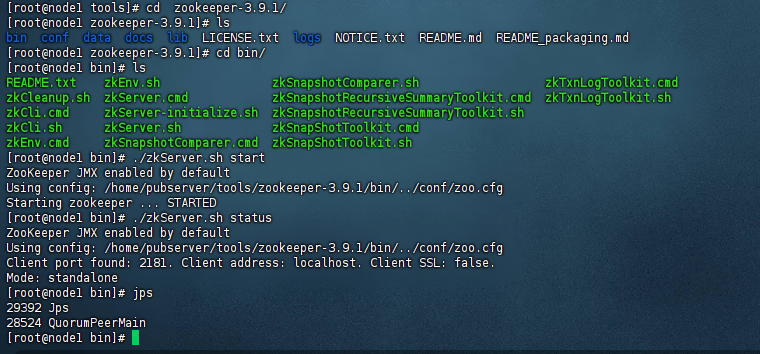
1)部署zookeeper
这里我们在生产上建议还是部署一个zookeeper集群,至少3个节点。这里我们演示环境主要是部署一个单机版本的zookeeper,示例图如下:
2)部署hdfs
这里我们是需要把druid的数据存储在hdfs上的,所以这里的话,我们需要启动hadoop集群,这里我们已经启动好了,示例图如下:
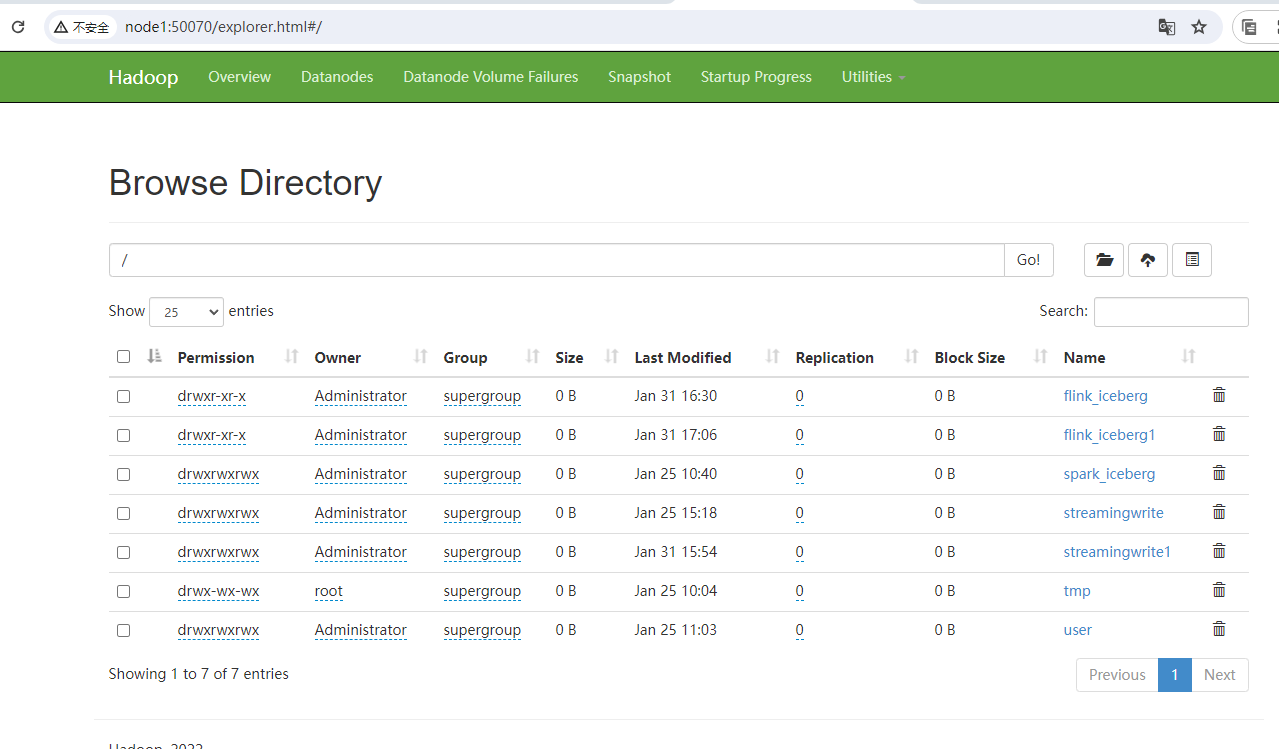
这里其实只需要启动hdfs集群就可以了,如果没有mr的要求,可以不启动m的部分。
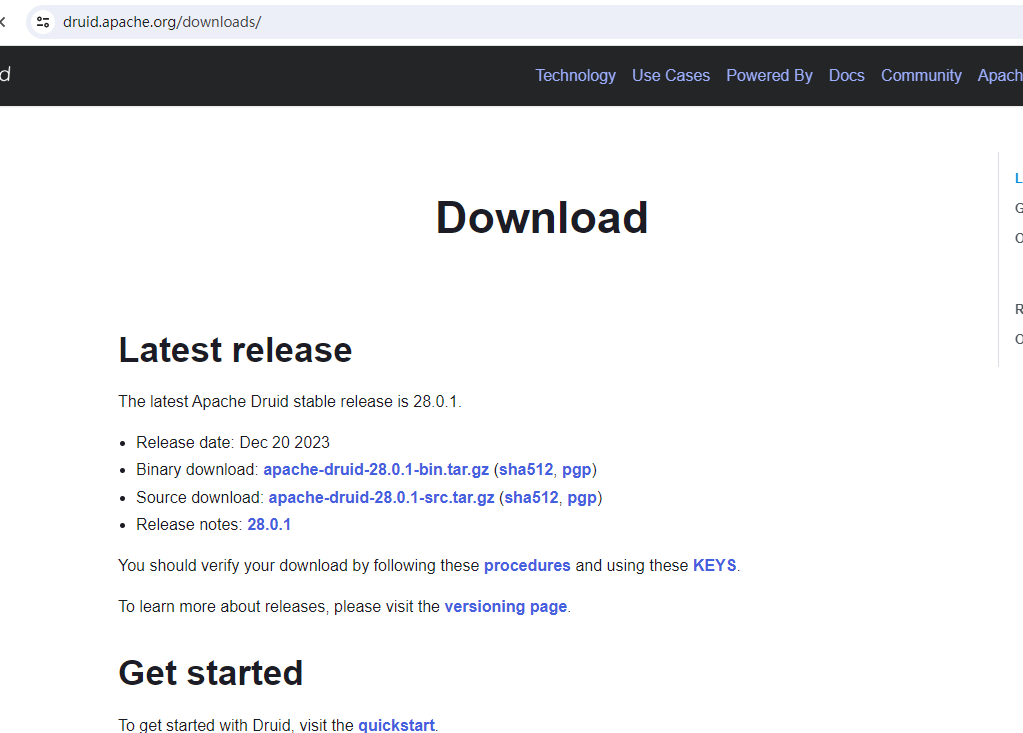
3)下载druid
接着我们从Apache Druid官网下载最新版本的Druid即可,这里我们目前最新的版本是28.0.1,示例图如下:
我们给下载下来,然后进行上传到服务器上即可:
3)配置runtime
首先我们来配置runtime的信息,这里主要是配置一些外部组件的信息,直接开始
进入到${druid_home}/conf/druid/cluster/_common目录,可以看到有一个common.runtime.properties的文件,示例图如下:

接着我们开始编辑这个common.runtime.properties文件。
首先添加外部mysql元数据存储,添加mysql-metadata-storage扩展,修改后示例如下:
druid.extensions.loadList=["druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches", "druid-multi-stage-query", "mysql-metadata-storage"]
