
这篇文章我们继续开启Flink流处理的实战环节,这篇文章我们利用Flink的CEP复杂事件来实现用户登录的风控预警。
首先简要的介绍下CEP,CEP可以看做是flink中专门用于处理复杂事件的规则触发器,他的执行流程是:
(1)定义一个匹配规则 (2)将匹配规则应用到事件流上,检测满足规则的复杂事件 (3)对检测到的复杂事件进行处理,得到结果进行输出
因此,在使用CEP复杂事件的时候我们一定要有以下几个要素:
1、需要一个flink源源不断的流输入。 2、需要定义一个规则 3、把这个规则和流匹配起来。 4、从规则和流匹配结果里面提取最终的结果。
明白了上面这4个要素,接下来我们就知道怎么去做了。以下开始我们的案例。
背景说明
这里的背景就是在实际业务中,前端进行埋点,用户登录之后,把登录的结果写成一条条日志,然后通过埋点的接收器,把日志发送到kafka中。后台的flink流计算运行起来之后,源源不断的从kafka里面获取数据,再匹配规则(我们定义的规则是:同一个用户一段时间内登录失败超过3次则把当前用户进行封禁5分组,让其5分钟后再进行登录)。
代码案例
一、首先定义一个日志的数据结构
这里我们定义一个loginAction的数据结构,完整代码如下:
package com.flink.demo.model;
import java.io.Serializable;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode
@ToString
@Builder
public class LoginActionPoJo implements Serializable {
/**
*
*/
private static final long serialVersionUID = -5515536149853072974L;
// 登录用户的用户名
private String userName;
// 登录用户的ip地址
private String ip;
// 本次登录的结果,成功或者失败
private String loginResult;
// 本次登录时间
private Long loginTime;
}二、定义flink kafka connector的流
这里flink需要一直从kafka中源源不断的获取数据,同时我们把获取的数据直接转换成loginaction对象,代码示例如下:
package com.flink.demo.stream;
import java.util.Properties;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import com.flink.demo.model.LoginActionPoJo;
import com.flink.demo.utils.TransformUtil;
public class LoginEventStream {
public static DataStream<LoginActionPoJo> getLoginEventStream(Properties props, StreamExecutionEnvironment env) {
@SuppressWarnings("deprecation")
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>("login_logs", new SimpleStringSchema(),
props);
// 设置checkpoint后在提交offset,即oncheckpoint模式
consumer.setCommitOffsetsOnCheckpoints(true);
// 消费者组最近一次提交的偏移量,默认。
consumer.setStartFromGroupOffsets();
// 接收kafka的数据
DataStreamSource<String> source = env.addSource(consumer);
