
前面我们介绍过iceberg的信息,本文我们进入实战案例,就是结合Iceberg+hive整合方案,实现hive入湖和查湖。下面直接开始。
一、首先部署hadoop和hive
看过前几篇文章的同学可以知道,这里其实我们已经实现了hadoop和hive的部署,hive是依赖hadoop的,同时hive我们需要开启hiveserver2的服务,方便可以使用thrift进行访问。示例图如下:
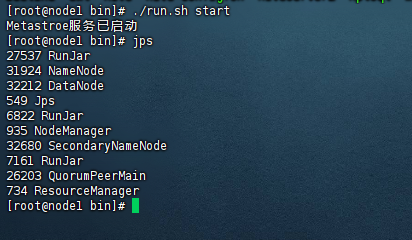
二、hive添加iceberg依赖
接着我们需要在hive中添加iceberg的依赖,这个依赖主要是hive的iceberg runtime的jar包,这个jar包在iceberg的官网里面下载即可,示例图如下:
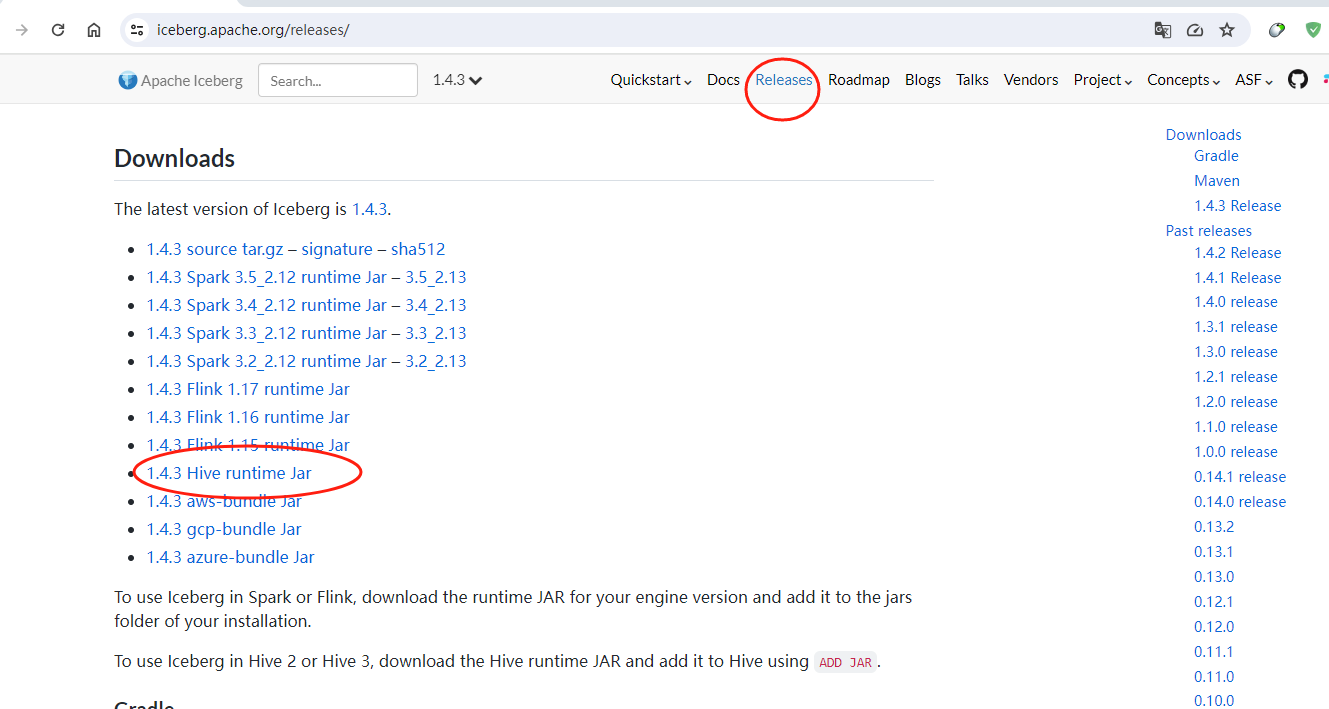
下载完iceberg runtime的jar包之后,我们把jar放到hive的lib目录里面去,具体的目录如下:${HIVE_HOME}/lib,示例图如下:
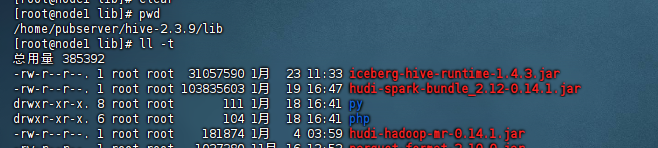
三、配置hive-site.xml
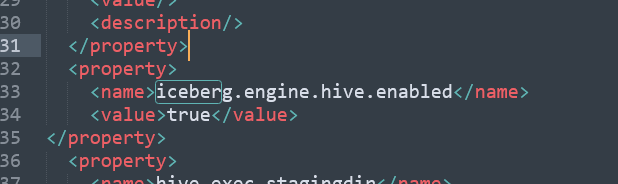