接着配置master节点信息:
# # Hostname 这里的hostname为当前服务器节点的别称,后续如果分发到不同的机器,那么这里的host也要修改为当前服务器对应的节点别称,注意这里很重要/注意这里很重要/注意这里很重要 # druid.host=node1
接着配置zookeeper节点信息:
# # Zookeeper # druid.zk.service.host=node1:2181 druid.zk.paths.base=/druid
接着配置mysql的信息,首先把storage.type=derby部分给注释掉,然后打开mysql部分进行配置,示例图如下:
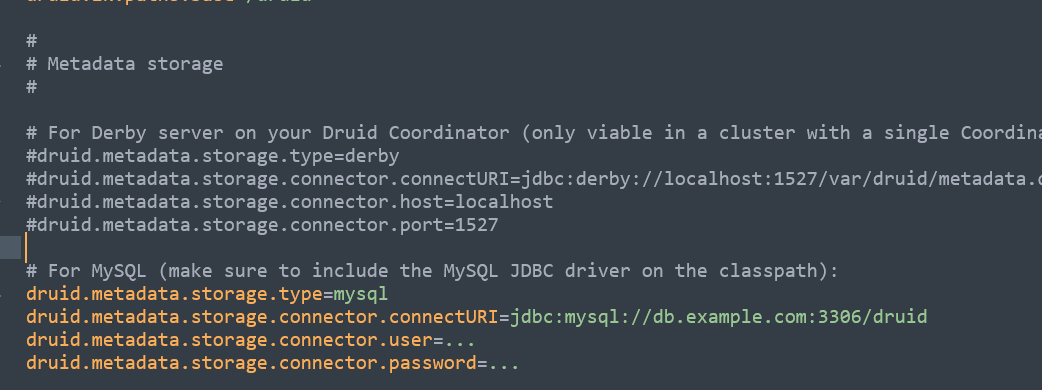
修改后的配置如下:
# For MySQL (make sure to include the MySQL JDBC driver on the classpath): druid.metadata.storage.type=mysql druid.metadata.storage.connector.connectURI=jdbc:mysql://192.168.31.30:3306/test50 druid.metadata.storage.connector.user=test50 druid.metadata.storage.connector.password=jrHLhGdZKTrBLxdc
备注:
1、此时我们只是配置,还没有去初始化mysql,所以对应的test50这个库是空的
接着配置hdfs的存储部分,首先我们把logs.type=file这一部分给注释掉,然后打开logs.type=hdfs,示例图如下:
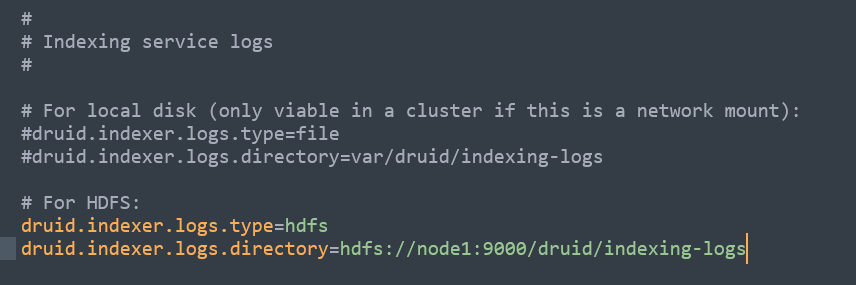