// 3.转换为指定格式
DataStream<LoginActionPoJo> loginModels = source.map(rawData -> {
return TransformUtil.formatLoginPoJo(rawData);
});
return loginModels;
}
}这里转换的utils是:
package com.flink.demo.utils;
import org.apache.commons.lang3.StringUtils;
import com.alibaba.fastjson.JSON;
import com.flink.demo.model.LoginActionPoJo;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class TransformUtil {
/**
* 这里我们把json直接转换成model 对象
* @param rawData
* @return
*/
public static LoginActionPoJo formatLoginPoJo(String rawData) {
try {
if (StringUtils.isNotBlank(rawData)) {
return JSON.parseObject(rawData, LoginActionPoJo.class);
}
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return null;
}
}三、定义一个规则:三次登录失败的规则
上面提到使用CEP复杂事件处理,我们需要有一个规则,这里定义规则的代码如下:
// 定义cep规则,这里我们拟定接收的3次数据都是fail状态,把他提取出来。
Pattern<LoginActionPoJo, LoginActionPoJo> pattern = Pattern.<LoginActionPoJo>begin("first") // 以第一个登录失败事件开始
.where(new SimpleCondition<LoginActionPoJo>() {
private static final long serialVersionUID = 1L;
@Override
public boolean filter(LoginActionPoJo loginEvent) throws Exception {
return "fail".equals(loginEvent.getLoginResult());
}
}).next("second") // 接着是第二个登录失败事件
.where(new SimpleCondition<LoginActionPoJo>() {
private static final long serialVersionUID = 1L;
@Override
public boolean filter(LoginActionPoJo loginEvent) throws Exception {
return "fail".equals(loginEvent.getLoginResult());
}
}).next("third") // 接着是第三个登录失败事件
.where(new SimpleCondition<LoginActionPoJo>() {
private static final long serialVersionUID = 1L;
@Override
public boolean filter(LoginActionPoJo loginEvent) throws Exception {
return "fail".equals(loginEvent.getLoginResult());
}
});四、把规则和数据流合并匹配起来
使用CEP的pattern函数把规则和流匹配起来
PatternStream<LoginActionPoJo> patternStream = CEP.pattern(stream, pattern);
