
在日常的工作中,我们经常会涉及到调度系统,特别是在数据做ETL的时候,或者需要定时做某些操作的时候,这时候调度系统的需求就非常强烈。因此这里我们介绍下我们这边使用的分布式调度系统:Apache DolphinScheduler。
这个Apache DolphinScheduler分布式调度系统是中国人开发的,因此比较符合国内的使用习惯。根据Apache DolphinScheduler官网介绍如下:
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。 适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。 Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。 DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
这个分布式调度系统有如下特性:
简单易用
可视化 DAG: 用户友好的,通过拖拽定义工作流的,运行时控制工具 模块化操作: 模块化有助于轻松定制和维护。
丰富的使用场景
支持多种任务类型: 支持Shell、MR、Spark、SQL等10余种任务类型,支持跨语言,易于扩展 丰富的工作流操作: 工作流程可以定时、暂停、恢复和停止,便于维护和控制全局和本地参数。
高可靠性
高可靠性: 去中心化设计,确保稳定性。 原生 HA 任务队列支持,提供过载容错能力。 DolphinScheduler 能提供高度稳健的环境。
高扩展性
高扩展性: 支持多租户和在线资源管理。支持每天10万个数据任务的稳定运行。
这个软件支持如下的job任务:
Shell Sub_process Procedure Sql Spark Flink MapReduce Python Dependent http Datax Pigeon Sqoop Conditions Data_quality Switch SeaTunnel AmazonEMR Zepplin Jupyter K8s Mlflow Openmldb Dvc Dinky Sagemaker Chunjun Flink_stream Pytorch HiveCli
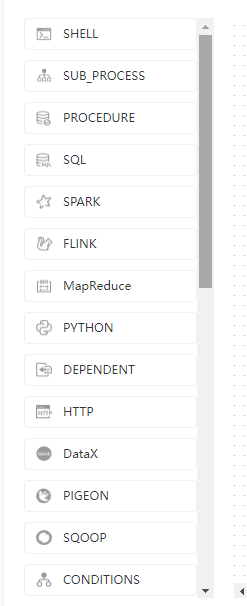
可以看出来,这个Apache DolphinScheduler支持的job任务类型还是比较多的,例如我们常见的:
shell spark sql datax mapreduce flink 等等
有时间的话,大家登录下看看即可,很容易就轻车熟路的上手。在接下来的文章里面,我们介绍下Apache DolphinScheduler几个常用的job 任务示例。








还没有评论,来说两句吧...