接着我们修改Deep storage部分,同样的我们把storage.type=local注释掉,然后打开storage.type=hdfs,示例图如下:
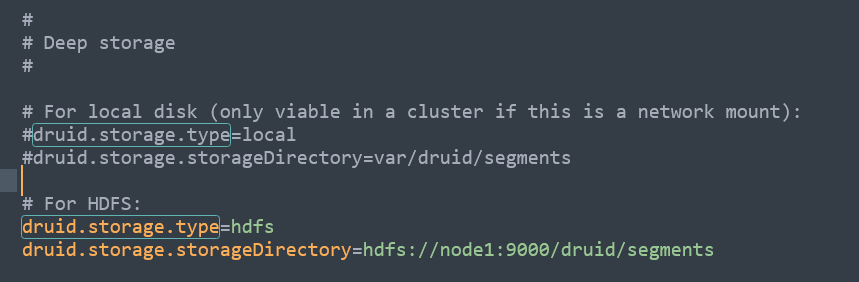
以上我们的runtime部分就配置完了。注意上诉配置不管是master节点,还是query节点,还是data节点都配置一下。
4)配置内存部分
内存部分会涉及到各个节点的配置文件,下面咱们直接列举出来:
修改master节点的jvm,配置文件是:${druid_home}/conf/druid/cluster/master/coordinator-overlord/jvm.config,修改内容如下:
-Xms8g -Xmx8g
这里最新版本的druid默认是15g,一般我们根据情况进行调整,设置为8g即可:
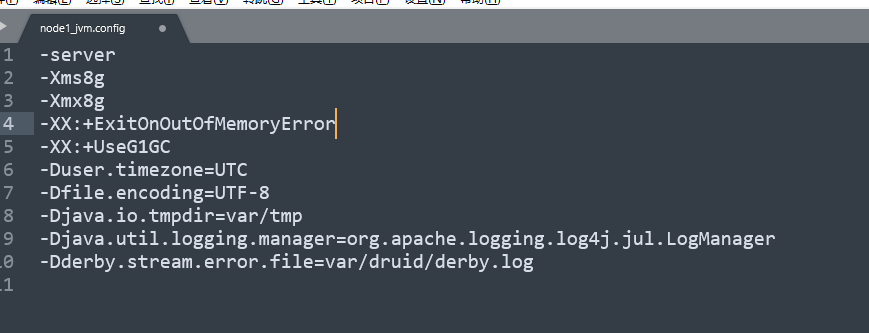
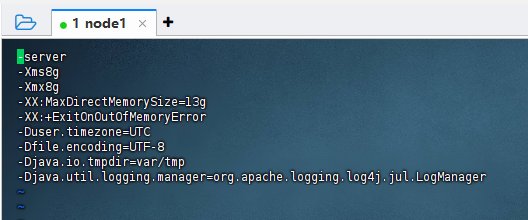
修改store节点的jvm,配置文件是:${druid_home}/conf/druid/cluster/data/historical/jvm.config,修改内容如下:
-Xms8g -Xmx8g
这里最新版本的druid默认是8g,一般我们还是根据实际情况进行调整即可,例如16g等信息,这里我们演示环境保持8G不变。
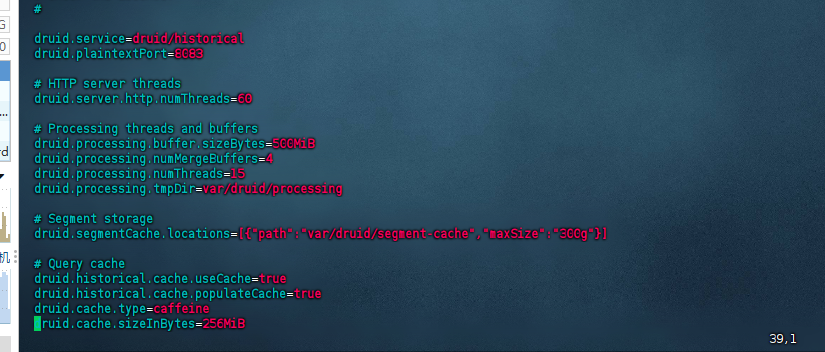
修改store节点的缓存块,配置文件是:${druid_home}/conf/druid/cluster/data/historical/runtime.properties,修改的内容是:
druid.processing.buffer.sizeBytes=500MiB druid.cache.sizeInBytes=256MiB
这两个值默认是上诉的500m和256m,可以根据实际情况进行调整即可,但是一般默认的这个值已经够用,所以也可以不调整,所以这里我们不调整:
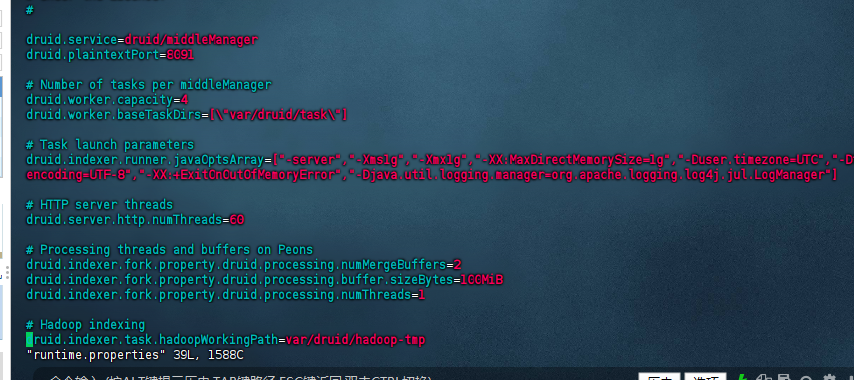
修改store节点的middlemanager的缓存块,配置文件是:${druid_home}/conf/druid/cluster/data/middleManager/runtime.properties,修改的内容是:
druid.indexer.fork.property.druid.processing.buffer.sizeBytes=100MiB
这里其实默认也是够用的,根据实际情况进行调整即可。
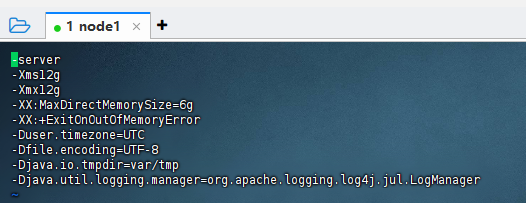
修改query节点的jvm,配置文件是:${druid_home}/conf/druid/cluster/query/broker/jvm.config,修改的内容主要是:
-Xms12g -Xmx12g -XX:MaxDirectMemorySize=6g
注意这里的query节点的服务器配置,内存和cpu一定要尽量高配。
修改query节点的缓存块,配置文件是:${druid_home}/conf/druid/cluster/query/broker/runtime.properties,修改的内容主要是:
druid.processing.buffer.sizeBytes=500MiB
这里的大小根据实际的数据量和业务查询情况进行调整即可。
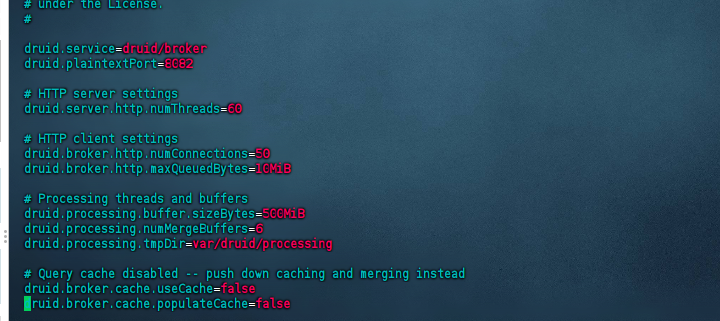