五、从结果中筛选出需要预警的数据
当流和规则匹配起来后,有数据流入就会进行匹配,匹配完毕后会单独返回匹配的数据,完整代码如下:
patternStream.select(new PatternSelectFunction<LoginActionPoJo, String>() {
private static final long serialVersionUID = 1L;
@Override
public String select(Map<String, List<LoginActionPoJo>> map) throws Exception {
LoginActionPoJo first = map.get("first").get(0);
LoginActionPoJo second = map.get("second").get(0);
LoginActionPoJo third = map.get("third").get(0);
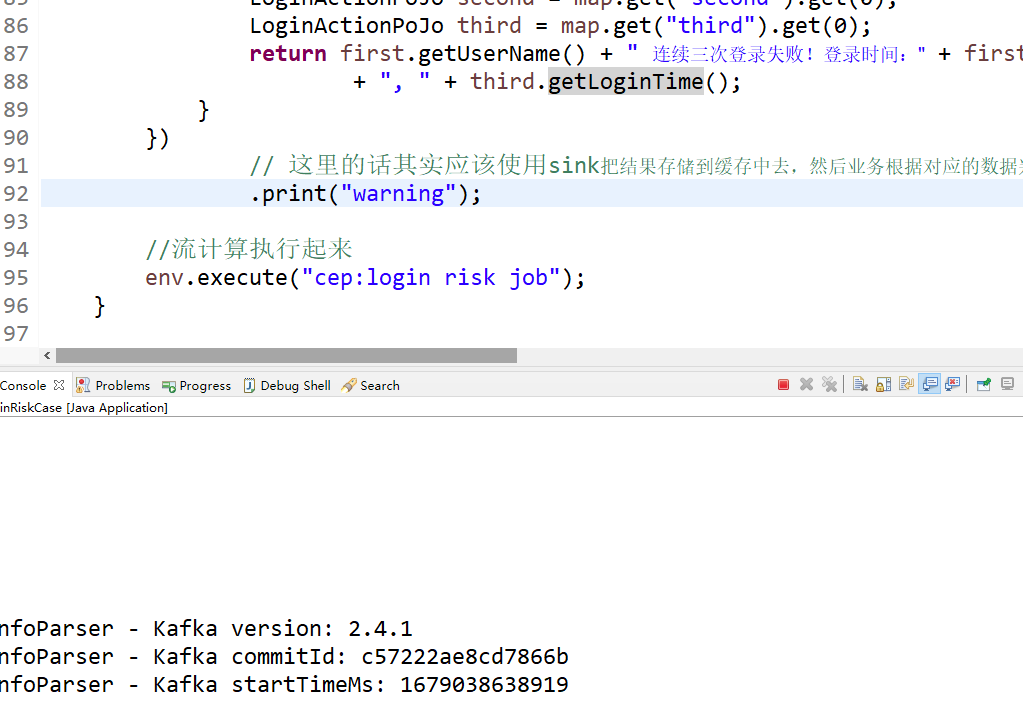
return first.getUserName() + " 连续三次登录失败!登录时间:" + first.getLoginTime() + ", " + second.getLoginTime()
+ ", " + third.getLoginTime();
}
})
// 这里的话其实应该使用sink把结果存储到缓存中去,然后业务根据对应的数据判断,暂时不让用户进行登录。为了演示,我们这里只做打印处理
.print("warning");以上我们就完成了flink的CEP实践处理,实现匹配用户的登录,达到登录失败3次就封禁用户5分钟的效果。
六、编写kafkaproducer。模拟发送日志
这里由于是演示,因此这里我们没有前端埋点,只能自己写kafka producer进行数据模拟了,完整代码示例如下:
package com.kafka.test;
import java.util.Properties;
import java.util.Random;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import com.alibaba.fastjson.JSON;
import com.flink.demo.model.LoginActionPoJo;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class FlinkKafkaProducer {
private static final String[] usernames = new String[] { "admin", "zhangsan", "lisi", "wangwu", "zhaoliu",
"tianqi" };
private static final Random RANDOM = new Random();
private static final String TOPIC = "login_logs";
private static final String BROKER_LIST = "192.168.31.20:9092";
/**
* 消息发送确认 0,只要消息提交到消息缓冲,就视为消息发送成功 1,只要消息发送到分区Leader且写入磁盘,就视为消息发送成功
* all,消息发送到分区Leader且写入磁盘,同时其他副本分区也同步到磁盘,才视为消息发送成功
*/
private static final String ACKS_CONFIG = "1";
/**
* 缓存消息数达到此数值后批量提交
*/
private static final String BATCH_SIZE_CONFIG = "1000";
private static KafkaProducer<String, String> producer;