接着我们还需要在hive-site.xml里面配置启用iceberg,具体需要添加的配置信息如下:
<property> <name>iceberg.engine.hive.enabled</name> <value>true</value> </property>
示例图如下:
然后我们把hive重新启动一下。
四、测试创建表
经过前面三个步骤我们就完成了hive配置iceberg的所有信息,到这里我们就可以直接使用了。所以这里我们直接在hive里面创建以下iceberg的表。这里还是使用Hue进行演示,创建表的示例语句如下:
create table users2(
id int,
name string,
age int
)
partitioned by (dt string)
stored by 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
tblproperties ('iceberg.catalog'='iceberg_demo1');这里的整个语句核心点主要是3个,分别是:
1、注意使用分区 2、stored需要指定iceberg的格式 3、需要执行多数据源目录(指定iceberg,catalog)
是不是很简单,这里我们看看执行效果:
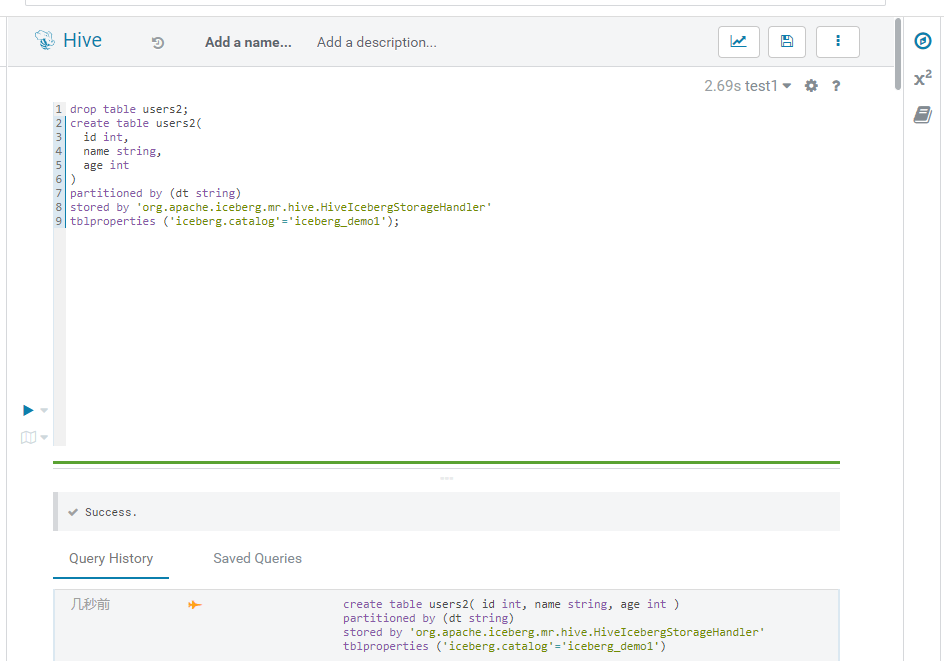
此时就执行成功了。接着我们使用hive的sql语句就可以查看导users2表被创建好了:
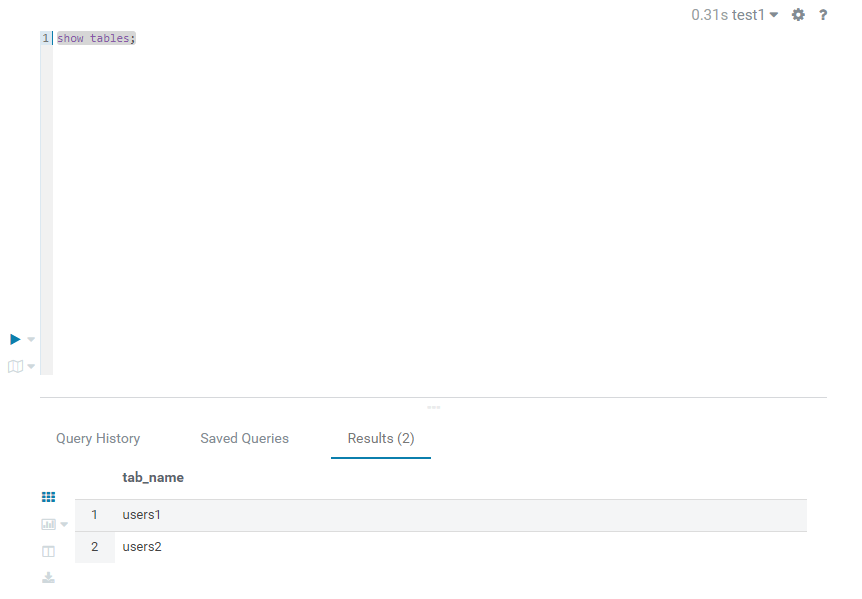
五、测试插入并查询数据
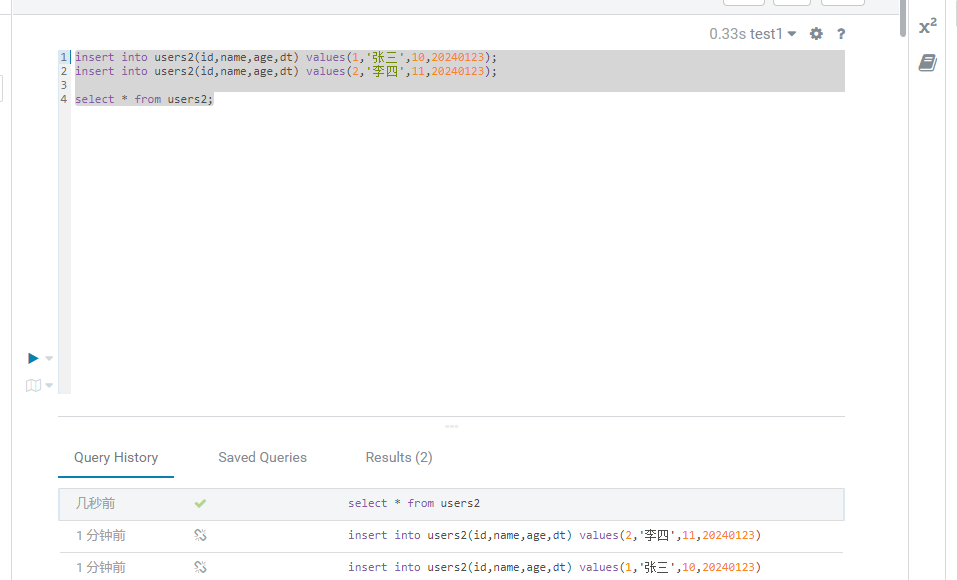
接着我们来执行相关的插入语句,也就是把数据插入导users2表里面去,这里的插入也更简单了,直接使用insert语句就可以了,示例如下:
insert into users2(id,name,age,dt) values(1,'张三',10,20240123); insert into users2(id,name,age,dt) values(2,'李四',11,20240123); select * from users2;
这里我们可以看到执行结果没有任何问题:
最后也能完全的查询出来相关的数据:
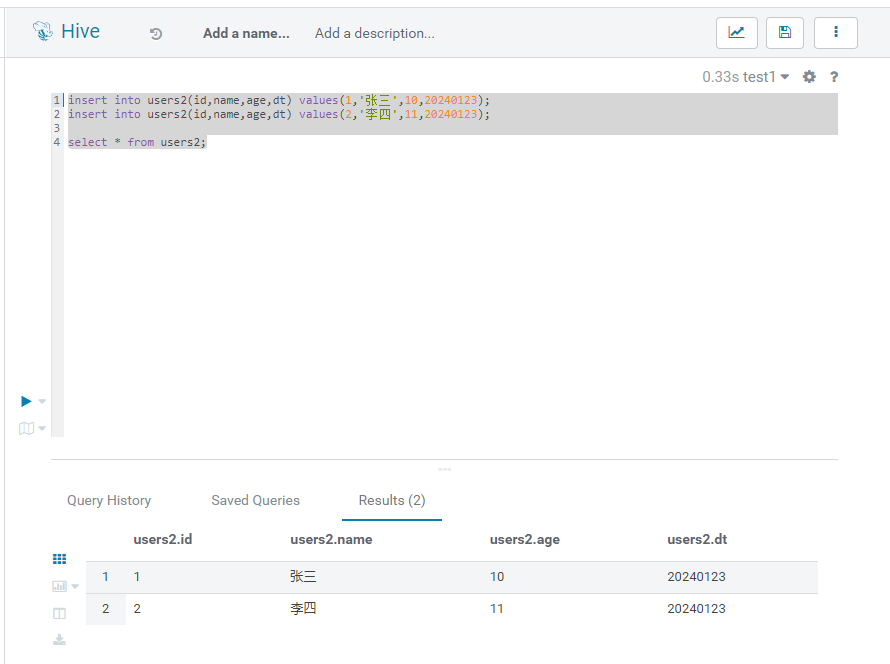
以上就是使用iceberg+hive整合hive表相关的使用案例。








还没有评论,来说两句吧...