修改query节点的路由jvm,配置文件是:${druid_home}/conf/druid/cluster/query/router/jvm.config,修改的内容主要是:
-Xms1g -Xmx1g
这里的内存要求不高,实际情况在不满足的时候再进行调整即可。

5)添加mysql驱动
上面我们配置了需要把druid的元数据存储在mysql中,所以这里我们需要把mysql的jdbc驱动下载下来,放到druid的对应目录:${druid_home}/extensions/mysql-metadata-storage/目录下,这里我已经放进来了:
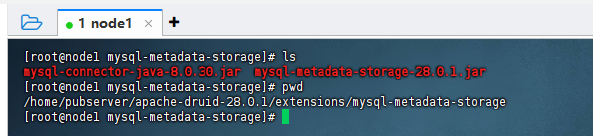
6)添加hadoop配置
这里我们还需要添加hadoop的配置信息,所以我们在${druid_home}/conf/druid/cluster/_common/目录下创建一个名称为hadoop-xml的文件夹,然后把hadoop的core-site.xml文件和hdfs-site.xml文件拷贝到这个目录里面来:

7)分发包
到这里我们的druid相关的配置就配置完毕了,接着我们把当前配置的${druid_home}整个文件夹分发拷贝到各个服务器节点上去(此处演示环境省略掉)
8)启动服务
到这里我们就可以启动druid服务了,这里需要到对应的服务器上启动不同的节点。
master节点启动服务(需要在mater节点的服务器上操作)
#进入到bin目录
cd ${druid_home}/bin
#执行启动
nohup ./start-cluster-master-with-zk-server > /home/pubserver/apache-druid-28.0.1/log/start-cluster-master-with-zk-server.log 2>&1 &query节点启动服务(需要在query节点的服务器上操作)