static {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_LIST);
properties.setProperty(ProducerConfig.ACKS_CONFIG, ACKS_CONFIG);
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, BATCH_SIZE_CONFIG);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<String, String>(properties);
}
public void send() {
try {
int i = 0;
while (i < 50) {
LoginActionPoJo loginActionLog = this.createLoginAction();
// 等待启动日志打印完后再发送消息
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, JSON.toJSONString(loginActionLog));
producer.send(record, (recordMetadata, e) -> {
if (e != null) {
System.out.println("发送消息异常!");
}
if (recordMetadata != null) {
// topic 下可以有多个分区,每个分区的消费者维护一个 offset
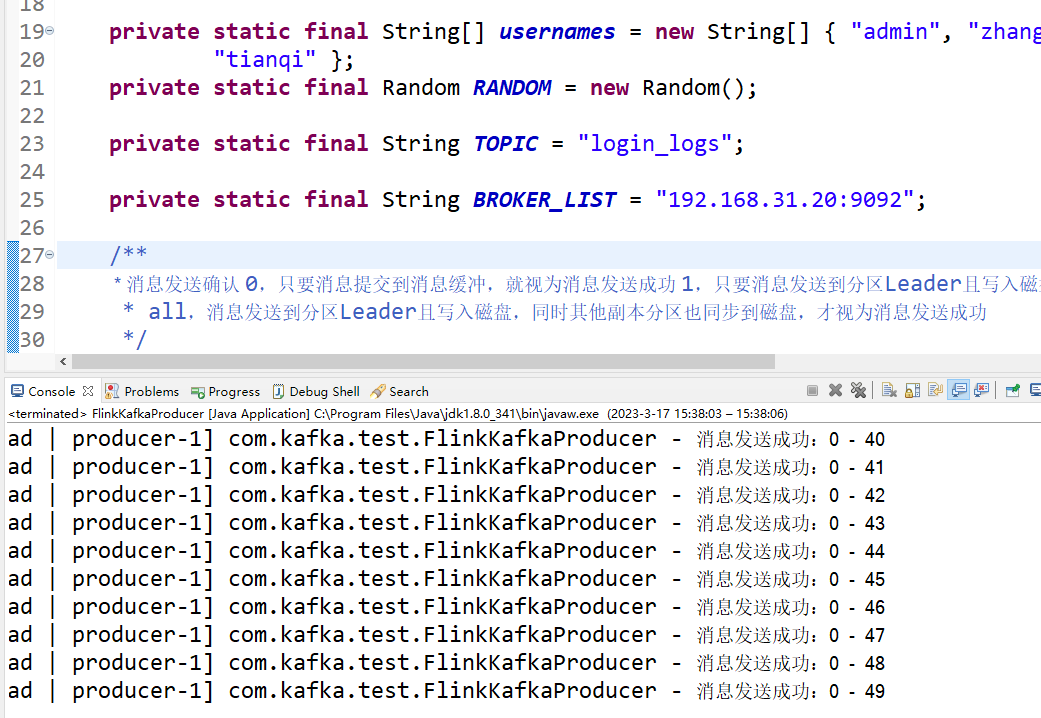
log.info("消息发送成功:{} - {}", recordMetadata.partition(), recordMetadata.offset());
}
});
i++;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != producer) {
producer.close();
}
}
}
public static void main(String[] args) {
FlinkKafkaProducer flinkKafkaProducer = new FlinkKafkaProducer();
flinkKafkaProducer.send();
}
private LoginActionPoJo createLoginAction() {
LoginActionPoJo loginAction = LoginActionPoJo.builder()
.userName(usernames[RANDOM.nextInt(usernames.length-1)]).ip("192.168.31.50")
.loginResult(RANDOM.nextInt(10) < 6 ? "fail" : "success").loginTime(System.currentTimeMillis()).build();
return loginAction;
}
}七、测试结果
上面所有的代码都完成了,接下来我们测试下效果怎么样,首先运气起来flink job
然后我们再运行kafka producer工具类
然后我们看下flink job的日志输出:
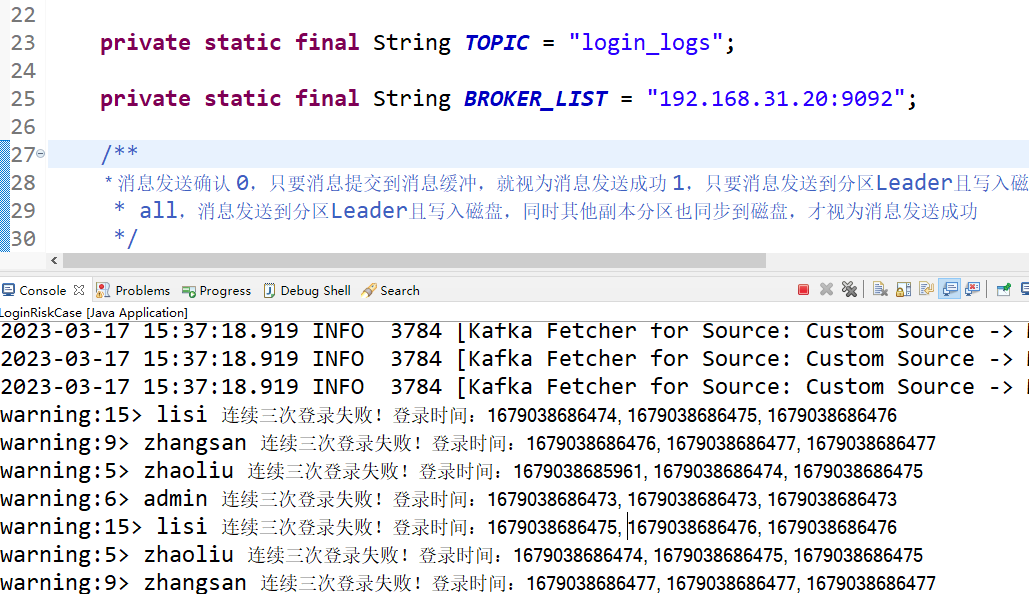
可以看到实现了flink的流处理CEP复杂事件。
备注:
1、水位线这里使用的是最大实践时间,因此我们这里事件是满足登录失败3次,算作一次时间,因此这里的窗口时间是不固定的,如下图:
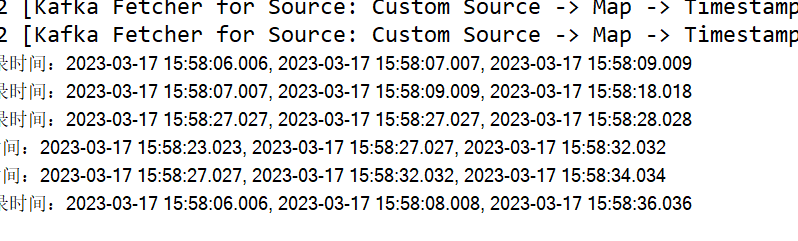
可以看到这里的结果有的间隔是3秒钟,有的间隔是30多秒,因此时间是不固定的,主要是事件来驱动,所以计算的是事件事件。
最后按照惯例,附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...