#进入到bin目录
cd ${druid_home}/bin
#执行启动
nohup ./start-cluster-query-server > /home/pubserver/apache-druid-28.0.1/log/start-cluster-query-server.log 2>&1 &store节点启动服务(需要在data节点的服务器上操作)
#进入到bin目录
cd ${druid_home}/bin
#执行启动
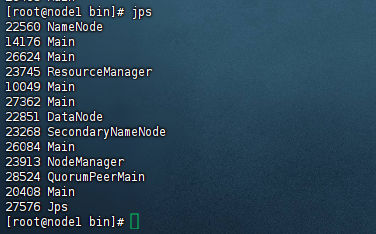
nohup ./start-cluster-data-server > /home/pubserver/apache-druid-28.0.1/log/start-cluster-data-server.log 2>&1 &启动之后就可以看到很多个对应的main进程,示例图如下:
接着我们访问下druid的web ui,访问地址是:node1:8888,访问后示例效果图如下:
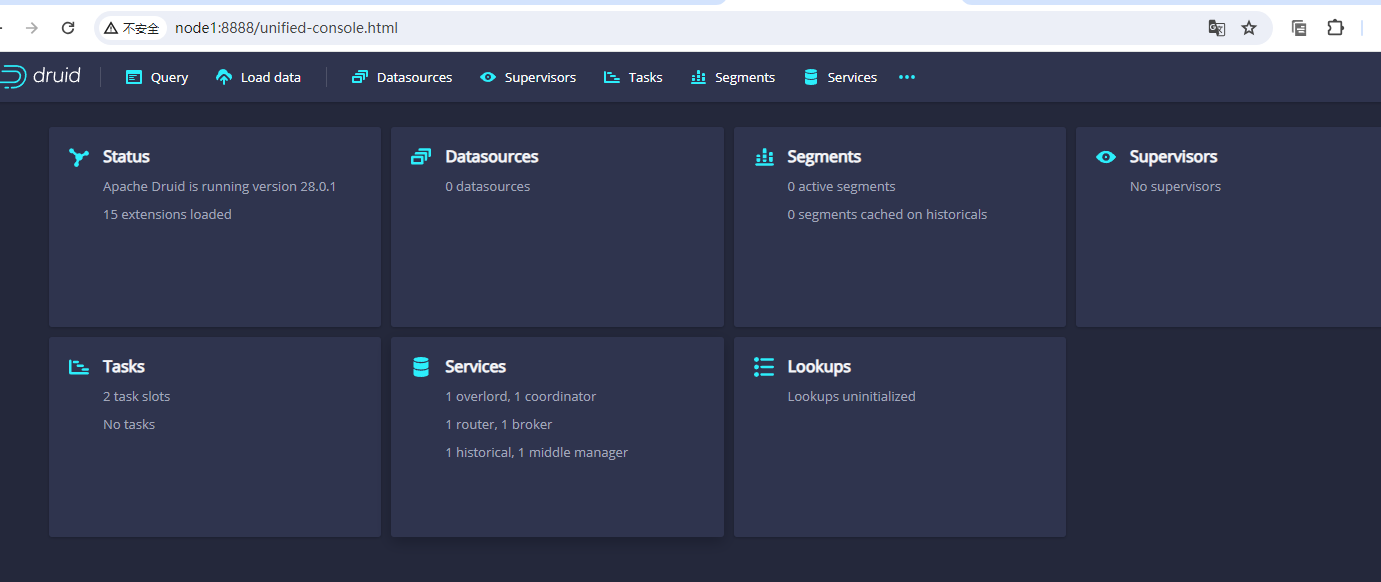
到这里说明我们的druid按照部署是成功的。
备注:
1、这里我们使用单机启动3服务会出现报错,详情可参考《启动apache druid的时候报错,提示:Cannot lock svdir, maybe another 'supervise' is running》解决,如果不是单机启动3服务,则不会出现这个问题。
2、启动durid服务对服务器的要求比较高,尽量选择16H,64G的配置来使用,低配启动起来之后会非常卡,服务器带动不起来。如果服务器配置太低,可以使用演示环境,详情可参考:《Druid演示环境》








还没有评论,来说两句吧...